

هوش مصنوعی CS50 s5 فهرست مطالب
آموزش هوش مصنوعی
دوره کامل آموزش هوش مصنوعی بر مبنای دوره CS5 دانشگاه هاروارد به عنوان معتبرترین و جامع ترین دوره آموزش مقدماتی و مفهومی هوش مصنوعی شناخته می شود.
این دوره به بررسی دقیق و عمیق مباحث هوش مصنوعی به صورت پایه ای می پردازد و شامل 7 بخش میباشد .جهت دسترسی به سایر دوره ها می توانید از لینک های زیر استفاده نمایید.
و برای مشاهده لیست تمام دوره ها به بخش مقالات مراجه نمایید.
CS50’s Introduction to Artificial Intelligence with Python
Danix Ai
فهرست مطالب:
مقدمهای بر شبکههای عصبی
- الهام از نورونهای زیستی
- ساختار نورون مصنوعی و ورودی/وزن/بایاس
- تابع فرضیه و نقش وزنها
توابع فعالساز (Activation Functions)
- تابع پلهای (Step Function)
- تابع لوجستیک (Sigmoid)
- تابع ReLU
- نقش توابع فعالساز در تصمیمگیری
ساختار شبکههای عصبی
- نورونها و یالهای وزندار
- مثال منطقی OR و AND
- گسترش مدل برای ورودیهای پیوسته
- بردار وزن و بردار ورودی
گرادیان نزولی (Gradient Descent)
- ایدهٔ کلی کمینهسازی خطا
- گرادیان نزولی استاندارد
- گرادیان نزولی تصادفی (SGD)
- گرادیان نزولی دستهای کوچک (Mini-Batch)
- مثال کدنویسی با Numpy
شبکههای عصبی چندلایه (MLP)
- لایه ورودی، لایه خروجی، لایه مخفی
- نقش لایههای مخفی در مدلسازی غیرخطی
- مشکل دادههای غیرخطی و نیاز به MLP
پسانتشار خطا (Backpropagation)
- سازوکار انتشار خطا از خروجی به ورودی
- بروزرسانی وزنها در لایهها
- شکلگیری شبکههای عصبی عمیق
مشکل بیشبرازش (Overfitting)
- علت و پیامدهای بیشبرازش
- تکنیک Dropout
- تغییر ساختار شبکه حین آموزش
کتابخانه TensorFlow و Keras
- ساخت مدل Sequential
- لایههای Dense و ReLU
- سیگموید برای خروجی
- کامپایل و آموزش مدل
- مثال تشخیص اسکناس تقلبی
مقدمهای بر بینایی کامپیوتری
- ساختار پیکسلهای RGB
- چالشهای ورودی بزرگ
- از دست رفتن ساختار تصویری
کانولوشن تصویر (Image Convolution)
- تعریف کرنل و اعمال آن
- مثال محاسباتی کانولوشن
- تشخیص لبه با کرنلها
- نمونهٔ کدنویسی با PIL
Pooling
- هدف کاهش ابعاد
- Max Pooling و نمونهٔ تصویری
شبکههای عصبی کانولوشنی (CNNs)
- لایههای کانولوشن
- لایه MaxPooling
- Flatten و اتصال به شبکهٔ کلاسیک
- مثال پیادهسازی CNN روی MNIST
- ذخیره مدل
شبکههای عصبی بازگشتی (RNNs)
- تفاوت شبکههای Feed-Forward و RNN
- استفاده از خروجی شبکه بهعنوان ورودی
- کاربرد در Captioning
- کاربرد در ویدیو، ترجمه و دادههای توالیدار
مقدمه:
شبکههای عصبی مصنوعی یکی از بنیادیترین ابزارهای یادگیری ماشین و هستهٔ بسیاری از پیشرفتهای نوین هوش مصنوعی به شمار میآیند. الهامگرفته از سازوکار نورونهای زیستی، این شبکهها میکوشند الگوهای پنهان در دادهها را شناسایی کنند و به کمک ساختارهای لایهای، روابط پیچیده و غیرخطی را مدلسازی نمایند. از مسئلههای سادهٔ طبقهبندی تا تحلیل تصاویر، پردازش زبان و تصمیمگیریهای پیچیده، شبکههای عصبی نقشی تعیینکننده در توانایی یادگیری و تعمیم سیستمهای هوشمند دارند.
در این درس، ابتدا ساختار نورون مصنوعی و نحوهٔ محاسبهٔ خروجی آن بررسی میشود و سپس توابع فعالساز بهعنوان عناصر کلیدی در ایجاد رفتار غیرخطی معرفی میگردند. پس از آن، مفهوم گرادیان نزولی و فرایند یادگیری وزنها، بهعنوان قلب آموزش شبکهها، تشریح میشود. شبکههای چندلایه و سازوکار پسانتشار خطا، مسیر ایجاد شبکههای عمیق را هموار میکنند و امکان حل مسئلههایی را فراهم میسازند که روشهای خطی از عهدهٔ آنها برنمیآیند.
در ادامه، با چالشهایی نظیر بیشبرازش و راهکارهایی مانند Dropout آشنا میشویم و سپس با استفاده از کتابخانههای قدرتمند TensorFlow و Keras، نحوهٔ ساخت و آموزش مدلهای واقعی بررسی میشود. بخش پایانی درس به شبکههای کانولوشنی و بازگشتی اختصاص دارد؛ دو معماری مهم که به ترتیب در بینایی کامپیوتری و تحلیل توالیها نقشی محوری ایفا میکنند.
این درس تصویری جامع از مبانی، سازوکار و کاربردهای شبکههای عصبی ارائه میدهد و مسیر فهم عمیقتر یادگیری ماشین پیشرفته را هموار میسازد.
شبکههای عصبی:
شبکههای عصبی در هوش مصنوعی از علوم عصبشناسی الهام گرفتهاند. در مغز، نورونها سلولهایی هستند که به یکدیگر متصلاند و شبکههایی را تشکیل میدهند. هر نورون توانایی دریافت و ارسال سیگنالهای الکتریکی را دارد. وقتی ورودی الکتریکیای که نورون دریافت میکند از یک آستانه مشخص عبور کند، نورون فعال شده و سیگنال الکتریکی خود را به جلو میفرستد.
تصویر یک نورون مغزی را مشاهده می کنید.
هوش مصنوعی CS50 s5
یک شبکه عصبی مصنوعی مدلی ریاضی برای یادگیری است که از شبکههای عصبی زیستی الهام گرفته شده است. شبکههای عصبی مصنوعی توابع ریاضی را مدل میکنند که ورودیها را بر اساس ساختار و پارامترهای شبکه به خروجیها نگاشت میکنند. در شبکههای عصبی، ساختار شبکه از طریق آموزش بر روی دادهها شکل میگیرد.
وقتی این ساختار در هوش مصنوعی پیادهسازی میشود، معادل هر نورون یک واحد (unit) است که به واحدهای دیگر متصل میشود. برای مثال، مانند درس قبل، ممکن است هوش مصنوعی دو ورودی x₁ و x₂ را به این پرسش نگاشت کند که آیا امروز باران خواهد بارید یا نه. در درس قبل، برای این تابع فرضیه، شکل زیر را پیشنهاد کردیم:
w₀ + w₁x₁ + w₂x₂ = h(x₁, x₂)
که در آن w₁ و w₂ وزنهایی هستند که ورودیها را اصلاح میکنند، و w₀ یک ثابت (که بایاس نیز نامیده میشود) است که مقدار کل عبارت را تغییر میدهد.
توابع فعالساز (Activation Functions):
برای اینکه از تابع فرضیه برای تصمیمگیری در مورد باریدن باران استفاده کنیم، لازم است نوعی آستانه بر اساس مقدار خروجی آن ایجاد کنیم.
یکی از راهها استفاده از تابع پلهای (step function) است که پیش از رسیدن به یک آستانه مشخص مقدار ۰ و پس از عبور از آن مقدار ۱ تولید میکند.

راه دیگر برای انجام این کار استفاده از تابع لجستیک است؛ تابعی که خروجی آن هر عدد حقیقی بین ۰ تا ۱ است و بدین ترتیب میتواند میزان اطمینان درجهبندیشده را در تصمیم خود نشان دهد.
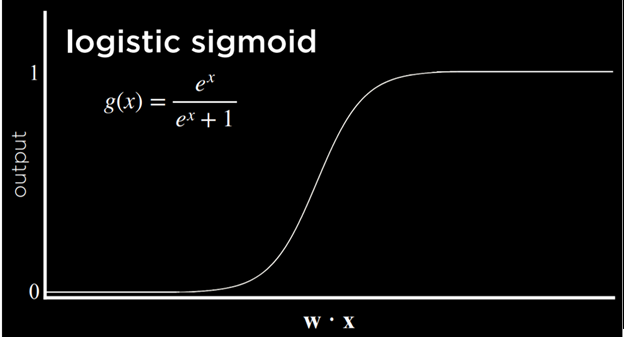
هوش مصنوعی CS50 s5
تابع ممکن دیگر واحد خطی اصلاحشده (ReLU) است که اجازه میدهد خروجی هر مقدار مثبت باشد. اگر مقدار منفی باشد، ReLU آن را برابر ۰ قرار میدهد.

صرفنظر از اینکه از کدام تابع استفاده کنیم، در درس قبل یاد گرفتیم که ورودیها علاوه بر بایاس، توسط وزنها اصلاح میشوند و مجموع آنها به یک تابع فعالساز داده میشود. این موضوع برای شبکههای عصبی ساده همچنان صدق میکند.
ساختار شبکه عصبی
شبکه عصبی را میتوان بهعنوان نمایش همین ایده در نظر گرفت؛ جایی که یک تابع، ورودیها را جمع میکند تا یک خروجی تولید کند.
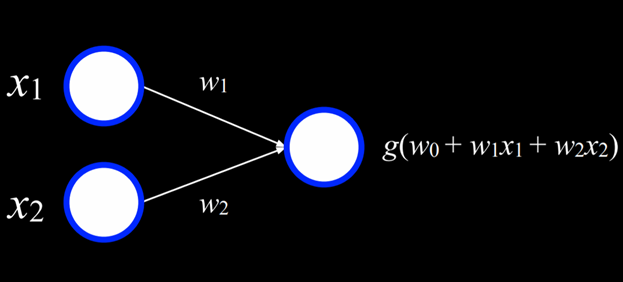
دو واحد سفید در سمت چپ ورودیها هستند و واحد سمت راست یک خروجی است. ورودیها از طریق یک یالِ وزندار به خروجی متصل شدهاند. برای تصمیمگیری، واحد خروجی، ورودیها را در وزنهایشان ضرب میکند و بایاس (w₀) را هم اضافه میکند، سپس از تابع g برای تعیین خروجی استفاده میکند.
برای مثال، یک اتصال منطقی OR را میتوان بهصورت یک تابع f با جدول درستی زیر نمایش داد:
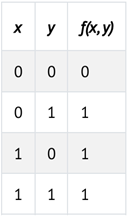
میتوانیم این تابع را بهصورت یک شبکه عصبی تجسم کنیم. x₁ یک واحد ورودی است و x₂ نیز واحد ورودی دیگر. این دو ورودی با یالی که وزن آن ۱ است به واحد خروجی متصل شدهاند. سپس واحد خروجی از تابع
g(-1 + 1x₁ + 2x₂) با آستانهٔ ۰ استفاده میکند تا خروجی را برابر ۰ یا ۱ (نادرست یا درست) قرار دهد.
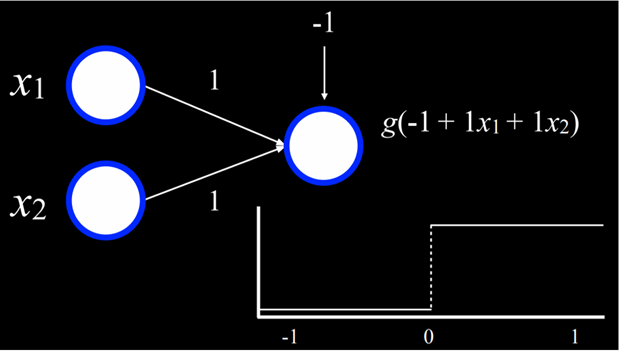
هوش مصنوعی CS50 s5
برای مثال، در حالتی که x₁ = x₂ = 0 باشد، مجموع برابر -1 است. این مقدار پایینتر از آستانه است، بنابراین تابع g خروجی ۰ خواهد داشت. با این حال، اگر یکی یا هر دو مقدار x₁ یا x₂ برابر با ۱ باشند، مجموع ورودیها برابر ۰ یا ۱ خواهد شد. هر دو مقدار در یا بالای آستانه هستند، پس تابع خروجی ۱ خواهد داشت.
یک فرآیند مشابه را میتوان برای تابع AND انجام داد (در این حالت بایاس برابر -2 خواهد بود). همچنین، ورودیها و خروجیها لازم نیست حتماً مقادیر باینری داشته باشند. میتوان از همان فرآیند برای ورودیهایی مانند رطوبت و فشار هوا استفاده کرد و احتمال بارش را بهعنوان خروجی محاسبه کرد. یا به عنوان مثال دیگر، ورودیها میتوانند میزان پول صرف شده برای تبلیغات و ماه صرف شدن آن باشند تا خروجی درآمد پیشبینیشده از فروش تولید شود. این روش را میتوان به هر تعداد ورودی گسترش داد؛ به این صورت که هر ورودی x1…xn را در وزن متناظر خود w1…wn ضرب کرده، مقادیر حاصل را جمع کنیم و بایاس w0 را اضافه کنیم.
گرادیان نزولی (Gradient Descent):
گرادیان نزولی الگوریتمی است برای کمینهسازی خطا (loss) هنگام آموزش شبکههای عصبی. همانطور که پیشتر گفته شد، شبکه عصبی قادر است از دادهها درباره ساختار خود دانش کسب کند. تا اینجا، ما وزنها را به صورت دستی تعریف میکردیم، اما شبکههای عصبی اجازه میدهند این وزنها بر اساس دادههای آموزشی محاسبه شوند. برای این کار از الگوریتم گرادیان نزولی استفاده میکنیم، که به شکل زیر عمل میکند:
- با یک انتخاب تصادفی وزنها شروع میکنیم. این نقطه شروع ساده ما است، جایی که نمیدانیم هر ورودی چقدر باید وزن داشته باشد.
- تکرار کنید:
- گرادیان را بر اساس تمام دادهها محاسبه کنید تا منجر به کاهش خطا شود. در نهایت، گرادیان یک بردار (یک دنباله از اعداد) است.
- وزنها را مطابق با گرادیان بهروزرسانی کنید.
مشکل این الگوریتم این است که نیاز دارد گرادیان را بر اساس تمام نقاط داده محاسبه کند، که از نظر محاسباتی هزینهبر است. روشهای متعددی برای کاهش این هزینه وجود دارد:
- در گرادیان نزولی تصادفی (Stochastic Gradient Descent)، گرادیان بر اساس یک نقطه تصادفی محاسبه میشود. این نوع گرادیان میتواند نسبتاً نادرست باشد.
- به همین دلیل (Mini-Batch Gradient Descent )ایجاد شد، که گرادیان را بر اساس چند نقطه انتخابشده تصادفی محاسبه میکند و میانبری بین هزینه محاسباتی و دقت ایجاد میکند.
همانطور که اغلب پیش میآید، هیچکدام از این روشها کامل نیستند و بسته به شرایط، روشهای مختلفی بهکار گرفته میشوند.
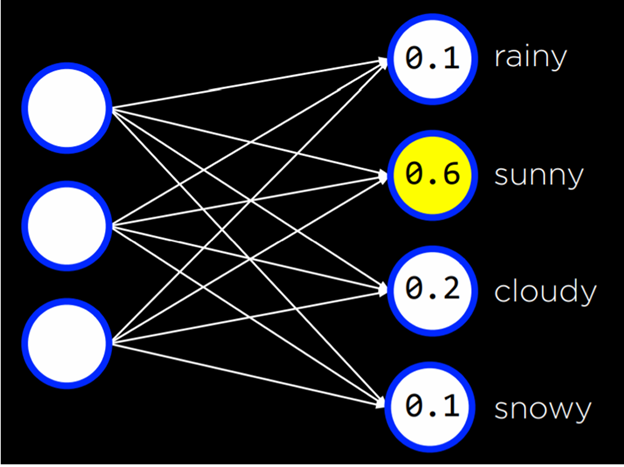
با استفاده از گرادیان نزولی میتوان به پاسخ بسیاری از مسائل دست یافت. برای مثال، ممکن است بخواهیم بیش از پاسخ ساده “آیا امروز باران میبارد؟” بدانیم. میتوانیم از ورودیها برای تولید احتمال انواع مختلف هوا استفاده کنیم و سپس نوع هوای با بیشترین احتمال را انتخاب کنیم.
فرض کنید یک شبکه عصبی داریم که دو ورودی x1,x2 دارد و قرار است یک خروجی باینری (0 یا 1) تولید کند. ما از تابع سیگموید (Sigmoid) به عنوان تابع فعالساز استفاده میکنیم، چون خروجی بین 0 و 1 است و میتوان آن را به احتمال تعبیر کرد.
import numpy as np
# تابع سیگموید و مشتق آن
def sigmoid(z):
return 1 / (1 + np.exp(-z))
def sigmoid_derivative(z):
return sigmoid(z) * (1 - sigmoid(z))
# دادههای آموزشی (x1, x2) و خروجی واقعی y
X = np.array([[0, 0],
[0, 1],
[1, 0],
[1, 1]])
y = np.array([[0], [1], [1], [1]]) # OR logic
# وزنها و بایاس اولیه (تصادفی)
np.random.seed(42)
weights = np.random.randn(2, 1)
bias = np.random.randn(1)
# نرخ یادگیری
learning_rate = 0.1
# گرادیان نزولی
for epoch in range(10000):
# محاسبه خروجی شبکه
z = np.dot(X, weights) + bias
output = sigmoid(z)
# محاسبه خطا
error = output - y
# محاسبه گرادیان
d_weights = np.dot(X.T, error * sigmoid_derivative(z)) / X.shape[0]
d_bias = np.mean(error * sigmoid_derivative(z))
# بروزرسانی وزنها و بایاس
weights -= learning_rate * d_weights
bias -= learning_rate * d_bias
# نمایش وزنها و پیشبینیها
print("وزنها بعد از آموزش:", weights.flatten())
print("بایاس بعد از آموزش:", bias)
print("خروجی پیشبینی شده:")
print(sigmoid(np.dot(X, weights) + bias))
توضیح:
- sigmoid(z) تابع فعالساز است که خروجی بین 0 و 1 میدهد.
- weights و bias با مقادیر تصادفی شروع میشوند.
- در هر epoch:
- خروجی شبکه محاسبه میشود
- خطا (Error) محاسبه میشود
- گرادیان وزنها و بایاس با استفاده از مشتق سیگموید محاسبه و وزنها بهروزرسانی میشوند
- بعد از آموزش، شبکه میتواند درست مانند یک تابع OR عمل کند.
هوش مصنوعی CS50 s5
این کار را میتوان با هر تعداد ورودی و خروجی انجام داد، بهطوری که هر ورودی به هر خروجی متصل باشد و خروجیها تصمیماتی را که میتوانیم بگیریم نمایش دهند. توجه داشته باشید که در این نوع شبکههای عصبی، خروجیها به یکدیگر متصل نیستند. این یعنی هر خروجی و وزنهای مرتبط با آن از تمام ورودیها میتواند بهعنوان یک شبکه عصبی مجزا در نظر گرفته شود و بنابراین میتوان آن را بهطور جداگانه از سایر خروجیها آموزش داد.
تا اینجا، شبکههای عصبی ما بر اساس واحدهای پرسپترون بودند. این واحدها تنها قادر به یادگیری مرز تصمیمگیری خطی هستند و از یک خط مستقیم برای جدا کردن دادهها استفاده میکنند. یعنی پرسپترون بر اساس یک معادله خطی میتواند ورودیها را به یک نوع یا نوع دیگر دستهبندی کند (مثلاً تصویر سمت چپ).
با این حال، اغلب دادهها به صورت خطی قابل جداسازی نیستند (مثلاً تصویر سمت راست). در این حالت، به شبکههای عصبی چندلایه (Multilayer Neural Networks) روی میآوریم تا بتوانیم دادهها را بهصورت غیرخطی مدل کنیم.
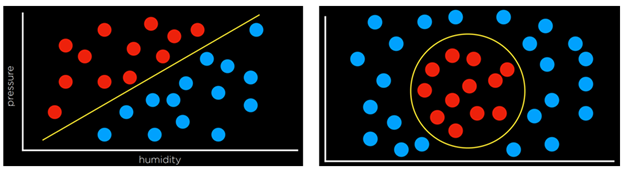
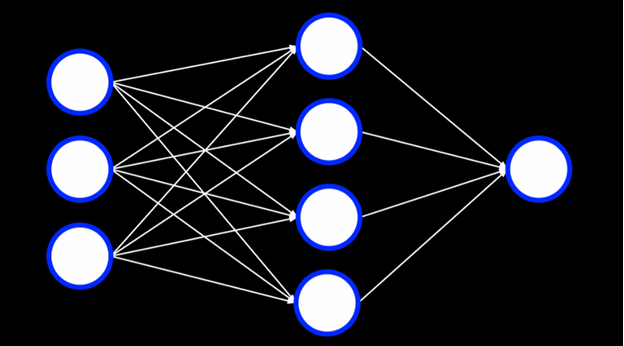
شبکههای عصبی چندلایه (Multilayer Neural Networks):
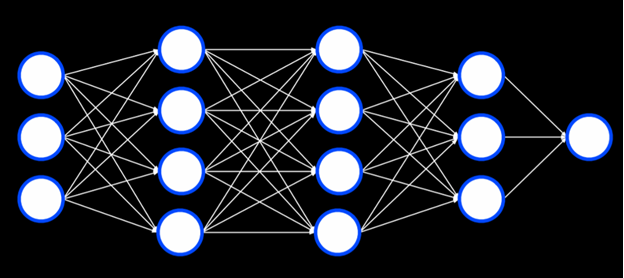
یک شبکه عصبی چندلایه، شبکهای مصنوعی است که شامل یک لایه ورودی، یک لایه خروجی و حداقل یک لایه مخفی است. در حالی که ما به شبکه ورودی و خروجی میدهیم تا مدل آموزش ببیند، ما انسانها مقادیر واحدهای داخل لایههای مخفی را مشخص نمیکنیم.
هر واحد در اولین لایه مخفی، مقدار وزنداری را از هر یک از واحدهای لایه ورودی دریافت میکند، روی آن عملی انجام میدهد و یک مقدار خروجی تولید میکند. هر یک از این مقادیر سپس وزندار شده و به لایه بعدی منتقل میشوند، و این فرآیند تا رسیدن به لایه خروجی ادامه مییابد.
وجود لایههای مخفی امکان مدلسازی دادههای غیرخطی را فراهم میکند.
پسانتشار خطا (Backpropagation):
پسانتشار خطا الگوریتم اصلی برای آموزش شبکههای عصبی با لایههای مخفی است. این الگوریتم با شروع از خطاهای واحدهای خروجی، گرادیان نزولی را برای وزنهای لایه قبلی محاسبه میکند و این فرآیند را تا رسیدن به لایه ورودی ادامه میدهد.
در شبهکد (pseudocode) میتوان الگوریتم را به شکل زیر توصیف کرد:
- محاسبه خطا برای لایه خروجی
- برای هر لایه، از لایه خروجی شروع کرده و به سمت اولین لایه مخفی حرکت کنید:
- خطا را به لایه قبلی انتقال دهید. به عبارت دیگر، لایهای که در حال بررسی است، خطاها را به لایه قبل میفرستد.
- وزنها را بهروزرسانی کنید.
این روش را میتوان برای هر تعداد لایه مخفی گسترش داد و در نتیجه شبکههای عصبی عمیق (Deep Neural Networks) ایجاد کرد، که شبکههایی هستند با بیش از یک لایه مخفی.
افراط در تطبیق (Overfitting):
افراط در تطبیق زمانی رخ میدهد که مدل بیش از حد دقیق روی دادههای آموزشی یاد بگیرد و در نتیجه نتواند روی دادههای جدید تعمیمپذیری خوبی داشته باشد.
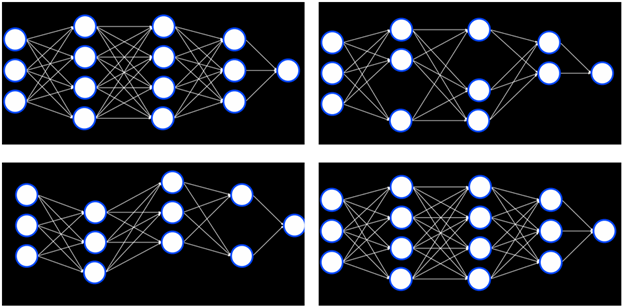
یکی از راههای مقابله با افراط در تطبیق، Dropout است. در این روش، در طول مرحله یادگیری، واحدهایی که به صورت تصادفی انتخاب میشوند بهطور موقت حذف میگردند. بدین ترتیب، تلاش میکنیم از وابستگی بیش از حد به یک واحد خاص جلوگیری کنیم.
در طول آموزش، شبکه عصبی شکلهای متفاوتی به خود میگیرد، هر بار برخی واحدها حذف میشوند و سپس دوباره استفاده میشوند:
هوش مصنوعی CS50 s5
TensorFlow:
مانند بسیاری از موارد در Python، کتابخانههای متعددی وجود دارند که پیادهسازی شبکههای عصبی با الگوریتم پسانتشار خطا را ارائه میکنند و TensorFlow یکی از این کتابخانهها است.
شما میتوانید با شبکههای عصبی TensorFlow در این وباپلیکیشن (TensorFlow Playground) آزمایش کنید. این وبسایت اجازه میدهد ویژگیهای مختلف شبکه را تعریف کرده و آن را اجرا کنید و خروجی را بهصورت بصری مشاهده کنید.
حال، به یک مثال میپردازیم که نشان میدهد چگونه میتوان از TensorFlow برای انجام کاری که در درس قبل بحث شد استفاده کرد: تشخیص اسکناسهای تقلبی از اسکناسهای واقعی.
import csv
import tensorflow as tf
from sklearn.model_selection import train_test_split
# Read data in from file
with open("banknotes.csv") as f:
reader = csv.reader(f)
next(reader)
data = []
for row in reader:
data.append({
"evidence": [float(cell) for cell in row[:4]],
"label": 1 if row[4] == "0" else 0
})
evidence = [row["evidence"] for row in data]
labels = [row["label"] for row in data]
X_training, X_testing, y_training, y_testing = train_test_split(
evidence, labels, test_size=0.4
)
ما دادههای CSV را به مدل ارائه میکنیم. اغلب کار ما شامل تطبیق دادهها با فرمت مورد نیاز کتابخانه است. بخش دشوار کدنویسی واقعی مدل قبلاً برای ما پیادهسازی شده است.
# Create a neural network
model = tf.keras.models.Sequential()
Keras یک API است که الگوریتمهای مختلف یادگیری ماشین از آن استفاده میکنند.
یک مدل Sequential مدلی است که در آن لایهها پشت سر هم قرار میگیرند مانند مدلهایی که تا اینجا دیدهایم
# Add a hidden layer with 8 units, with ReLU activation
model.add(tf.keras.layers.Dense(8, input_shape=(4,), activation="relu"))
یک Dense Layer (لایه متراکم) لایهای است که هر نود (گره) در لایه فعلی به تمام نودهای لایه قبلی متصل است.
در ایجاد لایههای مخفی خود، ما ۸ لایه متراکم ایجاد میکنیم که هر کدام ۴ نورون ورودی دارند و از تابع فعالساز ReLU که پیشتر ذکر شد استفاده میکنند.
# Add output layer with 1 unit, with sigmoid activation
model.add(tf.keras.layers.Dense(1, activation="sigmoid"))
در لایه خروجی، میخواهیم یک لایه متراکم (Dense Layer) ایجاد کنیم که از تابع فعالساز سیگموید (Sigmoid) استفاده کند؛ تابع فعالسازیای که خروجی آن مقداری بین 0 و 1 است.
# Train neural network
model.compile(
optimizer="adam",
loss="binary_crossentropy",
metrics=["accuracy"]
)
model.fit(X_training, y_training, epochs=20)
# Evaluate how well model performs
model.evaluate(X_testing, y_testing, verbose=2)
در نهایت، مدل را کامپایل میکنیم و مشخص میکنیم که کدام الگوریتم باید آن را بهینه کند، از چه نوع تابع خطایی (loss function) استفاده میکنیم و چگونه میخواهیم موفقیت مدل را اندازهگیری کنیم (در مثال ما، دقت خروجی مدنظر است). سپس مدل را روی دادههای آموزشی با ۲۰ تکرار (epoch) آموزش میدهیم و در نهایت روی دادههای تست آن را ارزیابی میکنیم.
بینایی کامپیوتری (Computer Vision):
بینایی کامپیوتری شامل روشهای محاسباتی مختلف برای تحلیل و درک تصاویر دیجیتال است و اغلب با استفاده از شبکههای عصبی انجام میشود.
برای مثال، وقتی شبکههای اجتماعی از تشخیص چهره برای تگ خودکار افراد در تصاویر استفاده میکنند، از بینایی کامپیوتری بهره میگیرند. مثالهای دیگر شامل تشخیص دستخط و خودروهای خودران است.
تصاویر از پیکسلها تشکیل شدهاند و هر پیکسل با سه مقدار بین 0 تا 255 نمایش داده میشود: یک مقدار برای قرمز، یک مقدار برای سبز و یک مقدار برای آبی. این مقادیر اغلب با RGB نمایش داده میشوند.
میتوانیم از این اطلاعات استفاده کنیم تا یک شبکه عصبی ایجاد کنیم که هر مقدار رنگ در هر پیکسل یک ورودی باشد، چند لایه مخفی داشته باشیم و خروجی شامل تعدادی واحد باشد که نشان دهد تصویر نشاندهنده چه چیزی است.
با این حال، این روش چند مشکل دارد:
- وقتی تصویر را به پیکسلها و مقادیر رنگشان تقسیم میکنیم، ساختار کلی تصویر را از دست میدهیم. به عنوان مثال، انسانها اگر قسمتی از یک صورت را ببینند، انتظار دارند بقیه صورت را نیز ببینند و این باعث سریعتر شدن پردازش میشود. ما میخواهیم از مزیتی مشابه در شبکههای عصبی استفاده کنیم.
- تعداد ورودیها بسیار زیاد است، که یعنی باید تعداد زیادی وزن محاسبه شود.
کانولوشن تصویر (Image Convolution):
کانولوشن تصویر شامل اعمال یک فیلتر است که هر پیکسل تصویر را با پیکسلهای همسایهاش جمع میکند و مقادیر با توجه به ماتریس کرنل (kernel matrix) وزندهی میشوند. انجام این کار تصویر را تغییر میدهد و میتواند به شبکه عصبی کمک کند تا آن را بهتر پردازش کند.
هوش مصنوعی CS50 s5
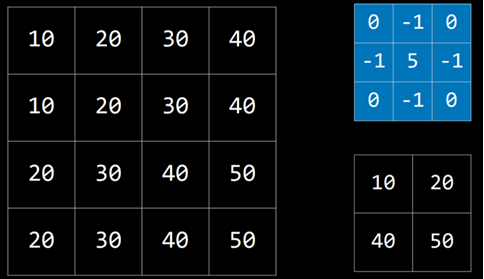
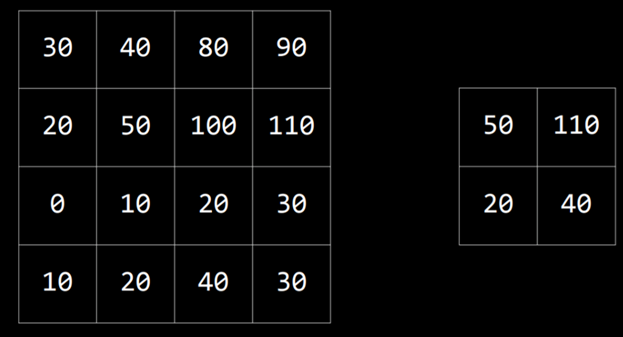
بیایید مثال زیر را بررسی کنیم:
کرنل ماتریس آبی است و تصویر همان ماتریس بزرگ در سمت چپ است. تصویر فیلتر شده حاصل، ماتریس کوچک در پایین سمت راست است.
برای فیلتر کردن تصویر با کرنل، ابتدا از پیکسل با مقدار ۲۰ در گوشه بالا-چپ تصویر (مختصات ۱,۱) شروع میکنیم. سپس تمام مقادیر اطراف آن را در مقدار متناظر در کرنل ضرب کرده و جمع میکنیم:
این مقدار ۱۰ را تولید میکند. سپس همین کار را برای پیکسل سمت راست (۳۰)، پیکسل پایین پیکسل اول (۳۰) و پیکسل سمت راست آن (۴۰) انجام میدهیم.
نتیجه این فرآیند، تصویر فیلتر شدهای است با مقادیری که در پایین سمت راست مشاهده میکنیم.
کرنلهای مختلف میتوانند وظایف متفاوتی انجام دهند. برای مثال، برای تشخیص لبهها، معمولاً از کرنل زیر استفاده میشود:
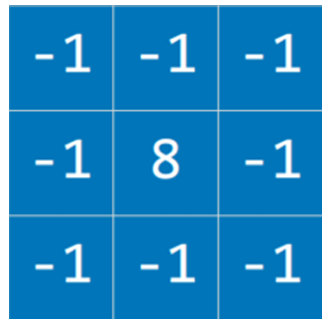
هوش مصنوعی CS50 s5
ایده این است که وقتی یک پیکسل مشابه تمام پیکسلهای همسایهاش باشد، مقادیر آنها یکدیگر را خنثی میکنند و مقدار حاصل ۰ میشود. بنابراین:
- هر چه پیکسلها مشابهتر باشند → بخش مربوطه در تصویر تیرهتر خواهد بود.
- هر چه پیکسلها متفاوتتر باشند → بخش مربوطه در تصویر روشنتر خواهد بود.
اعمال این کرنل روی یک تصویر (سمت چپ) منجر به تصویری با لبههای برجسته میشود (سمت راست).

بیایید یک پیادهسازی کانولوشن تصویر را بررسی کنیم.
ما از کتابخانه PIL مخفف Python Imaging Library)) استفاده میکنیم، که میتواند بخش زیادی از کارهای پیچیده را برای ما انجام دهد
import math
import sys
from PIL import Image, ImageFilter
# Ensure correct usage
if len(sys.argv) != 2:
sys.exit("Usage: python filter.py filename")
# Open image
image = Image.open(sys.argv[1]).convert("RGB")
# Filter image according to edge detection kernel
filtered = image.filter(ImageFilter.Kernel(
size=(3, 3),
kernel=[-1, -1, -1, -1, 8, -1, -1, -1, -1],
scale=1
))
# Show resulting image
filtered.show()
هوش مصنوعی CS50 s5
با این حال، پردازش تصویر در شبکه عصبی محاسباتی پرهزینه است، زیرا تعداد پیکسلها بهعنوان ورودی شبکه عصبی بسیار زیاد است.
یک روش دیگر برای کاهش این هزینه، Pooling است، که در آن اندازه ورودی با نمونهگیری از نواحی مختلف ورودی کاهش مییابد. پیکسلهایی که در کنار یکدیگر هستند، متعلق به همان ناحیه تصویر هستند و احتمالاً مشابهاند. بنابراین میتوانیم یک پیکسل را نماینده کل ناحیه قرار دهیم.
یکی از روشها Max Pooling است، که در آن پیکسل انتخاب شده بالاترین مقدار را در میان همه پیکسلهای همان ناحیه دارد.
به عنوان مثال، اگر مربع سمت چپ (تصویر پایین) را به چهار مربع ۲×۲ تقسیم کنیم، با Max Pooling روی این ورودی، به مربع کوچک سمت راست میرسیم.
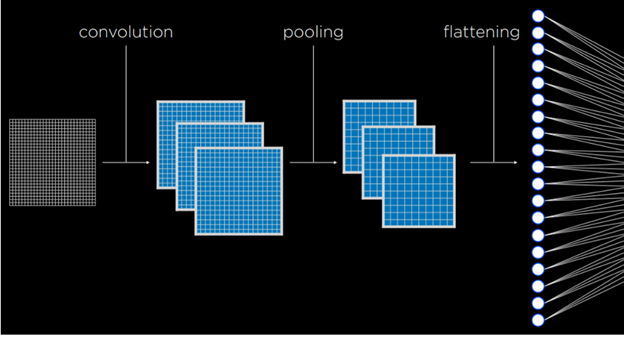
شبکههای عصبی کانولوشنی (Convolutional Neural Networks – CNNs):
یک شبکه عصبی کانولوشنی شبکهای است که از کانولوشن استفاده میکند و معمولاً برای تحلیل تصاویر به کار میرود.
فرآیند کار به این صورت است:
- ابتدا فیلترهایی اعمال میشوند که میتوانند ویژگیهایی از تصویر را استخراج کنند، با استفاده از کرنلهای مختلف.
- این فیلترها میتوانند به همان روش وزنهای دیگر شبکه عصبی بهبود یابند، یعنی با تنظیم کرنلها بر اساس خطای خروجی.
- سپس تصاویر حاصل Pooling میشوند تا اندازه ورودی کاهش یابد.
- در نهایت، پیکسلهای کاهشیافته به یک شبکه عصبی سنتی به عنوان ورودی داده میشوند؛ این فرآیند به نام Flattening شناخته میشود.
import sys
import tensorflow as tf
# Use MNIST handwriting dataset
mnist = tf.keras.datasets.mnist
# Prepare data for training
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
y_train = tf.keras.utils.to_categorical(y_train)
y_test = tf.keras.utils.to_categorical(y_test)
x_train = x_train.reshape(
x_train.shape[0], x_train.shape[1], x_train.shape[2], 1
)
x_test = x_test.reshape(
x_test.shape[0], x_test.shape[1], x_test.shape[2], 1
)
# Create a convolutional neural network
model = tf.keras.models.Sequential([
# Convolutional layer. Learn 32 filters using a 3x3 kernel
tf.keras.layers.Conv2D(
32, (3, 3), activation="relu", input_shape=(28, 28, 1)
),
# Max-pooling layer, using 2x2 pool size
tf.keras.layers.MaxPooling2D(pool_size=(2, 2)),
# Flatten units
tf.keras.layers.Flatten(),
# Add a hidden layer with dropout
tf.keras.layers.Dense(128, activation="relu"),
tf.keras.layers.Dropout(0.5),
# Add an output layer with output units for all 10 digits
tf.keras.layers.Dense(10, activation="softmax")
])
# Train neural network
model.compile(
optimizer="adam",
loss="categorical_crossentropy",
metrics=["accuracy"]
)
model.fit(x_train, y_train, epochs=10)
# Evaluate neural network performance
model.evaluate(x_test, y_test, verbose=2)
# Save model to file
if len(sys.argv) == 2:
filename = sys.argv[1]
model.save(filename)
print(f"Model saved to {filename}.")
حال، اگر برنامهای اجرا کنیم که اعداد دستنویس را بهعنوان ورودی دریافت میکند، قادر خواهد بود عدد مربوطه را با استفاده از مدل تشخیص داده و خروجی دهد.
برای پیادهسازی چنین برنامهای، به فایل recognition.py در کد منبع این درس مراجعه کنید.
شبکههای عصبی بازگشتی (Recurrent Neural Networks – RNNs):
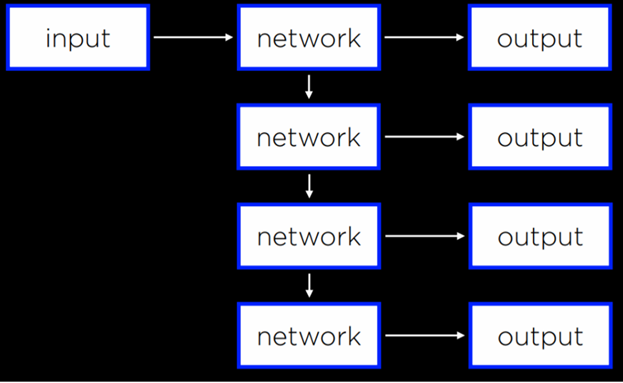
شبکههای عصبی Feed-Forward همان نوع شبکههایی هستند که تاکنون مورد بحث قرار گرفتند، جایی که دادههای ورودی به شبکه داده میشوند و در نهایت خروجی تولید میشود.
یک نمودار از نحوه کار شبکههای Feed-Forward در ادامه قابل مشاهده است.

در مقابل آن، شبکههای عصبی بازگشتی (RNN) دارای ساختار غیرخطی هستند، جایی که شبکه از خروجی خود بهعنوان ورودی استفاده میکند.
برای مثال، CaptionBot مایکروسافت (captionbot.ai) قادر است محتوای یک تصویر را با استفاده از جملات توصیف کند. این با کلاسبندی معمولی متفاوت است، زیرا خروجی میتواند طول متغیری داشته باشد بر اساس ویژگیهای تصویر.
در حالی که شبکههای عصبی Feed-Forward قادر به تغییر تعداد خروجیها نیستند، شبکههای عصبی بازگشتی میتوانند این کار را انجام دهند به دلیل ساختارشان.
در وظیفهی توضیح تصویر (Captioning)، شبکه ابتدا ورودی را پردازش کرده و یک خروجی تولید میکند، سپس ادامه پردازش از همان نقطه را انجام داده و خروجی دیگری تولید میکند و این فرآیند به اندازه لازم تکرار میشود.
شبکههای عصبی بازگشتی (RNN) در مواردی مفید هستند که شبکه با دنبالهها (sequences) سروکار دارد و نه یک شیء منفرد.
در مثال بالا، شبکه عصبی نیاز داشت تا یک دنباله از کلمات تولید کند.
با این حال، همان اصل میتواند در موارد زیر نیز به کار رود:
- تحلیل فایلهای ویدیویی که شامل دنبالهای از تصاویر هستند.
- وظایف ترجمه، جایی که یک دنباله از ورودیها (کلمات زبان مبدا) پردازش میشود تا یک دنباله از خروجیها (کلمات زبان مقصد) تولید شود.

دیدگاهتان را بنویسید