

شبکه عصبی GRU:
شبکه عصبی GRU
این دوره به بررسی دقیق و عمیق مباحث شبکه عصبی به صورت پایه ای می پردازد .جهت دسترسی به سایر دوره ها می توانید از لینک های زیر استفاده نمایید.
- شبکه های عصبی بازگشتی
- شبکه عصبی بازگشتی ساده
- شبکه عصبی بازگشتی دوطرفه
- معماریهای Stacked شبکه عصبی
- شبکه عصبی معماری Encoder–Decoder RNN
- شبکه عصبی GRU
- شبکه عصبی LSTM
و برای مشاهده لیست تمام دوره ها به بخش مقالات مراجه نمایید.
فهرست مطالب:
- چکیده
- مقدمه
- بیان مسئله و زمینه تاریخی
- معرفی کلی معماری GRU
- ساختار دروازههای GRU و منطق عملکرد آنها
- مدل مفهومی و ریاضی شبکه GRU
- فرآیند آموزش و الگوریتم Backpropagation Through Time
- مثال عددی ساده از عملکرد GRU
- پیادهسازی GRU با Python
- مزایا و محدودیتهای GRU
- مقایسه تحلیلی GRU با RNN ساده و LSTM
- کاربردهای عملی GRU
- تأثیر GRU بر معماریهای پیشرفتهتر
- نتیجهگیری پژوهشمحور
- منابع
چکیده:
شبکههای عصبی بازگشتی نقش مهمی در مدلسازی دادههای ترتیبی و وابسته به زمان ایفا میکنند. با این حال، شبکههای بازگشتی کلاسیک در یادگیری وابستگیهای زمانی بلندمدت با مشکلاتی نظیر ناپدید شدن و انفجار گرادیان مواجه هستند. برای غلبه بر این چالشها، معماریهای دروازهدار مانند LSTM و GRU معرفی شدند. شبکه GRU که در سال ۲۰۱۴ ارائه شد، با سادهسازی ساختار LSTM و کاهش تعداد پارامترهای قابل آموزش، توانست تعادلی مناسب میان دقت، سرعت آموزش و پیچیدگی محاسباتی برقرار کند. در این مقاله، معماری GRU از منظر تاریخی، مفهومی و کاربردی بررسی میشود و نقش آن در پیشرفت مدلهای یادگیری عمیق مبتنی بر توالی مورد تحلیل قرار میگیرد.
مقدمه:
- بسیاری از مسائل مهم در دنیای واقعی شامل دادههایی هستند که دارای وابستگی زمانی میباشند. زبان طبیعی، سیگنالهای صوتی، دادههای مالی و اندازهگیریهای سنسوری همگی نمونههایی از دادههای ترتیبی هستند که در آنها ترتیب اطلاعات اهمیت بالایی دارد. شبکههای عصبی بازگشتی با هدف مدلسازی چنین وابستگیهایی طراحی شدهاند و قادرند اطلاعات گذشته را در قالب حالت پنهان حفظ کنند.
- با این حال، افزایش طول توالیها و پیچیدگی الگوهای زمانی باعث شده است که شبکههای بازگشتی ساده کارایی خود را از دست بدهند. معرفی معماریهای دروازهدار مانند GRU گامی مهم در جهت افزایش توان یادگیری شبکهها و بهبود پایداری فرآیند آموزش بود. امروزه GRU بهعنوان یکی از معماریهای پایه در بسیاری از سیستمهای پردازش ترتیبی مورد استفاده قرار میگیرد.
بیان مسئله و زمینه تاریخی:
- در شبکههای عصبی بازگشتی کلاسیک، حالت پنهان در هر گام زمانی به حالت قبلی وابسته است. در عمل، هنگام آموزش این شبکهها با الگوریتم Backpropagation Through Time، گرادیانها بهتدریج کوچک یا بسیار بزرگ میشوند. این پدیده که به ناپدید شدن یا انفجار گرادیان معروف است، مانع یادگیری مؤثر وابستگیهای بلندمدت میشود.
- در سال ۱۹۹۷، معماری LSTM با معرفی سلول حافظه و دروازههای کنترلی، راهحلی برای این مشکل ارائه داد. با وجود موفقیت LSTM، پیچیدگی ساختار آن و تعداد بالای پارامترها باعث افزایش هزینه محاسباتی شد. در پاسخ به این مسئله، معماری GRU در سال ۲۰۱۴ معرفی گردید که هدف آن حفظ توان یادگیری وابستگیهای زمانی، همراه با کاهش پیچیدگی مدل بود. GRU توانست نشان دهد که با حذف برخی اجزای LSTM میتوان همچنان به عملکردی رقابتی دست یافت.
معرفی کلی معماری GRU:
- GRU یک شبکه عصبی بازگشتی دروازهدار است که برای کنترل جریان اطلاعات در طول زمان طراحی شده است. برخلاف LSTM، GRU فاقد سلول حافظه جداگانه است و حالت پنهان شبکه بهطور همزمان نقش حافظه کوتاهمدت و بلندمدت را ایفا میکند. این معماری تنها از دو دروازه کنترلی استفاده میکند که وظیفه تنظیم ورود اطلاعات جدید و حفظ اطلاعات گذشته را بر عهده دارند.
- سادگی ساختار GRU باعث شده است که پیادهسازی، آموزش و تنظیم آن نسبت به LSTM آسانتر باشد. در بسیاری از مسائل عملی، این شبکه با وجود ساختار سادهتر، دقتی مشابه یا حتی بالاتر از LSTM ارائه میدهد و به همین دلیل در پروژههای پژوهشی و صنعتی بهطور گسترده مورد استفاده قرار گرفته است.
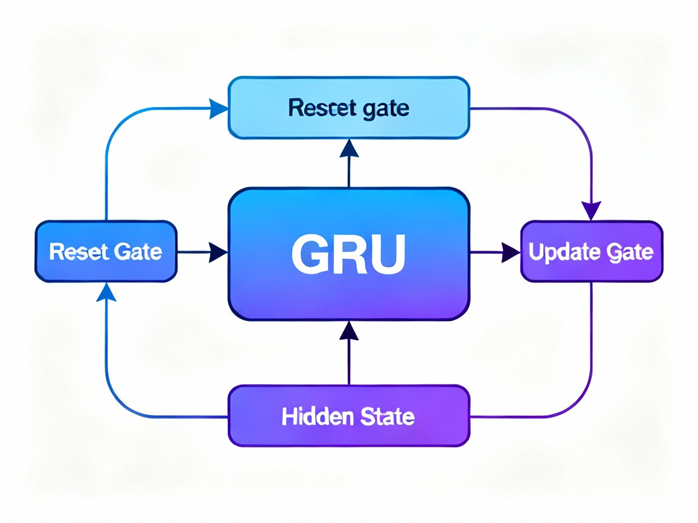
ساختار دروازههای GRU و عملکرد آنها:
دروازه بهروزرسانی (Update Gate)
دروازه بهروزرسانی تعیین میکند که چه میزان از اطلاعات گذشته باید حفظ شود و چه مقدار اطلاعات جدید وارد حالت پنهان گردد. این دروازه نقش مهمی در انتقال اطلاعات بلندمدت دارد و به شبکه اجازه میدهد اطلاعات مهم را در طول زمان بدون تغییر زیاد نگه دارد.
دروازه بازنشانی (Reset Gate)
دروازه بازنشانی مشخص میکند که هنگام محاسبه حالت جدید، چه مقدار از حالت قبلی در نظر گرفته شود. اگر مقدار این دروازه کوچک باشد، شبکه اطلاعات گذشته را نادیده گرفته و تمرکز بیشتری بر ورودی فعلی خواهد داشت. این ویژگی باعث میشود GRU بتواند بهطور تطبیقی میان وابستگیهای کوتاهمدت و بلندمدت تمایز قائل شود.
ترکیب این دو دروازه به GRU امکان میدهد تا جریان اطلاعات را بهصورت هوشمندانه کنترل کرده و از مشکلات رایج RNNهای ساده جلوگیری کند.
مدل ریاضی GRU بیان مفهومی:
در GRU، محاسبات اصلی شامل تعیین میزان تأثیر گذشته و حال بر حالت پنهان جدید است. دروازهها با استفاده از توابع سیگموئید محاسبه میشوند و مقادیری بین صفر و یک تولید میکنند که نقش وزنهای کنترلی را دارند. سپس یک حالت کاندید تولید میشود که ترکیبی از ورودی فعلی و بخشی از حالت قبلی است.
در نهایت، حالت پنهان جدید با ترکیب حالت قبلی و حالت کاندید، بر اساس مقدار دروازه بهروزرسانی ساخته میشود. این فرآیند باعث میشود شبکه بتواند تصمیم بگیرد چه اطلاعاتی را حفظ کند و چه اطلاعاتی را فراموش نماید، بدون آنکه نیاز به ساختار پیچیدهای مانند سلول حافظه جداگانه داشته باشد.
شبکه عصبی GRU
فرآیند آموزش و Backpropagation Through Time در GRU:
آموزش GRU مشابه سایر RNNها با استفاده از BPTT انجام میشود. تفاوت اصلی در این است که وجود دروازهها باعث میشود جریان گرادیان بهتر کنترل شود. Update Gate نقش مهمی در جلوگیری از ناپدید شدن گرادیان دارد، زیرا اجازه میدهد اطلاعات مهم بدون تغییر زیاد در طول زمان منتقل شوند.
به همین دلیل، GRU معمولاً سریعتر از LSTM همگرا میشود و در بسیاری از مسائل با داده محدود، عملکرد پایدارتری دارد.
مثال عددی ساده (شهودی):
فرض کنید شبکه باید یک توالی ساده را پردازش کند که در آن فقط برخی از ورودیها اهمیت دارند. اگر Update Gate مقداری نزدیک به ۱ داشته باشد، حالت قبلی تقریباً بدون تغییر منتقل میشود. اگر مقدار آن به صفر نزدیک شود، حالت جدید جایگزین حالت قبلی خواهد شد. این مکانیزم باعث میشود GRU بهصورت تطبیقی تصمیم بگیرد چه چیزی را به خاطر بسپارد.
شبکه عصبی GRU
مثال عددی مختصر از عملکرد GRU
فرض کنید یک شبکه GRU با یک نورون پنهان داریم و میخواهیم حالت پنهان جدید را در یک گام زمانی محاسبه کنیم. مقادیر زیر را در نظر بگیرید:
ورودی فعلی:
xt=0.6
حالت پنهان قبلی:
ht−1=0.4
مرحله ۱: محاسبه دروازه بهروزرسانی
فرض میکنیم مقدار خروجی دروازه بهروزرسانی برابر است با:
zt=0.7
این مقدار نشان میدهد که ۷۰٪ از حالت قبلی باید حفظ شود.
مرحله ۲: محاسبه دروازه بازنشانی
فرض میکنیم مقدار دروازه بازنشانی برابر است با:
rt=0.5
این مقدار مشخص میکند که نیمی از اطلاعات گذشته در محاسبه حالت جدید لحاظ شود.
مرحله ۳: محاسبه حالت کاندید
فرض کنید مقدار حالت کاندید محاسبهشده برابر باشد با:
ht=0.8
مرحله ۴: محاسبه حالت پنهان جدید
حالت پنهان جدید بهصورت ترکیبی از حالت قبلی و حالت کاندید محاسبه میشود:
ht=zt⋅ht−1+(1−zt)⋅ht
ht=0.7×0.4+0.3×0.8
ht=0.28+0.24=0.52
نتیجه:
حالت پنهان جدید شبکه برابر با 0.52 خواهد بود.
این مثال نشان میدهد چگونه GRU بهطور کنترلشده اطلاعات گذشته و جدید را ترکیب میکند.
پیادهسازی GRU با Python مثال مختصر:
شبکه عصبی GRU
در این بخش، یک پیادهسازی مختصر از GRU با استفاده از PyTorch ارائه میشود.
import torch
import torch.nn as nn
# تعریف یک لایه GRU
gru = nn.GRU(input_size=1, hidden_size=1, batch_first=True)
# ورودی نمونه (batch=1, sequence=3, features=1)
x = torch.tensor([[[0.6], [0.3], [0.8]]])
# اجرای GRU
output, hidden = gru(x)
print("خروجی در هر گام زمانی:")
print(output)
print("حالت پنهان نهایی:")
print(hidden)
توضیح کد:
input_size=1به این معناست که در هر گام زمانی فقط یک ویژگی داریم.
hidden_size=1یعنی فقط یک نورون پنهان وجود دارد.
- outputشامل حالتهای پنهان در تمام گامهای زمانی است.
- hiddenحالت پنهان نهایی شبکه را نشان میدهد
این مثال عددی و پیادهسازی پایتون نشان میدهد که GRU چگونه با استفاده از دروازهها، تعادلی میان حفظ اطلاعات گذشته و ورود اطلاعات جدید برقرار میکند. سادگی این ساختار باعث شده است GRU در بسیاری از کاربردهای واقعی، انتخابی مؤثر و کمهزینه باشد.
مزایا و محدودیتهای GRU:
مزایا
یکی از مهمترین مزایای معماری GRU سادگی ساختاری آن نسبت به LSTM است. GRU تنها از دو دروازه کنترلی (Update و Reset) استفاده میکند و فاقد سلول حافظه مجزا است. این موضوع باعث میشود تعداد پارامترهای قابل آموزش کاهش یابد و فرآیند یادگیری سریعتر و پایدارتر انجام شود. در بسیاری از کاربردهای عملی، بهویژه زمانی که حجم داده متوسط یا محدود است، GRU عملکردی همسطح یا حتی بهتر از LSTM ارائه میدهد.
از نظر محاسباتی، GRU نسبت به LSTM سبکتر است و مصرف حافظه کمتری دارد. این ویژگی باعث شده است که GRU در سیستمهایی با منابع محدود، مانند پردازش بلادرنگ یا دستگاههای لبه (Edge Devices)، گزینهای مناسب باشد. همچنین به دلیل سادگی دروازهها، همگرایی شبکه در مراحل اولیه آموزش سریعتر اتفاق میافتد و تنظیم ابرپارامترها سادهتر است.
محدودیتها
با وجود مزایای قابل توجه، GRU محدودیتهایی نیز دارد. نبود سلول حافظه مجزا باعث میشود کنترل دقیق جریان اطلاعات در برخی مسائل پیچیده کاهش یابد. در وظایفی که نیاز به ذخیره و بازیابی اطلاعات در بازههای زمانی بسیار طولانی وجود دارد، LSTM همچنان میتواند عملکرد بهتری داشته باشد.
علاوه بر این، اگرچه GRU در بسیاری از مسائل استاندارد عملکرد مناسبی دارد، اما انعطافپذیری آن در مدلسازی الگوهای بسیار پیچیده زمانی کمتر از LSTM است. در نهایت، انتخاب GRU بهعنوان معماری اصلی باید با توجه به ماهیت داده، طول توالیها و محدودیتهای محاسباتی انجام شود.
مقایسه تحلیلی GRU با LSTM و RNN ساده:
- در مقایسه با RNN ساده (Vanilla RNN)، GRU پیشرفت چشمگیری در مدیریت وابستگیهای زمانی بلندمدت ارائه میدهد. RNNهای ساده به دلیل ناپدید شدن گرادیان، توانایی یادگیری اطلاعات دوردست در توالی را ندارند، در حالی که GRU با استفاده از دروازههای کنترلی، جریان اطلاعات و گرادیان را تنظیم میکند.
- در مقایسه با LSTM، GRU معماری سادهتری دارد و از نظر تعداد پارامترها بهینهتر است. این سادگی باعث میشود GRU سریعتر آموزش ببیند و در بسیاری از مسائل با داده متوسط، عملکردی مشابه LSTM ارائه دهد. با این حال، LSTM به دلیل داشتن سلول حافظه جداگانه، در مسائل بسیار پیچیده و وابستگیهای طولانیمدت شدید، همچنان مزیت نسبی دارد.
- بهطور کلی، GRU را میتوان نقطه تعادل میان سادگی RNN ساده و قدرت LSTM دانست؛ معماریای که در بسیاری از کاربردها انتخابی منطقی و کارآمد محسوب میشود.
کاربردهای عملی GRU:
- GRU در طیف گستردهای از کاربردهای واقعی مورد استفاده قرار گرفته است. در حوزه پردازش زبان طبیعی، GRU برای مدلسازی توالی کلمات، تحلیل احساسات، ترجمه ماشینی و تولید متن بهکار میرود. سادگی و سرعت آموزش این معماری باعث شده است در پروژههایی که منابع محاسباتی محدود هستند، گزینهای محبوب باشد.
- در تشخیص گفتار و پردازش سیگنالهای صوتی، GRU توانسته است وابستگیهای زمانی گفتار را بهخوبی مدلسازی کند. همچنین در پیشبینی سریهای زمانی مالی، تحلیل دادههای سنسوری، اینترنت اشیا و سیستمهای توصیهگر، GRU بهعنوان مدلی سبک و مؤثر شناخته میشود.
- در بسیاری از سیستمهای صنعتی، GRU به دلیل تعادل مناسب میان دقت و هزینه محاسباتی، در کاربردهای بلادرنگ و نیمهبلادرنگ مورد استفاده قرار میگیرد.
تأثیر GRU بر معماریهای پیشرفتهتر:
- GRU نقش مهمی در توسعه و پذیرش گسترده شبکههای بازگشتی دروازهدار ایفا کرده است. این معماری نشان داد که میتوان بدون پیچیدگی بیش از حد، عملکردی رقابتی در مسائل ترتیبی بهدست آورد. بسیاری از مدلهای ترکیبی مدرن، GRU را بهعنوان یک بلوک پایه در کنار شبکههای کانولوشنی یا مکانیزمهای توجه بهکار گرفتهاند.
- همچنین GRU بهعنوان پلی میان RNNهای کلاسیک و معماریهای جدیدتر مانند مدلهای مبتنی بر Attention شناخته میشود. تجربه موفق GRU در سادهسازی LSTM، الهامبخش پژوهشهایی بوده است که به دنبال کاهش پیچیدگی مدلها بدون افت عملکرد هستند.
نتیجهگیری پژوهشمحور:
شبکه GRU را میتوان یکی از معماریهای کلیدی در تکامل شبکههای عصبی بازگشتی دانست. این مدل با کاهش پیچیدگی ساختاری و حفظ توانایی یادگیری وابستگیهای زمانی، جایگاه ویژهای در پژوهش و صنعت پیدا کرده است. بررسیها نشان میدهد که GRU در بسیاری از کاربردهای واقعی میتواند جایگزینی مناسب برای LSTM باشد، بهویژه زمانی که سرعت و منابع محاسباتی اهمیت دارند.
با وجود ظهور معماریهای جدیدتری مانند ترنسفورمرها، GRU همچنان بهعنوان مدلی کارآمد و قابل اعتماد در بسیاری از مسائل ترتیبی مورد استفاده قرار میگیرد. آینده پژوهش در این حوزه احتمالاً بر ترکیب GRU با روشهای توجه و مدلهای هیبریدی متمرکز خواهد بود تا تعادلی بهتر میان دقت، سادگی و کارایی حاصل شود.
شبکه عصبی GRU
منابع:
- Cho, K., van Merriënboer, B., Gulcehre, C., Bahdanau, D., Bougares, F., Schwenk, H., & Bengio, Y. (2014).
Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation.
Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP).. - Hochreiter, S., & Schmidhuber, J. (1997).
Long Short-Term Memory.
Neural Computation, 9(8), 1735–1780. - Goodfellow, I., Bengio, Y., & Courville, A. (2016)
Deep Learning. MIT Press. - Graves, A. (2012).
Supervised Sequence Labelling with Recurrent Neural Networks. Springer. - Bengio, Y., Simard, P., & Frasconi, P. (1994).
Learning Long-Term Dependencies with Gradient Descent is Difficult.
IEEE Transactions on Neural Networks. - Chung, J., Gulcehre, C., Cho, K., & Bengio, Y. (2014).
Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling.
NIPS Workshop. - Sutskever, I., Vinyals, O., & Le, Q. V. (2014).
Sequence to Sequence Learning with Neural Networks.
Advances in Neural Information Processing Systems (NeurIPS)
