

شبکه عصبی بازگشتی ساده:
شبکه عصبی بازگشتی ساده
این دوره به بررسی دقیق و عمیق مباحث شبکه عصبی به صورت پایه ای می پردازد .جهت دسترسی به سایر دوره ها می توانید از لینک های زیر استفاده نمایید.
- شبکه های عصبی بازگشتی
- شبکه عصبی بازگشتی ساده
- شبکه عصبی بازگشتی دوطرفه
- معماریهای Stacked شبکه عصبی
- شبکه عصبی معماری Encoder–Decoder RNN
- شبکه عصبی GRU
- شبکه عصبی LSTM
و برای مشاهده لیست تمام دوره ها به بخش مقالات مراجه نمایید.
فهرست مطالب:
- چکیده شبکه عصبی بازگشتی ساده
- مقدمه شبکه عصبی بازگشتی ساده
- بیان مسئله و انگیزه استفاده از Vanilla RNN
- معرفی کلی معماری RNN ساده
- مدل محاسباتی و روابط ریاضی در Vanilla RNN
- فرآیند آموزش و الگوریتم Backpropagation Through Time
- مثال عددی ساده از عملکرد Vanilla RNN
- پیادهسازی Vanilla RNN با Python
- مزایا و محدودیتهای Vanilla RNN
- کاربردهای عملی Vanilla RNN
- تأثیر Vanilla RNN بر معماریهای پیشرفتهتر
- نتیجهگیری پژوهشمحور
چکیده شبکه عصبی بازگشتی ساده:
شبکه عصبی بازگشتی ساده یکی از مهمترین معماریهای یادگیری عمیق برای مدلسازی دادههای ترتیبی و وابسته به زمان است. این معماری با استفاده از حالت پنهان (Hidden State) اطلاعات گذشته را به گامهای بعدی منتقل میکند و امکان یادگیری وابستگیهای زمانی را فراهم میسازد. برخلاف شبکههای پیشخور که هر ورودی را مستقل پردازش میکنند، این ساختار بین گامهای زمانی ارتباط برقرار میکند و ترتیب دادهها را حفظ میکند.
مقدمه شبکه عصبی بازگشتی ساده:
دادههای ترتیبی بخش بزرگی از اطلاعات دنیای واقعی را تشکیل میدهند. زبان طبیعی، سیگنالهای صوتی، دادههای مالی، فعالیتهای زیستی و بسیاری از فرآیندهای صنعتی ماهیتی زمانی و وابسته به ترتیب دارند. در این نوع دادهها، ترتیب وقوع مشاهدات معنا و ساختار اطلاعات را تعیین میکند. برای مثال، جایگاه کلمات در یک جمله معنا را تغییر میدهد و مقدار فعلی یک سیگنال زمانی اغلب به مقادیر گذشته وابسته است.
شبکههای عصبی پیشخور سنتی، با وجود توانایی بالا در تقریب توابع پیچیده، ورودیها را مستقل از یکدیگر پردازش میکنند و اطلاعات گذشته را ذخیره نمیکنند. این محدودیت پژوهشگران را به طراحی معماریهایی سوق داد که مفهوم حافظه را به شبکههای عصبی اضافه کنند. شبکههای عصبی بازگشتی با ایجاد حلقههای بازخوردی این نیاز را برطرف کردند.
Vanilla RNN سادهترین و بنیادیترین شکل شبکههای بازگشتی محسوب میشود و بسیاری از مفاهیم کلیدی یادگیری توالی را معرفی کرده است. اگرچه پژوهشگران امروزه کمتر از این معماری بهصورت مستقیم استفاده میکنند، درک آن برای فهم مدلهای پیشرفتهتر کاملاً ضروری باقی مانده است.
بیان مسئله و انگیزه استفاده از Vanilla RNN:
در بسیاری از مسائل واقعی، خروجی هر لحظه به اطلاعاتی وابسته است که مدل در گذشته دریافت کرده است. برای مثال، هنگام پیشبینی کلمه بعدی در یک متن، کلمات قبلی نقش تعیینکننده دارند و در پیشبینی قیمت سهام، روندهای گذشته تصمیم مدل را شکل میدهند.
مدلهایی مانند رگرسیون خطی یا شبکههای عصبی پیشخور ورودیها را مستقل پردازش میکنند و سازوکاری برای ذخیره اطلاعات گذشته ارائه نمیدهند. به همین دلیل این مدلها در مسائل ترتیبی عملکرد ضعیفی نشان میدهند. Vanilla RNN با معرفی متغیر حالت پنهان این مشکل را حل میکند. حالت پنهان مانند یک حافظه کوتاهمدت عمل میکند و خلاصهای از اطلاعات گذشته را نگه میدارد.
معرفی کلی معماری RNN ساده:
معماری Vanilla RNN از سه مؤلفه اصلی تشکیل شده است: ورودی، حالت پنهان و خروجی. در هر گام زمانی، شبکه یک بردار ورودی دریافت میکند و آن را با حالت پنهان گام قبلی ترکیب مینماید تا حالت پنهان جدید محاسبه شود. این حالت پنهان سپس برای تولید خروجی و انتقال اطلاعات به گام زمانی بعدی مورد استفاده قرار میگیرد.
ویژگی کلیدی Vanilla RNN، اشتراک وزنها در تمام گامهای زمانی است. این بدان معناست که شبکه از یک مجموعه وزن ثابت برای پردازش کل دنباله استفاده میکند، که باعث کاهش تعداد پارامترها و افزایش توان تعمیمپذیری مدل میشود. همچنین این ساختار به شبکه اجازه میدهد الگوهای تکرارشونده در طول زمان را شناسایی کند.
Vanilla RNN معمولاً از توابع فعالساز غیرخطی مانند tanh یا sigmoid برای محاسبه حالت پنهان استفاده میکند تا پویاییهای غیرخطی دادهها را مدلسازی نماید. اگرچه این معماری از نظر ساختاری ساده است، اما مفاهیم بنیادینی مانند حافظه، وابستگی زمانی و یادگیری توالیها را معرفی میکند که در معماریهای پیشرفتهتر بهشکل کاملتری توسعه یافتهاند.
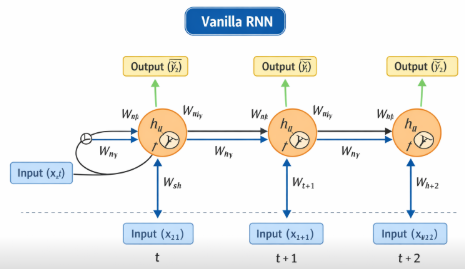
مدل محاسباتی و روابط ریاضی در Vanilla RNN:
روابط اصلی در Vanilla RNN بهصورت زیر تعریف میشوند:
حالت پنهان:
ht = tanh(Wx xt + Wh h{t-1} + bh)
خروجی:
yt = Wy ht + by
در این روابط:
xt ورودی در زمان t
ht حالت پنهان
Wx وزن ورودی
Wh وزن بازگشتی
Wy وزن خروجی
تابع tanh معمولاً برای محدود کردن مقدار حالت پنهان در بازه مشخص استفاده میشود.
فرآیند آموزش و الگوریتم Backpropagation Through Time:
آموزش Vanilla RNN با الگوریتم Backpropagation Through Time (BPTT) انجام میشود. در این روش، شبکه در طول زمان باز شده و مشابه یک شبکه پیشخور عمیق در نظر گرفته میشود. خطا ابتدا در خروجی محاسبه شده و سپس از آخرین گام زمانی به سمت گامهای اولیه منتشر میشود.
بهدلیل اشتراک وزنها، گرادیانها در تمام زمانها جمع میشوند. این ویژگی اگرچه یادگیری الگوهای زمانی را ممکن میسازد، اما باعث بروز مشکلاتی مانند محوشدگی و انفجار گرادیان میشود که از محدودیتهای اصلی Vanilla RNN بهشمار میروند.
مثال عددی ساده از عملکرد Vanilla RNN:
فرض کنید یک RNN ساده با یک نورون پنهان داریم. ورودیها بهصورت دنبالهای برابر با:
x₁ = 1
x₂ = 2
وزنها و بایاسها بهصورت زیر هستند:
Wx = 0.5
Wh = 0.3
b = 0
h₀ = 0
محاسبه حالت پنهان:
h₁ = tanh(0.5×1 + 0.3×0) ≈ 0.462
h₂ = tanh(0.5×2 + 0.3×0.462) ≈ 0.803
این مثال نشان میدهد که حالت پنهان اطلاعات گام اول را به گام دوم منتقل میکند.
پیادهسازی Vanilla RNN با Python:
توضیح مختصر کد پیادهسازی Vanilla RNN با Python
در این بخش، یک شبکه عصبی بازگشتی ساده (Vanilla RNN) را با استفاده از کتابخانه PyTorch پیادهسازی میکنیم. ابتدا کلاس مدل را تعریف میکنیم که یک لایه RNN و یک لایه کاملاً متصل برای تولید خروجی نهایی دارد. لایه RNN دادههای ترتیبی را پردازش میکند و هنگام دریافت ورودیها در گامهای زمانی متوالی، حالت پنهان را بهروزرسانی میکند.
در مرحله پیشروی (Forward Pass)، دنباله ورودی را به لایه RNN میدهیم و این لایه حالت پنهان را برای تمام گامهای زمانی تولید میکند. سپس حالت پنهان آخر را بهعنوان نمایی خلاصه از کل دنباله انتخاب میکنیم. بعد این بردار را به لایه کاملاً متصل منتقل میکنیم تا شبکه خروجی نهایی را محاسبه کند.
در فرآیند آموزش، مدل ابتدا مقدار خطا را با یک تابع هزینه مناسب محاسبه میکند. سپس الگوریتم Backpropagation Through Time وزنها را بهروزرسانی میکند و این مراحل را در چندین دوره آموزشی تکرار میکنیم. این پیادهسازی ساده نشان میدهد که Vanilla RNN چگونه وابستگیهای زمانی کوتاهمدت را یاد میگیرد و پایهای برای درک معماریهای بازگشتی پیشرفتهتر فراهم میکند.
import torch
import torch.nn as nn
class VanillaRNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(VanillaRNN, self).__init__()
self.rnn = nn.RNN(input_size, hidden_size, batch_first=True)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
out, _ = self.rnn(x)
out = self.fc(out[:, -1, :])
return out
model = VanillaRNN(input_size=1, hidden_size=5, output_size=1)
مزایا و محدودیتهای Vanilla RNN:
شبکههای عصبی بازگشتی ساده، با وجود ساختار ساده، مزایای مفهومی مهمی ارائه میکنند و هنگام معرفی خود تحولی اساسی در یادگیری ماشین ایجاد کردند. مهمترین مزیت Vanilla RNN توانایی آن در مدلسازی دادههای ترتیبی و وابسته به زمان است. این شبکهها برخلاف مدلهای پیشخور، اطلاعات گذشته را در قالب حالت پنهان ذخیره میکنند و در گامهای بعدی از آن بهره میگیرند. این ویژگی به مدل کمک میکند الگوهای زمانی ساده مانند روندها، توالیها و وابستگیهای کوتاهمدت را یاد بگیرد.
سادگی معماری و تعداد نسبتاً کم پارامترها نیز از دیگر مزایای Vanilla RNN به شمار میرود. اشتراک وزنها در طول زمان مصرف حافظه را کاهش میدهد و پیچیدگی محاسباتی را پایین نگه میدارد. این ویژگی در مسائل آموزشی و مجموعهدادههای کوچک مزیت عملی ایجاد میکند. علاوه بر این، ساختار ریاضی ساده Vanilla RNN پژوهشگران را قادر میسازد مفاهیم پایه شبکههای بازگشتی را بهصورت شفاف تحلیل و آموزش دهند.
با این حال، Vanilla RNN محدودیتهای مهمی دارد. مهمترین ضعف این معماری به مشکل ناپدیدشدن و انفجار گرادیان در فرآیند آموزش مربوط میشود. هنگام اجرای الگوریتم Backpropagation Through Time، گرادیانها در توالیهای طولانی بهسرعت کوچک یا بزرگ میشوند و یادگیری وابستگیهای بلندمدت را دشوار میکنند. در نتیجه، این مدل معمولاً اطلاعات مربوط به گذشتههای دور را بهخوبی حفظ نمیکند.
همچنین مقداردهی اولیه نامناسب وزنها یا انتخاب نادرست تابع فعالساز عملکرد شبکه را تضعیف میکند. این چالشها پژوهشگران را به طراحی معماریهای پیشرفتهتر سوق دادند، هرچند Vanilla RNN همچنان نقش آموزشی و مفهومی مهمی در یادگیری عمیق دارد.
کاربردهای عملی Vanilla RNN:
با وجود محدودیتها، پژوهشگران از Vanilla RNN در طیف متنوعی از کاربردهای عملی استفاده میکنند، بهویژه در مسائلی که وابستگیهای زمانی کوتاهمدت نقش اصلی دارند. یکی از کاربردهای کلاسیک این شبکه در مدلسازی ساده زبان طبیعی دیده میشود. برای مثال، هنگام پیشبینی کاراکتر بعدی در یک متن یا شناسایی الگوهای تکراری در توالیهای متنی کوتاه، Vanilla RNN عملکرد قابلقبولی نشان میدهد.
در حوزه پردازش سیگنال، مهندسان از Vanilla RNN برای تحلیل سیگنالهای زمانی مانند دادههای صوتی یا حسگرها استفاده میکنند. در این کاربردها، شبکه روندهای محلی و تغییرات کوتاهمدت را یاد میگیرد. همچنین در پیشبینی سریهای زمانی ساده، مانند برآورد دما یا مصرف انرژی در بازههای کوتاه، پژوهشگران این مدل را بهعنوان یک مبنای مقایسه انتخاب میکنند.
در سیستمهای کنترلی و رباتیک ساده نیز مهندسان Vanilla RNN را برای مدلسازی رفتارهای ترتیبی به کار میگیرند. در این سناریوها، شبکه دنبالهای از ورودیها را دریافت میکند و پاسخهای کنترلی متناظر را تولید میکند. هرچند در کاربردهای صنعتی پیچیدهتر معمولاً معماریهای پیشرفتهتر را ترجیح میدهند، Vanilla RNN همچنان نقش یک مدل مرجع و نقطه شروع آموزشی را حفظ میکند.
تأثیر Vanilla RNN بر معماریهای پیشرفتهتر:
Vanilla RNN نقش بنیادینی در شکلگیری معماریهای پیشرفتهتر شبکههای عصبی بازگشتی ایفا کرده است. بسیاری از ایدههای کلیدی که بعدها در مدلهایی مانند LSTM و GRU توسعه یافتند، نخستین بار در قالب Vanilla RNN مطرح شدند. مفهوم حالت پنهان، اشتراک وزنها در زمان و آموزش مبتنی بر توالیها، همگی ریشه در این معماری ساده دارند.
محدودیتهای Vanilla RNN، بهویژه مشکل ناپدیدشدن گرادیان، مستقیماً الهامبخش طراحی معماریهای جدید شد. LSTM با معرفی دروازههای کنترلی و حافظه سلولی، تلاش کرد تا این مشکل را برطرف کرده و امکان یادگیری وابستگیهای بلندمدت را فراهم آورد. بهطور مشابه، GRU با سادهسازی ساختار LSTM، تعادلی میان پیچیدگی و کارایی ایجاد کرد.
حتی در معماریهای غیر بازگشتی مدرن مانند Transformer نیز میتوان ردپای مفاهیم Vanilla RNN را مشاهده کرد. ایده پردازش ترتیبی دادهها و توجه به وابستگیهای زمانی، هرچند با مکانیزمهای متفاوت، همچنان از همان مسئلهای نشأت میگیرد که Vanilla RNN برای حل آن معرفی شد. از این منظر، Vanilla RNN را میتوان نقطه آغاز مسیر تکامل مدلهای توالیمحور دانست.
نتیجهگیری پژوهشمحور:
Vanilla RNN بهعنوان سادهترین شکل شبکههای عصبی بازگشتی، نقش بسیار مهمی در تاریخ یادگیری عمیق و مدلسازی دادههای ترتیبی ایفا کرده است. این معماری نشان داد که افزودن حافظه و بازخورد زمانی به شبکههای عصبی میتواند بهطور چشمگیری توانایی آنها را در درک ساختارهای زمانی افزایش دهد. هرچند محدودیتهای عملی آن باعث شد که در کاربردهای پیشرفته جای خود را به مدلهای پیچیدهتر بدهد، اما اهمیت مفهومی و آموزشی آن همچنان پابرجاست.
از منظر پژوهشی، Vanilla RNN بهعنوان یک مدل پایه برای تحلیل نظری، بررسی رفتار گرادیانها و مطالعه دینامیک یادگیری در شبکههای بازگشتی مورد استفاده قرار میگیرد. بسیاری از پیشرفتهای بعدی در حوزه یادگیری توالیها، بهطور مستقیم یا غیرمستقیم بر پایه درک عمیق این معماری شکل گرفتهاند.
در نهایت میتوان گفت که Vanilla RNN نه بهعنوان یک راهحل نهایی، بلکه بهعنوان سنگبنای معماریهای مدرن یادگیری ترتیبی اهمیت دارد. شناخت دقیق مزایا، محدودیتها و تأثیرات آن، برای هر پژوهشگر یا دانشجویی که در حوزه یادگیری عمیق فعالیت میکند، امری ضروری و اجتنابناپذیر است.
