

هوش مصنوعی CS50 s2
دوره هوش مصنوعی CS50 s2
آموزش هوش مصنوعی
دوره کامل آموزش هوش مصنوعی بر مبنای دوره CS5 دانشگاه هاروارد به عنوان معتبرترین و جامع ترین دوره آموزش مقدماتی و مفهومی هوش مصنوعی شناخته می شود.
این دوره به بررسی دقیق و عمیق مباحث هوش مصنوعی به صورت پایه ای می پردازد و شامل 7 بخش میباشد .جهت دسترسی به سایر دوره ها می توانید از لینک های زیر استفاده نمایید.
و برای مشاهده لیست تمام دوره ها به بخش مقالات مراجه نمایید.
CS50’s Introduction to Artificial Intelligence with Python
Danix Ai
فهرست:
مفاهیم پایهٔ احتمال و عدم قطعیت
- جهانهای ممکن
- اصول و قوانین احتمال
- احتمال بدون شرط
- احتمال شرطی
- قانون بیز
- متغیرهای تصادفی و توزیع احتمال
- استقلال و وابستگی
احتمال مشترک و قوانین ترکیبی
- احتمال مشترک
- بهنجارسازی
- ادغام (Marginalization)
- قوانین تکمیلی احتمال
شبکههای بیزی
- ساختار شبکهٔ بیزی
- گرهها، والدین و وابستگیها
- روابط سببی
- محاسبهٔ احتمال در شبکه
- مثال: رسیدن به قرار ملاقات
استنتاج در شبکههای بیزی
- متغیر پرسش
- شواهد
- متغیرهای پنهان
- استنتاج از طریق شمارش
- نمونهٔ کدنویسی با pomegranate
تقریب در استنتاج احتمالاتی
- ضرورت استفاده از روشهای تقریبی
- نمونهبرداری ساده
- نمونهبرداری شرطی
- وزندهی به نمونهها (Likelihood Weighting)
مدلهای مارکوف
- فرض مارکوف
- زنجیرهٔ مارکوف
- مدل انتقال
- نمونهبرداری در زنجیرهٔ مارکوف
- پیشبینی با Markov Chain
مدلهای مارکوف پنهان (HMM)
- تعریف وضعیت پنهان و مشاهده
- مدل حسگر (Emission Model)
- فرض مارکوف حسگر
- نمایش دو لایهٔ HMM
- وظایف HMM: فیلتر کردن، پیشبینی، هموارسازی، محتملترین تبیین
الگوریتمها و پیادهسازی HMM
- الگوریتمهای استنتاج
- الگوریتم ویتربی
- پیادهسازی HMM در پایتون
- تشخیص الگوی آبوهوا از طریق چتر
- تحلیل خروجی: توالی بیشترین احتمال
مقدمه هوش مصنوعی CS50 s2:
در علوم رایانه و بهویژه در حوزهٔ هوش مصنوعی، یکی از اساسیترین چالشها تصمیمگیری در شرایطی است که اطلاعات کامل یا قطعی در اختیار نداریم. دنیای واقعی سرشار از عدم قطعیت است؛ از پیشبینی آبوهوا و تحلیل رفتار کاربران گرفته تا تشخیص گفتار و حرکت رباتها، همواره با دادههایی مواجهیم که یا ناقصاند یا همراه با خطا و ابهام. به همین دلیل، مدلهای احتمالمحور بهعنوان ابزارهایی کلیدی برای تفسیر جهان و اتخاذ تصمیمات بهینه به کار گرفته میشوند.
در این مجموعه، مفاهیم بنیادین احتمال، اصول مدلسازی رویدادها، و نحوهٔ استنتاج از اطلاعات ناقص بررسی میشود. ابتدا با اصول اولیهٔ احتمال و نحوهٔ بیان رویدادها در قالب متغیرهای تصادفی آشنا میشویم، سپس به ساختارهای پیشرفتهتری همچون احتمال مشترک، قوانین ترکیبی، و شبکههای بیزی میپردازیم که چارچوبی منسجم برای نمایش وابستگیها میان متغیرها فراهم میکنند. پس از آن، شیوههای مختلف استنتاج ــ از روشهای دقیق مبتنی بر شمارش گرفته تا روشهای تقریبی همچون نمونهبرداری و وزندهی ــ مورد بحث قرار میگیرد.
در ادامه، مدلهای مارکوف و مدلهای مارکوف پنهان بهعنوان ابزارهای توانمند برای تحلیل پدیدههای وابسته به زمان معرفی میشوند. این مدلها امکان پیشبینی، فیلتر کردن، هموارسازی، و یافتن محتملترین دنبالهٔ رخدادها را فراهم میکنند؛ تواناییهایی که در کاربردهایی مانند تشخیص گفتار، تحلیل تصاویر، رباتیک و بسیاری از سامانههای هوشمند دیگر نقشی محوری دارند.
هدف این فصل آن است که خواننده را با مبانی نظری و ابزارهای عملی لازم برای برخورد با عدم قطعیت در سیستمهای هوشمند آشنا سازد؛ بهگونهای که بتواند در مواجهه با دادههای ناقص یا پرابهام، تحلیلی منطقی و مبتنی بر مدل ارائه دهد. این مقدمات، بنیانی ضروری برای درک الگوریتمهای پیشرفتهٔ یادگیری ماشینی و هوش مصنوعی به شمار میروند.
عدم قطعیت:
در جلسهٔ پیشین، بررسی کردیم که هوش مصنوعی چگونه میتواند دانش را بازنمایی کند و از آن نتایج تازهای به دست آورد. با این حال، در عمل، سامانهٔ هوش مصنوعی معمولاً تنها به بخشی از اطلاعات جهان دسترسی دارد و همین امر موجب بروز نوعی عدم قطعیت میشود. با وجود این محدودیت، انتظار داریم که سیستم بتواند بهترین تصمیم ممکن را اتخاذ کند. برای نمونه، در پیشبینی وضع هوا، مدل تنها اطلاعات مربوط به وضعیت امروز را در اختیار دارد و هیچ راهی برای پیشبینی کاملاً دقیق وضعیت فردا وجود ندارد. با این حال، میتوان عملکردی بهتر از حد تصادف داشت.در این درس به شیوههایی میپردازیم که به ما امکان میدهند سامانههای هوشمندی بسازیم که حتی با اطلاعات محدود و شرایط نامطمئن نیز تصمیمهای بهینه اتخاذ کنند.
احتمال:
عدم قطعیت را میتوان با مجموعهای از رویدادها و میزان احتمال وقوع هر یک از آنها نمایش داد.
جهانهای ممکن:
هر وضعیت ممکن را میتوان «جهانی» در نظر گرفت که معمولاً با حرف کوچک یونانی امگا (ω) نمایش داده میشود. برای مثال، نتیجهٔ پرتاب یک تاس را میتوان در قالب شش جهان ممکن تصور کرد: جهانی که در آن عدد ۱ ظاهر میشود، جهانی که در آن عدد ۲ حاصل میشود، و به همین ترتیب تا ۶. احتمال وقوع هر جهان را با P(ω) نمایش میدهیم.
اصول بنیادین احتمال:
-
برای هر جهان ممکن، مقدار احتمال باید میان ۰ و ۱ قرار گیرد:
مقدار ۰ نشاندهندهٔ رویدادی ناممکن است، مانند آنکه تاسی استاندارد عدد ۷ نشان دهد.
مقدار ۱ بیانگر رویدادی قطعی است، مانند آنکه تاسی استاندارد عددی کمتر از ۱۰ بدهد.
هرچه مقدار احتمال بزرگتر باشد، امکان وقوع رویداد بیشتر است.
-
مجموع احتمال همهٔ رویدادهای ممکن باید برابر ۱ باشد.
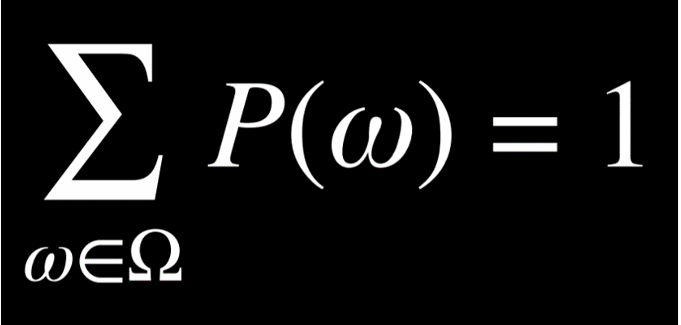
احتمالِ ظاهر شدن عدد R در پرتاب یک تاس استاندارد را میتوان با P(R) نمایش داد. در این حالت، مقدار P(R) = 1/6 است؛ زیرا شش حالت ممکن برای نتیجهٔ تاس وجود دارد (اعداد ۱ تا ۶) و احتمال وقوع هر یک از آنها یکسان است.
اکنون فرض کنید دو تاس را همزمان پرتاب کنیم. در این صورت، تعداد رویدادهای ممکن به ۳۶ حالت افزایش مییابد؛ زیرا هر کدام از شش حالت تاس اول میتواند با هر یک از شش حالت تاس دوم ترکیب شود. در این وضعیت نیز همهٔ این رویدادها احتمال وقوعی یکسان دارند.

با این حال، اگر بخواهیم حاصل جمع دو تاس را پیشبینی کنیم، وضعیت متفاوت خواهد بود. در این حالت، تنها 11 نتیجهٔ ممکن وجود دارد، زیرا مجموع اعداد میتواند تنها از ۲ تا ۱۲ تغییر کند. افزون بر این، این نتایج نیز به یک میزان رخ نمیدهند و برخی از مجموعها احتمال وقوع بیشتری دارند.

برای محاسبهٔ احتمال یک رویداد، تعداد جهانهایی که آن رویداد در آنها رخ میدهد را بر تعداد کل جهانهای ممکن تقسیم میکنیم. برای نمونه، هنگام پرتاب دو تاس، ۳۶ جهان ممکن وجود دارد. تنها در یکی از این جهانها ــ یعنی زمانی که هر دو تاس عدد ۶ را نشان دهند ــ مجموع دو تاس برابر با ۱۲ خواهد بود. بنابراین، P(12)=361
به بیان دیگر، احتمال آنکه در پرتاب دو تاس مجموع اعداد برابر با ۱۲ شود، یک سیوششم است.
حال احتمال مجموع ۷ را در نظر بگیرید. با شمارش حالتها میبینیم که مجموع ۷ در شش جهان ممکن رخ میدهد. بنابراین:
احتمال بدون شرط:
احتمالِ بدون شرط، میزان باور ما به درستیِ یک گزاره در نبود هرگونه شواهد یا اطلاعات اضافی است. تمام پرسشهایی که تاکنون دربارهٔ پرتاب تاس مطرح کردیم، نمونههایی از احتمال بدون شرط اند؛ زیرا نتیجهٔ پرتاب تاس به هیچ رویداد پیشین وابسته نیست.
احتمال شرطی:
احتمال شرطی میزان باوری است که به یک گزاره داریم، مشروط بر آنکه پیشتر شواهدی دربارهٔ وضعیت جهان دریافت کرده باشیم. همانگونه که در مقدمه اشاره شد، هوش مصنوعی اغلب با اطلاعات ناقص مواجه است، اما میتواند بر اساس همین اطلاعات ناقص، برآوردهایی هوشمندانه دربارهٔ آینده ارائه دهد. برای آنکه بتوانیم از این اطلاعات تأثیرگذار استفاده کنیم ( اطلاعاتی که بر احتمال وقوع رویدادهای آتی اثر میگذارند ) به مفهوم «احتمال شرطی» نیاز داریم.
احتمال شرطی با نماد P(a | b) نمایش داده میشود؛ یعنی «احتمال رخ دادن رویداد a با فرض این که میدانیم رویداد b رخ داده است» یا به بیان کوتاهتر، (احتمال a به شرط b ) اکنون میتوانیم پرسشهایی از این دست مطرح کنیم:
احتمال بارش امروز با توجه به اینکه دیروز باران آمده است:
P (rain today | rain yesterday)
احتمال ابتلای یک بیمار به بیماری با توجه به نتیجهٔ آزمایش او:
P(disease | test results)
از دیدگاه ریاضی، برای محاسبهٔ احتمال شرطیِ a به شرط b از رابطهٔ زیر استفاده میکنیم:
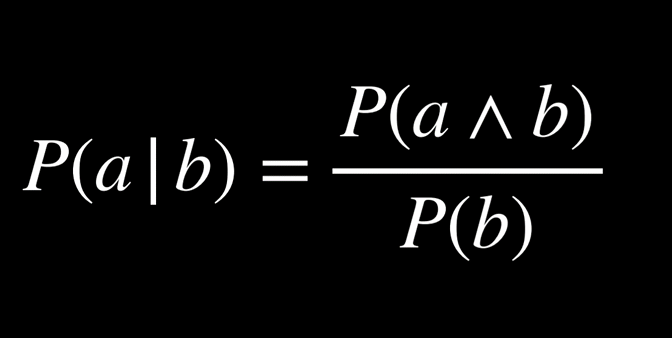
به بیان ساده، احتمالِ درستیِ a به شرط b برابر است با احتمال همزمانِ درست بودن a و b، تقسیم بر احتمال درست بودن b . میتوان این مفهوم را چنین شهودی توضیح داد: «ما تنها جهانهایی را در نظر میگیریم که در آنها هر دو رویداد a و b رخ دادهاند (صورت کسر)، اما این توجه محدود است به جهانهایی که میدانیم رویداد b در آنها رخ داده است (مخرج کسر).» تقسیم بر احتمال b در واقع فضای ممکن را فقط به جهانهایی محدود میکند که b در آنها برقرار است.
رابطهٔ بالا را میتوان به شکلهای همارز زیر نیز نوشت:
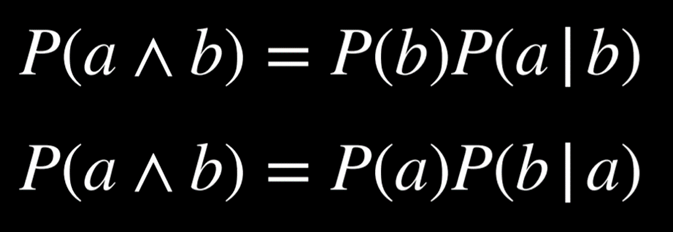
هوش مصنوعی CS50 s2
برای مثال، احتمال P(sum = 12 | roll six on one die) را در نظر بگیرید؛ یعنی احتمال آنکه با پرتاب دو تاس، مجموع اعداد برابر با ۱۲ شود، با این فرض که میدانیم یکی از تاسها عدد ۶ را نشان داده است.
برای محاسبهٔ این احتمال، ابتدا جهانهای ممکن را به حالاتی محدود میکنیم که در آنها تاس اول عدد ۶ را نشان میدهد:
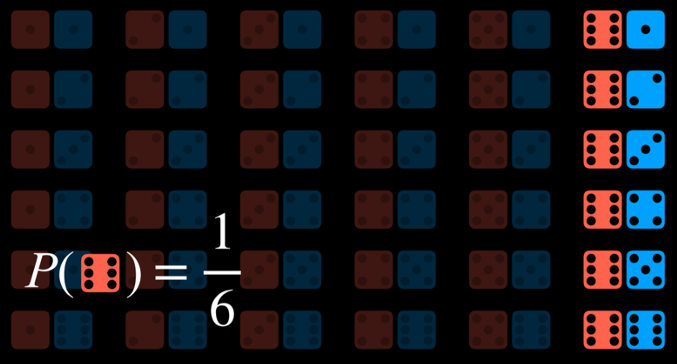
هوش مصنوعی CS50 s2
اکنون میپرسیم رویداد a یعنی برابر بودن مجموع با ۱۲ در میان جهانهایی که پرسش را به آنها محدود کردهایم، چند بار رخ میدهد. به بیان دیگر، میخواهیم ببینیم در میان همهٔ حالتهایی که در آنها تاس اول عدد ۶ را نشان میدهد (که همان تقسیم بر P(b) یا احتمالِ ظاهر شدن ۶ در تاس اول است)، چند حالت مجموع ۱۲ را نشان میدهند.
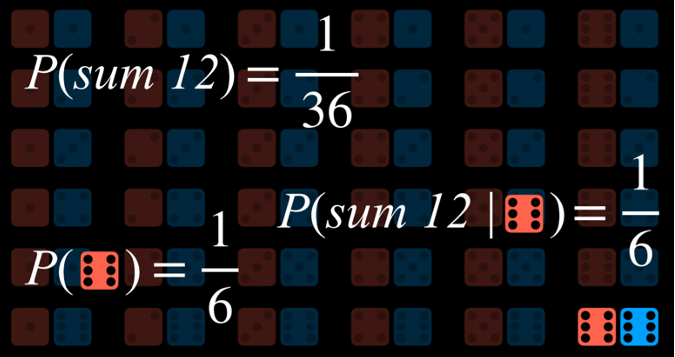
متغیرهای تصادفی:
متغیر تصادفی، مفهومی در نظریهٔ احتمال است که دامنهای از مقادیر ممکن را میتواند به خود بگیرد. برای نمونه، برای نمایش نتیجههای احتمالیِ پرتاب یک تاس، میتوان متغیری به نام Roll تعریف کرد که مقادیر آن مجموعهٔ {۱، ۲، ۳، ۴، ۵، ۶} است. یا برای نشان دادن وضعیت یک پرواز، میتوان متغیر Flight را تعریف کرد که مقادیر آن شامل {بهموقع، تأخیر، لغو} است.
در بسیاری از موارد، علاقهمندیم بدانیم هر یک از این مقادیر با چه احتمالی رخ میدهند. این اطلاعات را در قالب توزیع احتمال بیان میکنیم.
هوش مصنوعی CS50 s2 برای مثال:
P (Flight = on time) =0.6
P (Flight = delayed) =0.3
P (Flight = canceled) =0.1
به زبان ساده، این توزیع بیان میکند که احتمال بهموقع بودن پرواز ۶۰ درصد، احتمال تأخیر آن ۳۰ درصد، و احتمال لغوشدن ۱۰ درصد است. همانطور که پیشتر گفته شد، مجموع احتمالهای تمام حالتهای ممکن باید برابر با ۱ باشد.
توزیع احتمال را میتوان بهصورت فشردهتر و در قالب یک بردار نیز نوشت. برای مثال:
P(Flight)=⟨0.6, 0.3, 0.1⟩
البته برای تفسیر این نمادگذاری، لازم است ترتیب این مقادیر مشخص باشد (لغو، تأخیر، بهموقع).
استقلال:
استقلال به این معناست که وقوع یک رویداد، احتمال وقوع رویداد دیگر را تغییر نمیدهد. برای نمونه، هنگام پرتاب دو تاس، نتیجهٔ ظاهرشده یکی از آنها بر نتیجهٔ دیگری تأثیری ندارد؛ اگر تاس اول عدد ۴ را نشان دهد، این امر، احتمال عددی را که در تاس دوم ظاهر میشود تغییر نمیدهد. در مقابل، برخی رویدادها وابسته هستند؛ مانند «ابری بودن صبح» و «بارش باران در بعدازظهر». اگر صبح هوا ابری باشد، احتمال بارش در بعدازظهر افزایش مییابد، بنابراین این دو رویداد مستقل نیستند.
تعریف ریاضی استقلال چنین است: دو رویداد a و b مستقلاند اگر و تنها اگر احتمال رخ دادن همزمان آن دو برابر با حاصلضرب احتمالهای مستقل آنها باشد:
P(a∧b) =P(a)P(b)
قاعدهٔ بیز:
قاعدهٔ بیز یکی از ابزارهای بنیادی در نظریهٔ احتمال برای محاسبهٔ احتمالهای شرطی است. این قاعده میگوید: احتمال رخ دادن b با فرض وقوع a برابر است با احتمال وقوع a به شرط b، ضرب در احتمال b، و سپس تقسیم بر احتمال a. به بیان دیگر، قاعدهٔ بیز راهی فراهم میآورد تا با بهرهگیری از اطلاعات موجود، برآورد دقیقتری از احتمال رویدادها داشته باشیم.
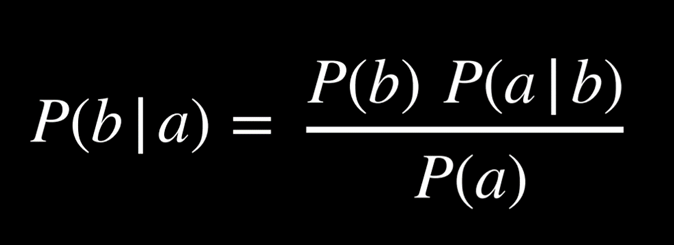
هوش مصنوعی CS50 s2
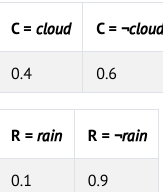
برای نمونه، میخواهیم احتمال بارش باران در بعدازظهر را در صورتی محاسبه کنیم که صبحِ آن روز هوا ابری بوده باشد؛ یعنیP(rain∣clouds) اطلاعات زیر را در اختیار داریم:
۸۰٪ از بعدازظهرهای بارانی با صبح ابری آغاز میشوند:
P(clouds∣rain) =0.8
۴۰٪ روزها صبح ابری دارند:
P(clouds)=0.4
۱۰٪ روزها بعدازظهر بارانی دارند:
P(rain)=0.1
با بهکارگیری قاعدهٔ بیز، مقدار زیر را محاسبه میکنیم:
بنابراین، احتمال بارش باران در بعدازظهر، مشروط بر آنکه صبح هوا ابری بوده باشد، برابر با ۲۰٪ است.
دانستن مقدارP(a∣b) همراه باP(a) وP(b) به ما امکان میدهد مقدارP(b∣a) را نیز محاسبه کنیم. این توانایی بسیار سودمند است، زیرا با داشتن احتمال شرطیِ وقوع یک اثر مشهود در صورت وجود یک علت نامشهود، یعنی P(visible effect∣unknown cause)، میتوانیم احتمال وجود آن علت پنهان را با مشاهدهٔ اثر ظاهری بسنجیم:
P(unknown cause∣visible effect)
برای مثال، از طریق آزمایشهای پزشکی میتوانیم مقدارP(medical test results∣disease) را بیاموزیم؛ یعنی در افراد مبتلا بررسی کنیم که آزمایش تا چه اندازه بیماری را تشخیص میدهد. هنگامی که این مقدار را بدانیم، میتوانیم مقدارP(disease∣medical test results) را محاسبه کنیم؛ مقداری که در تشخیص پزشکی اهمیت فراوان دارد.
احتمال مشترک:
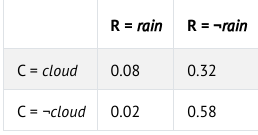
احتمال مشترک، بیانگر احتمال وقوع همزمانِ چند رویداد است.برای روشنتر شدن مفهوم، مثالی را در نظر بگیریم که احتمالِ ابری بودن صبح و بارانی بودن بعدازظهر را بهطور همزمان بررسی میکند.
با توجه به این دادهها، نمیتوانیم تنها بر اساس مشاهدهٔ جداگانهٔ هر متغیر نتیجه بگیریم که آیا ابری بودن صبح بر احتمال وقوع باران در بعدازظهر اثر دارد یا خیر. برای بررسی این موضوع، باید به احتمالهای مشترک تمام حالتهای ممکنِ این دو متغیر توجه کنیم. این اطلاعات را میتوان در قالب جدولی مانند جدول زیر نمایش داد:
هوش مصنوعی CS50 s2
اکنون با استفاده از این دادهها میتوانیم دربارهٔ احتمال مشترک وقوع رویدادها اطلاعاتی بهدست آوریم. برای نمونه، میدانیم که احتمال ابری بودن صبح و بارانی بودن بعدازظهر برابر با ۰٫۰۸ است. همچنین، احتمال آنکه صبح هوا ابری نباشد و بعدازظهر نیز بارانی نشود، ۰٫۵۸ است.
با بهرهگیری از احتمالهای مشترک، میتوان احتمال شرطی را استنتاج کرد. برای مثال، اگر بخواهیم توزیع احتمالِ ابری بودن صبح را با علم به بارش باران در بعدازظهر محاسبه کنیم، از رابطهٔ زیر استفاده میکنیم:
نکتهٔ جانبی: در نظریهٔ احتمال، استفاده از علامت کاما یا نماد ∧معادل یکدیگر است؛ بنابراین P (C, rain) =P(C∧rain)
به بیان ساده، احتمال مشترکِ «باران و ابر» را بر احتمال «باران» تقسیم میکنیم.
در این معادله، میتوان P(rain) را بهمنزلهٔ یک ثابت در نظر گرفت که برP(C, rain) ضرب میشود. از این رو میتوان نوشت:
P(C∣rain) =αP(C, rain)
یا به صورت برداری:
α⟨۰٫۰۸ ,۰٫۰۲ ⟩
عاملα (alphaα) را بیرون میکشیم و تنها نسبتها باقی میمانند؛ یعنی نسبت احتمال حالت «صبحِ ابری» به حالت «صبحِ بدون ابر» در روزهایی که بعدازظهر بارانیاند، ۰٫۰۲ : ۰٫۰۸است.
توجه داشته باشید که ۰٫۰۲ و ۰٫۰۸ جمعشان برابر با ۱ نیست. اما این اعداد در واقع باید توزیع احتمال متغیر تصادفی C را تشکیل دهند، و بنابراین لازم است مجموع آنها برابر ۱ باشد. برای این کار، باید مقدار α را چنان بیابیم که:
۱=α۰٫۰۲+ α۰٫۰۸
در نهایت، با نرمالسازی نتیجه میتوان نوشت:
P(C∣rain)=⟨0.8, 0.2⟩
یعنی اگر بعدازظهر بارانی باشد، احتمال آنکه صبح هوا ابری بوده باشد ۸۰ درصد و احتمال آنکه بدون ابر بوده باشد ۲۰ درصد است.
قواعد احتمال:
۱. نقیض (Negation)
P (¬a)=1−P(a)
این رابطه از آنجا ناشی میشود که مجموع احتمال همهٔ جهانهای ممکن برابر با ۱ است، و دو گزارهٔ مکمل a و ¬a تمامی جهانهای ممکن را در بر میگیرند.
۲. شمول ـ طرد :(Inclusion–Exclusion)
P(a∨b)=P(a)+P(b)−P(a∧b)
تفسیر این رابطه چنین است: جهانهایی که در آنها a یا b برقرار است، برابر است با مجموع جهانهایی که در آن a برقرار است، بهعلاوهٔ جهانهایی که در آن b برقرار است. اما در این جمع، آن دسته از جهانها که در آنها هر دو گزارهٔ a و b همزمان درستاند، دوبار شمرده شدهاند. بنابراین، برای جلوگیری از این شمارش تکراری، باید یک بار مقدار P(a∧b) را کم کنیم.
برای روشنتر شدن موضوع، مثالی خارج از درس را در نظر بگیریم:
فرض کنید ۸۰٪ روزها بستنی میخورم و ۷۰٪ روزها شیرینی. اگر بدون کم کردن P(ice cream∧cookies)، احتمال خوردن «بستنی یا شیرینی» را محاسبه کنیم، به مقدار اشتباه
0.8+0.7=1.5
میرسیم؛ رقمی که اصول احتمال را نقض میکند، زیرا احتمال باید بین ۰ و ۱ باشد. برای اصلاح این خطا، باید یک بار احتمال روزهایی را که هر دو را با هم خوردهام از مجموع کم کنیم.
۳. بهحاشیهرانی :(Marginalization)
P(a)=P(a,b)+P(a,¬b)
ایدهٔ اصلی این است که دو گزارهٔ b و ¬b ناپوشا یا متبایناند؛ یعنی احتمال وقوع همزمان آنها برابر صفر است. همچنین میدانیم احتمال وقوع یکی از این دو b یا ¬b دو حالت مکمل دارد و مجموع آنها برابر با ۱ است. بنابراین، وقتی a رخ میدهد، یا b نیز همراه آن رخ میدهد، یا نمیدهد. از این رو، با جمع کردن احتمال «وقوع همزمان a و b با احتمال وقوع a و عدم وقوع b، به سادگی به احتمال وقوع a میرسیم.
بهکارگیری قاعدهٔ بهحاشیهرانی برای متغیرهای تصادفی را میتوان به صورت زیر بیان کرد:
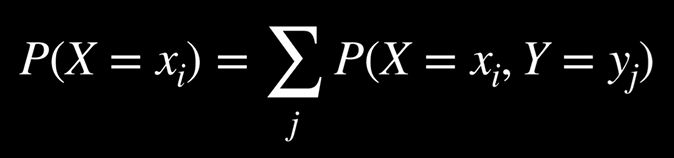
هوش مصنوعی CS50 s2
طرفِ چپِ معادله به این معناست که «احتمال آنکه متغیر تصادفی X مقدار xᵢ را به خود بگیرد» چقدر است. برای مثال، دربارهٔ متغیر C که پیشتر به آن اشاره کردیم، دو مقدار ممکن وجود دارد: «صبحِ ابری» و «صبحِ بدون ابر»
اما بخش راست معادله بیانگر مفهوم بهحاشیهرانی است.
یعنی مقدار
P(X=xi)
از طریق جمع کردن احتمالِ همزمانِ این مقدار با همهٔ حالتهای ممکن متغیر دیگری بهدست میآید.
این مقدار برابر است با مجموع تمام احتمالهای مشترکِ رخ دادن xᵢ همراه با تکتکِ مقادیر ممکنِ متغیر تصادفی Y.
برای نمونه:
P(C=cloud)=P(C=cloud, R=rain)+P(C=cloud, R=¬rain) =0.08+0.32=0.4
شرطیسازی: (Conditioning)
P(a)=P(a∣b)P(b)+P(a∣¬b)P(¬b)
این رابطه مفهومی مشابهِ بهحاشیهرانی دارد. یعنی احتمال وقوع رویداد a برابر است با احتمال رخ دادن a به شرط وقوع b، ضربدر احتمال b، بهعلاوهٔ احتمال رخ دادن a به شرط عدم وقوع b، ضربدر احتمال ¬b.
به بیان ساده، برای محاسبهٔ احتمال a، همهٔ جهانهایی را در نظر میگیریم که b در آنها برقرار است و همهٔ جهانهایی را که b برقرار نیست؛ سپس احتمال a را در هر دو گروه تحلیل و در نهایت جمع میکنیم.
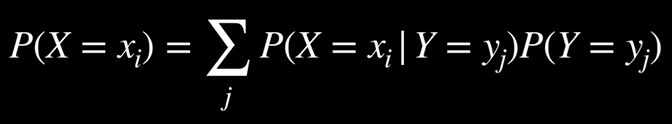
در این رابطه، متغیر تصادفی X مقدار xᵢ را با احتمالی میپذیرد که برابر است با مجموعِ احتمالهای رخ دادن xᵢ بهشرط هر یک از مقادیرِ ممکنِ متغیر تصادفی Y، ضربدر احتمال آنکه Y آن مقدار را بپذیرد.
این نتیجه کاملاً منطقی است، اگر به یاد آوریم که:
حال اگر هر دو طرف این رابطه را در P(b) ضرب کنیم، مقدار P(a, b) بهدست میآید. از این نقطه به بعد، همان فرایندی را ادامه میدهیم که در بهحاشیهرانی به کار بردیم: یعنی با جمع کردن احتمالهای مشترک مربوط به همهٔ مقادیر ممکن Y، احتمال نهایی رخ دادن xᵢ را محاسبه میکنیم.
شبکههای بیزی:
شبکهٔ بیزی ساختاری دادهمحور است که وابستگیهای میان متغیرهای تصادفی را نمایش میدهد. چنین شبکههایی دارای ویژگیهای زیر هستند:
- گراف جهتدار هستند.
- هر گره در این گراف، یک متغیر تصادفی را نمایش میدهد.
- وجود یک پیکان از X به Y بدین معناست که X والدِ Y است؛ یعنی توزیع احتمالیِ Y به مقدار متغیر X وابسته است.
- هر گرهٔ X دارای یک توزیع احتمال بهصورت:
P(X∣Parents(X))
است که وابستگی آن به والدهایش را نشان میدهد.
برای روشنتر شدن مفهوم، مثالی از یک شبکهٔ بیزی در نظر میگیریم که شامل متغیرهایی است که بر «بهموقع رسیدن به قرار ملاقات» اثر میگذارند.
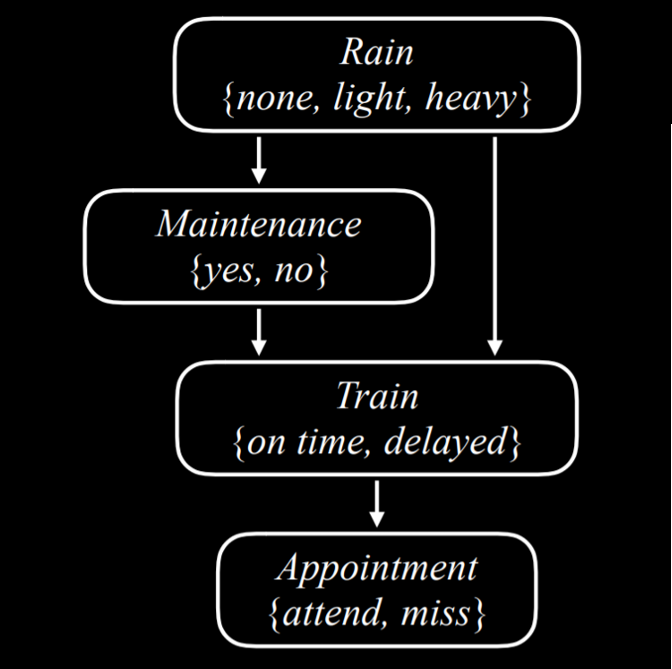
اکنون این شبکهٔ بیزی را از بالا به پایین توصیف میکنیم:
Rainگرهٔ ریشه در این شبکه است. این بدان معناست که توزیع احتمال آن به هیچ رویداد پیشینی وابسته نیست. در مثال ما، Rain یک متغیر تصادفی است که میتواند یکی از مقادیر {بدون باران، بارانِ سبک، بارانِ شدید} را بپذیرد و توزیع احتمال آن به صورت زیر تعریف میشود:
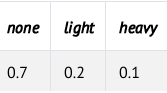
در مثال ما
Maintenance بیانگر این است که آیا عملیات نگهداری خطوط راهآهن در جریان است یا خیر. این متغیر میتواند یکی از دو مقدار «بله» یا «خیر» را به خود بگیرد و وضعیت انجام یا عدم انجام تعمیرات را رمزگذاری میکند. مقادیر این متغیر {yes, no} هستند.
متغیر Rain بهعنوان والدِ Maintenance عمل میکند؛ به این معنا که احتمال وقوع یا عدم وقوعِ عملیات نگهداری خطوط، به مقدار بارش باران وابسته است.
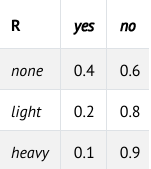
Train متغیری است که نشان میدهد قطار بهموقع میرسد یا دچار تأخیر میشود، و میتواند یکی از دو مقدار {on time, delayed} را به خود بگیرد. توجه کنید که دو پیکان از متغیرهای Maintenance و Rain به سمت Train رسم شده است. این موضوع نشان میدهد که هر دو متغیر، والدِ Train هستند و مقادیر آنها بر توزیع احتمالِ وضعیت قطار اثر میگذارد.
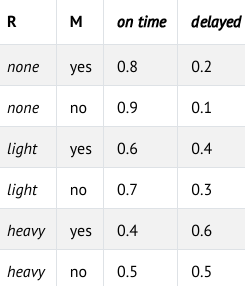
Appointment متغیر تصادفیای است که نشان میدهد آیا در قرار خود حاضر میشویم یا آن را از دست میدهیم، و میتواند یکی از دو مقدار {attend, miss} را به خود بگیرد.
نکتهٔ قابل توجه آن است که این متغیر تنها یک والد دارد: Train.
این نکته در شبکههای بیزی اهمیت ویژهای دارد: والدها فقط روابطِ مستقیم را نشان میدهند.
درست است که عملیات نگهداری خطوط میتواند بر بهموقع رسیدن قطار تأثیر بگذارد، و بهموقع رسیدن قطار نیز میتواند بر حضور ما در قرار ملاقات اثر بگذارد. با این حال، آنچه مستقیماً بر احتمال رسیدن ما به قرار تأثیر دارد، تنها «بهموقع رسیدن یا نرسیدن قطار» است؛ و همین رابطهٔ مستقیم است که در شبکهٔ بیزی نمایش داده میشود.
برای مثال، حتی اگر باران شدید باشد و تعمیرات خطوط نیز در جریان باشد، ولی قطار بهموقع برسد، این شرایط هیچ اثری بر حضور ما در قرار ملاقات نخواهد داشت.
هوش مصنوعی CS50 s2
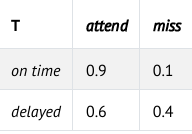
برای نمونه
، فرض کنید میخواهیم احتمال از دست دادن قرار ملاقات را، در شرایطی محاسبه کنیم که قطار دچار تأخیر شده، تعمیراتی در خطوط انجام نشده و بارانِ سبک میباریده است؛ یعنی:
P(light, no, delayed, miss)
برای محاسبهٔ این مقدار، از رابطهٔ زیر استفاده میکنیم:
P(light)P(no∣light)P(delayed∣light, no)P(miss∣delayed)
مقادیر هر یک از این احتمالهای منفرد را میتوان از توزیعهای احتمالی ارائهشده در بخشهای قبل استخراج کرد. سپس با ضرب کردن آنها در یکدیگر، مقدار نهایی یعنی:
P(light, no, delayed, miss)
در جلسهٔ پیشین، استنتاج را بر پایهٔ «دلالت منطقی» بررسی کردیم؛ یعنی حالتی که میتوانیم بر اساس دانشی که از پیش در اختیار داریم، با قطعیت به اطلاعات تازهای دست یابیم. اما در کنار استنتاج قطعی، میتوانیم بر پایهٔ احتمالها نیز به نتایج جدید برسیم. گرچه این نوع استنتاج، قطعیت کامل به ما نمیدهد، اما امکان محاسبه و برآورد توزیعهای احتمالیِ مقادیر ناشناخته را فراهم میسازد.
استنتاج احتمالاتی دارای ویژگیها و قوانین گوناگونی است که در ادامه به آنها پرداخته میشود.
- متغیر پرسش (Query X): متغیری است که میخواهیم توزیع احتمال آن را محاسبه کنیم.
- متغیرهای شاهد (Evidence variables E): یک یا چند متغیری که مقدار آنها را مشاهده کردهایم. برای مثال، ممکن است مشاهده کرده باشیم که بارانِ سبک در حال باریدن است، و همین مشاهده به ما کمک میکند احتمال تأخیر قطار را برآورد کنیم.
- متغیرهای پنهان (Hidden variables Y): متغیرهایی که نه متغیر پرسش هستند و نه مقدار آنها را مشاهده کردهایم. برای نمونه، وقتی در ایستگاه قطار ایستادهایم، میتوانیم بارش باران را مشاهده کنیم، اما نمیتوانیم بدانیم در بخشهای دورتر خط، عملیات نگهداری در حال انجام است یا خیر. بنابراین، Maintenance در این شرایط یک متغیر پنهان محسوب میشود.
هدف این است که مقدارP(X∣e)
را محاسبه کنیم. برای نمونه، میخواهیم توزیع احتمال متغیر Train (متغیر پرسش) را با استفاده از شاهد e که نشاندهندهٔ «بارانِ سبک» است محاسبه کنیم.
بهعنوان مثال، فرض کنید میخواهیم توزیع احتمال متغیر Appointment را با توجه به شواهدی محاسبه کنیم که نشان میدهد بارانِ سبک در حال باریدن است و هیچ عملیاتِ نگهداریای در خطوط انجام نمیشود. به بیان دیگر، میدانیم که «بارانِ سبک» و «عدمِ نگهداری» برقرار است و میخواهیم احتمال آنکه در قرار خود حاضر شویم یا آن را از دست بدهیم را محاسبه کنیم:
P(Appointment∣light, no)
بر اساس بخش مربوط به احتمال مشترک، میدانیم که میتوانیم مقادیر ممکن متغیر Appointment را به صورت نسبتهایی بیان کنیم و عبارت بالا را اینگونه بازنویسی کنیم:
P(Appointment∣light, no)=αP(Appointment, light, no)
اکنون پرسش این است: چگونه میتوانیم توزیع احتمال Appointment را محاسبه کنیم، در حالی که والدِ مستقیم آن تنها متغیر Train است و نه Rain یا Maintenance؟
در اینجا از بهحاشیهرانی (Marginalization) استفاده میکنیم.
مقدارP(Appointment, light, no)
برابر است با:
α[P(Appointment, light, no, delayed)+P(Appointment, light, no, on time)]
به عبارت دیگر، احتمالِ مشترک را با جمع کردن دو حالت بهدست میآوریم: حالتی که قطار تأخیر دارد و حالتی که قطار بهموقع میرسد.
استنتاج از طریق شمارش :(Inference by Enumeration)
استنتاج از طریق شمارش روشی است برای محاسبهٔ توزیع احتمالِ متغیر X با توجه به شواهدِ مشاهدهشدهٔ e و مجموعهای از متغیرهای پنهان Y. در این شیوه، همهٔ مقادیر ممکن متغیرهای پنهان در نظر گرفته میشود و با جمعکردن احتمالهای مربوط به هر حالت، توزیع احتمال نهایی برای متغیر موردنظر بهدست میآید.
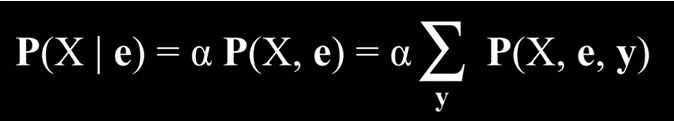
در این معادله، X نمایانگر متغیرِ پرسش (Query Variable)، e بیانگر شواهدِ مشاهدهشده، y مجموعهای از تمام مقادیر ممکنِ متغیرهای پنهان، و α عاملی برای نرمالسازی است تا در نهایت مجموع احتمالات برابر با ۱ شود.
بهبیان دیگر، این معادله بیان میکند که توزیع احتمال X با توجه به شواهد e، برابر است با نسخهٔ نرمالسازیشدهٔ توزیع احتمال مشترک X و e. برای محاسبهٔ این توزیع، لازم است احتمالِ مشترک X، e و y را ــ در حالی که در هر بار y یکی از مقادیر ممکن متغیرهای پنهان را میگیرد ــ با یکدیگر جمع کنیم. حاصل این جمع، پس از نرمالسازی توسط α، توزیعی قابلتعبیر و معتبر از نظر احتمالات خواهد بود.
در زبان پایتون کتابخانههای متعددی برای سادهسازی فرایند استنتاج احتمالاتی وجود دارد. یکی از این کتابخانهها pomegranate است که به کمک آن میتوان مدلهای احتمالاتی و شبکههای بیزی را با ساختاری روشن و قابلاستفاده نمایش داد.
برای آغاز کار، ابتدا باید گرهها را ایجاد کرده و برای هر یک توزیع احتمال مربوطه را مشخص کنیم.
from pomegranate import *
# Rain node has no parents
rain = Node(DiscreteDistribution({
"none": 0.7,
"light": 0.2,
"heavy": 0.1
}), name="rain")
# Track maintenance node is conditional on rain
maintenance = Node(ConditionalProbabilityTable([
["none", "yes", 0.4],
["none", "no", 0.6],
["light", "yes", 0.2],
["light", "no", 0.8],
["heavy", "yes", 0.1],
["heavy", "no", 0.9]
], [rain.distribution]), name="maintenance")
# Train node is conditional on rain and maintenance
train = Node(ConditionalProbabilityTable([
["none", "yes", "on time", 0.8],
["none", "yes", "delayed", 0.2],
["none", "no", "on time", 0.9],
["none", "no", "delayed", 0.1],
["light", "yes", "on time", 0.6],
["light", "yes", "delayed", 0.4],
["light", "no", "on time", 0.7],
["light", "no", "delayed", 0.3],
["heavy", "yes", "on time", 0.4],
["heavy", "yes", "delayed", 0.6],
["heavy", "no", "on time", 0.5],
7/23/25, 11:09 PM Lecture 2 - CS50's Introduction to Artificial Intelligence with Python
https://cs50.harvard.edu/ai/notes/2/ 14/24
["heavy", "no", "delayed", 0.5],
], [rain.distribution, maintenance.distribution]), name="train")
# Appointment node is conditional on train
appointment = Node(ConditionalProbabilityTable([
["on time", "attend", 0.9],
["on time", "miss", 0.1],
["delayed", "attend", 0.6],
["delayed", "miss", 0.4]
], [train.distribution]), name="appointment")
در مرحلهٔ دوم، مدل را با افزودن تمام گرهها ایجاد میکنیم و سپس با مشخص کردن اینکه کدام گره، والد گرهی دیگر است، یالهایی میان آنها اضافه میکنیم.
به یاد داشته باشید که شبکهٔ بیزی یک گراف جهتدار است؛ یعنی از گرههایی تشکیل شده که میان آنها پیکانهایی قرار دارد و این پیکانها رابطهٔ والد–فرزندی و وابستگیهای احتمالاتی را نشان میدهند.
# Create a Bayesian Network and add states
model = BayesianNetwork()
model.add_states(rain, maintenance, train, appointment)
# Add edges connecting nodes
model.add_edge(rain, maintenance)
model.add_edge(rain, train)
model.add_edge(maintenance, train)
model.add_edge(train, appointment)
# Finalize model
model.bake()
هوش مصنوعی CS50 s2
اکنون برای آنکه بسنجیم یک رویداد مشخص تا چه اندازه محتمل است، مدل را با مقادیری که به آنها علاقهمندیم اجرا میکنیم.
در این مثال، میخواهیم بدانیم احتمال همزمانِ رخ دادنِ چهار رویداد زیر چقدر است:
- بارشی وجود نداشته باشد،
- عملیات نگهداری خطوط انجام نشود،
- قطار به موقع برسد،
- و در نتیجه ما به جلسه برسیم.
با ارائهٔ این مقادیر به مدل، احتمال مشترک این ترکیب از رویدادها محاسبه میشود.
# Calculate probability for a given observation
probability = model.probability([["none", "no", "on time", "attend"]])
print(probability)
در غیر این صورت میتوانیم از برنامه بخواهیم توزیعهای احتمالی تمام متغیرها را با توجه به شواهد مشاهدهشده در اختیار ما بگذارد.
در نمونهٔ زیر، میدانیم که قطار با تأخیر رسیده است.
با داشتن این شاهد، مدل برای ما توزیع احتمالی سه متغیرِ Rain( بارش)،Maintenance (نگهداری خطوط)، و Appointment( حضور در قرار)را محاسبه و چاپ میکند.
هوش مصنوعی CS50 s2
# Calculate predictions based on the evidence that the train was delayed
predictions = model.predict_proba({
"train": "delayed"
})
# Print predictions for each node
for node, prediction in zip(model.states, predictions):
7/23/25, 11:09 PM Lecture 2 - CS50's Introduction to Artificial Intelligence with Python
https://cs50.harvard.edu/ai/notes/2/ 15/24
7/23/25, 11:09 PM
Lecture 2 - CS50's Introduction to Artificial Intelligence with Python
if isinstance(prediction, str):
print(f"{node.name}: {prediction}")
else:
print(f"{node.name}")
for value, probability in prediction.parameters[0].items():
print(f"
{value}: {probability:.4f}")
کدی که در بالا استفاده شد، از استنتاج از طریق شمارش (Inference by Enumeration) بهره میبرد.
با وجود دقت بالای این روش، برای مدلهایی که تعداد متغیرهای زیادی دارند بسیار ناکارآمد و زمانبر است؛ زیرا نیاز دارد تمام حالتهای ممکن را بررسی و مجموعگیری کند.
راهکار دیگر، صرفنظر کردن از استنتاج دقیق و استفاده از استنتاج تقریبی (Approximate Inference) است.
در این روش، اگرچه بخشی از دقت محاسبات از دست میرود، اما این میزان خطا معمولاً بسیار ناچیز است و در عمل تأثیری بر نتیجه نهایی نمیگذارد.
در مقابل، مزیت اصلی آن مقیاسپذیری و سرعت بسیار بالاتر است؛ بهگونهای که حتی برای شبکههای بزرگ و پیچیده نیز قابل استفاده و کارآمد میشود.
نمونهگیری (Sampling):
نمونهگیری یکی از مهمترین روشهای استنتاج تقریبی است. در این روش، برای هر متغیر یک مقدار بر اساس توزیع احتمال آن انتخاب میشود. ابتدا با مثالی خارج از درس شروع میکنیم و سپس نمونه ارائهشده در درس را توضیح میدهیم.
برای ایجاد یک توزیع با استفاده از نمونهگیری از یک تاس، میتوان تاس را چندصد بار پرتاب و نتیجهی هر بار را ثبت کرد. فرض کنید تاس را ۶۰۰ بار پرتاب کردهایم. انتظار داریم عدد ۱ تقریباً ۱۰۰ بار ظاهر شود، و همینطور سایر اعداد از ۲ تا ۶. سپس تعداد دفعات وقوع هر مقدار را بر عدد کل پرتابها تقسیم میکنیم. خروجی یک توزیع تقریبی خواهد بود؛ یعنی احتمالاً دقیقاً مقدار 1/61/61/6 برای هر عدد به دست نمیآید، اما مقادیری نزدیک به آن خواهیم داشت.
در مثال ارائهشده در درس، اگر نمونهگیری را از متغیر Rain آغاز کنیم، مقدار none با احتمال ۰.۷، مقدار light با احتمال ۰.۲، و مقدار heavy با احتمال ۰.۱ تولید میشود. فرض کنید نتیجهی نمونهگیری ما none باشد. حال که مقدار بارش را تعیین کردهایم، در مرحلهی نمونهگیری از متغیر Maintenance، تنها از توزیع احتمالیِ مربوط به حالتی نمونهگیری میکنیم که مقدار Rain برابر none است؛ زیرا این مقدار را از قبل تعیین کردهایم. این روند برای تمام گرهها ادامه پیدا میکند تا یک نمونه کامل تولید شود.
با تکرار این فرآیند، مجموعهای از نمونهها به دست میآید که میتوان از آنها برای برآورد احتمالات استفاده کرد. برای مثال، برای محاسبهی احتمالP(Train=on time) میتوان شمار نمونههایی را که در آنها متغیر Train مقدار on time گرفته است، بر تعداد کل نمونهها تقسیم کرد. این مقدار، برآوردی تقریبی از احتمال واقعی خواهد بود.
همچنین میتوان پرسشهای مربوط به احتمال شرطی را نیز پاسخ داد؛ مانند:P(Rain=light∣Train=on time)
در این حالت، ابتدا تمام نمونههایی را که در آنها Train مقدار on time ندارد کنار میگذاریم. سپس، در میان نمونههای باقیمانده، تعداد مواردی را که Rain برابر light است شمارش میکنیم و آن را بر تعداد کل نمونههای دارای Train = on time تقسیم میکنیم. نتیجه، یک تخمین تقریبی از احتمال شرطی مورد نظر است.
در کد، یک تابع نمونهگیری میتواند بهصورت تابعی مانند generate_sample پیادهسازی شود.
import pomegranate
from collections import Counter
from model import model
def generate_sample():
# Mapping of random variable name to sample generated
sample = {}
# Mapping of distribution to sample generated
parents = {}
# Loop over all states, assuming topological order
for state in model.states:
# If we have a non-root node, sample conditional on parents
if isinstance(state.distribution, pomegranate.ConditionalProbabilityTable):
sample[state.name] = state.distribution.sample(parent_values=parents)
# Otherwise, just sample from the distribution alone
else:
sample[state.name] = state.distribution.sample()
# Keep track of the sampled value in the parents mapping
parents[state.distribution] = sample[state.name]
# Return generated sample
return sample
اکنون برای محاسبهٔ P(Appointment | Train = delayed)، یعنی توزیع احتمال متغیر Appointment با فرض اینکه قطار با تأخیر رسیده است، به روش زیر عمل میکنیم:
# Rejection sampling
# Compute distribution of Appointment given that train is delayed
N = 10000
data = []
# Repeat sampling 10,000 times
for i in range(N):
# Generate a sample based on the function that we defined earlier
sample = generate_sample()
# If, in this sample, the variable of Train has the value delayed, save the sample
if sample["train"] == "delayed":
data.append(sample["appointment"])
# Count how many times each value of the variable appeared. We can later normalize by d
7/23/25, 11:09 PM Lecture 2 - CS50's Introduction to Artificial Intelligence with Python
https://cs50.harvard.edu/ai/notes/2/ 17/24
7/23/25, 11:09 PM
Lecture 2 - CS50's Introduction to Artificial Intelligence with Python
print(Counter(data))
وزندهی بر اساس درستنمایی (Likelihood Weighting)
هوش مصنوعی CS50 s2
در نمونهبرداریِ پیشین، نمونههایی را که با شواهد مشاهدهشده سازگار نبودند کنار میگذاشتیم. این روش کارآمد نیست. یکی از راههای رفع این مشکل، بهکارگیری Likelihood Weighting و طی کردن مراحل زیر است:
- ابتدا مقدار متغیرهای شواهد را ثابت نگه میداریم.
- سپس، سایر متغیرهایی را که در زمرهٔ شواهد قرار ندارند، بر اساس احتمالهای شرطی موجود در شبکهٔ بیزی نمونهبرداری میکنیم.
- در پایان، به هر نمونه وزنی متناسب با احتمال وقوع تمام شواهد اختصاص میدهیم.
برای نمونه، اگر مشاهده کرده باشیم که قطار سرِ وقت رسیده است، فرآیند نمونهبرداری را مانند قبل آغاز میکنیم. ابتدا از متغیر Rain بر اساس توزیع احتمال آن نمونه میگیریم، سپس از Maintenance نمونهبرداری میکنیم. اما هنگامی که به متغیر Train میرسیم، همیشه مقدار مشاهدهشده را برای آن قرار میدهیم؛ در این مثال، مقدار on time. سپس نمونهبرداری را ادامه میدهیم و مقدار متغیر Appointment را بر اساس توزیع احتمال آن با شرط Train = on time به دست میآوریم.
پس از ساخته شدن یک نمونهٔ کامل، آن را بر اساس احتمال شرطیِ متغیر مشاهدهشده نسبت به والدهای نمونهبرداریشدهٔ آن وزندهی میکنیم. به عنوان مثال، اگر در نمونهبرداری مقدار Rain = light و سپس Maintenance = yes حاصل شده باشد، وزن این نمونه برابر خواهد بود با:
P(Train = on time | light, yes)
مدلهای مارکوف (Markov Models):
تا اینجا، پرسشهای احتمالاتی را در شرایطی بررسی کردیم که تنها بر اساس اطلاعاتی انجام میشد که در همان لحظه مشاهده کرده بودیم. در چنین رویکردی، بُعد زمان نقشی ندارد. با این حال، بسیاری از مسائل—از جمله پیشبینی—بهطور مستقیم به عنصر زمان وابستهاند.
برای آنکه بتوانیم زمان را وارد مدل کنیم، متغیر جدیدی به نام X معرفی میکنیم و آن را تابعی از رخدادهای موردنظر در طول زمان قرار میدهیم؛ بهگونهای که Xₜ نشاندهندهٔ رخداد در زمان فعلی، Xₜ₊₁ رخداد در زمان بعد، و الی آخر باشد. برای پیشبینی وضعیت آینده، از مدلهای مارکوف بهره میبریم.
فرض مارکوف (Markov Assumption):
فرض مارکوف بیان میکند که وضعیت کنونی تنها به تعداد محدودی از وضعیتهای پیشین وابسته است. این فرض اهمیتی اساسی دارد.
برای مثال، در پیشبینی وضعیت هوا، در تئوری میتوان از دادههای یک سال گذشته برای پیشبینی هوای فردا استفاده کرد، اما:
- از نظر محاسباتی بسیار سنگین است،
- و از نظر علمی نیز بعید است که اطلاعات مربوط به ۳۶۵ روز پیش، تأثیر مشخصی بر احتمال وضعیت هوای فردا داشته باشد.
با بهکارگیری فرض مارکوف، تعداد وضعیتهای پیشین را محدود میکنیم—برای نمونه، تنها وضعیت یک روز قبل را در نظر میگیریم. این سادهسازی، مسئله را از نظر محاسباتی قابل حل میکند.
البته این کار میتواند موجب تخمینهای نسبتاً غیر دقیقتر شود، اما در بسیاری از کاربردها این میزان تقریب کاملاً قابل قبول است. علاوه بر این، با استفاده از مدل مارکوف میتوان بر اساس اطلاعات محدود، تخمینهای مؤثری از وضعیت آینده ارائه داد.
زنجیرهٔ مارکوف (Markov Chain):
مدل مارکوف را میتوان بر اساس اطلاعات مربوط به تنها یک رخداد پیشین نیز بهکار گرفت؛ برای مثال، پیشبینی هوای فردا بر اساس وضعیت هوای امروز.
زنجیرهٔ مارکوف دنبالهای از متغیرهای تصادفی است که توزیع هر متغیر در آن از فرض مارکوف تبعیت میکند. به بیان دیگر، هر رخداد در این دنباله تنها بر اساس احتمال رخدادِ قبل از خود تعیین میشود.
برای آغاز ساختن یک زنجیرهٔ مارکوف، نیازمند یک مدل انتقال هستیم؛ مدلی که مشخص میکند هر وضعیت بعدی با توجه به مقادیر احتمالی وضعیت کنونی، چه توزیع احتمالیای خواهد داشت.
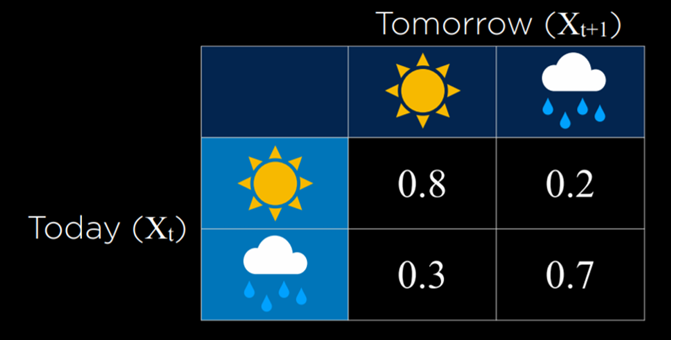
در این مثال،
احتمال آنکه فردا روزی آفتابی باشد، مشروط به آفتابی بودن امروز برابر با 0.8 است. این مقدار منطقی است، زیرا معمولاً احتمال ادامهی روزهای آفتابی بالاست. در مقابل، اگر امروز بارانی باشد، احتمال بارانی بودن فردا 0.7 است، چراکه روزهای بارانی نیز معمولاً پشت سر یکدیگر رخ میدهند.
با استفاده از این مدل انتقال میتوان یک زنجیرهٔ مارکوف نمونهبرداری کرد. بدین صورت که ابتدا روزی را ــ بارانی یا آفتابی ــ بهعنوان نقطهٔ شروع انتخاب میکنیم. سپس، روز بعد را بر اساس احتمال آفتابی یا بارانی بودن آن، با توجه به وضعیت روز آغازین، نمونهبرداری میکنیم. پس از آن، وضعیت روز سوم را با توجه به روز دوم بهدست میآوریم و این روند را ادامه میدهیم. نتیجهٔ این فرایند، شکلگیری یک زنجیرهٔ مارکوف خواهد بود.
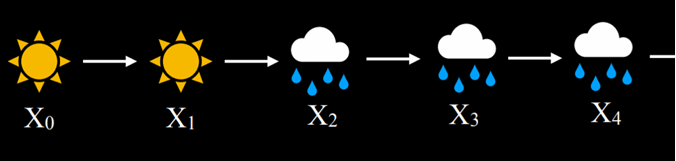
با در اختیار داشتن این زنجیرهٔ مارکوف، اکنون میتوانیم به پرسشهایی از این دست پاسخ دهیم: «احتمال آنکه چهار روز پیاپی بارانی باشد چقدر است؟»
برای نمونه، در ادامه قطعهکدی ارائه میشود که نشان میدهد چگونه میتوان یک زنجیرهٔ مارکوف را پیادهسازی کرد:
from pomegranate import *
# Define starting probabilities
start = DiscreteDistribution({
"sun": 0.5,
"rain": 0.5
})
# Define transition model
transitions = ConditionalProbabilityTable([
["sun", "sun", 0.8],
["sun", "rain", 0.2],
["rain", "sun", 0.3],
["rain", "rain", 0.7]
], [start])
# Create Markov chain
model = MarkovChain([start, transitions])
# Sample 50 states from chain
print(model.sample(50))
مدلهای مارکوف پنهان:
هوش مصنوعی CS50 s2
مدل مارکوف پنهان نوعی مدل مارکوف است که در آن، وضعیتهای واقعیِ سامانه پنهاناند و تنها رخدادهایی قابل مشاهده تولید میکنند. به بیان دیگر، هوش مصنوعی در چنین شرایطی تنها به برخی اندازهگیریها یا نشانهها از جهان دسترسی دارد، اما نمیتواند وضعیت واقعی و دقیق محیط را مستقیماً مشاهده کند. در این حالت، وضعیت واقعی حالت پنهان نام دارد و دادههایی که سامانه مشاهده میکند مشاهدات نامیده میشوند. نمونههایی از چنین موقعیتها عبارتاند از:
- برای یک رباتی که در محیط ناشناخته حرکت میکند، حالت پنهان «موقعیت واقعی ربات» است و مشاهدات همان دادههایی است که حسگرهای ربات ثبت میکنند.
- در تشخیص گفتار، حالت پنهان «واژگانِ اداشده» است، در حالی که مشاهده، «موج صوتی» دریافتشده است.
- هنگام اندازهگیری میزان تعامل کاربران در وبسایتها، حالت پنهان «میزان واقعی درگیری یا مشارکت کاربر» است و مشاهده همان دادههای تحلیلیِ ثبتشده در وبسایت یا اپلیکیشن است.
برای بحث خود، از نمونهای ساده استفاده میکنیم: سامانهٔ هوشمند ما میخواهد وضعیت هوا را (که یک حالت پنهان است) استنباط کند، اما تنها دادهٔ موجود از یک دوربین داخلی به دست میآید که مشخص میکند چند نفر با چتر وارد ساختمان شدهاند. در اینجا، مدل حسگر یا مدل گسیلاحتمال دیدن هر مشاهده را بر اساس حالت واقعی هوا نشان میدهد.

در این مدل، اگر هوا آفتابی باشد، احتمال آنکه افراد با چتر وارد ساختمان شوند بسیار کم است. اما اگر هوا بارانی باشد، اغلب افراد با چتر به ساختمان خواهند آمد. بنابراین با مشاهدهٔ اینکه افراد چتر همراه داشتهاند یا نه، میتوان با احتمال قابل قبولی وضعیت واقعی هوا را پیشبینی کرد.
فرض مارکوف در حسگرها:
این فرض بیان میکند که متغیر شواهد تنها به وضعیت متناظر خود وابسته است. برای مثال، در مدل ما فرض میشود که همراه داشتن چتر تنها به وضعیت آبوهوا بستگی دارد. البته این فرض همیشه کاملاً مطابق واقعیت نیست؛ زیرا ممکن است برخی افراد، به دلیل عادت یا شخصیت احتیاطگرای خود، حتی در روزهای آفتابی نیز چتر به همراه داشته باشند. اگر دادههایی در مورد رفتار یا شخصیت افراد داشتیم، میتوانستیم مدل را دقیقتر کنیم. با این حال، فرض مارکوف در حسگرها این پیچیدگیها را نادیده میگیرد و تنها «حالت پنهان» را تعیینکنندهٔ مشاهده میداند.
ساختار مدل مارکوف پنهان:
مدل مارکوف پنهان را میتوان بهصورت یک زنجیرهٔ مارکوف با دو لایه نمایش داد.
- لایهٔ بالا، متغیر X، نشاندهندهٔ حالت پنهان است.
- لایهٔ پایین، متغیر E, بیانگر شواهد یا همان مشاهداتی است که در اختیار داریم.
این ساختار به ما اجازه میدهد با استفاده از توالی مشاهدات، احتمال وضعیتهای پنهان را تخمین بزنیم.
هوش مصنوعی CS50 s2
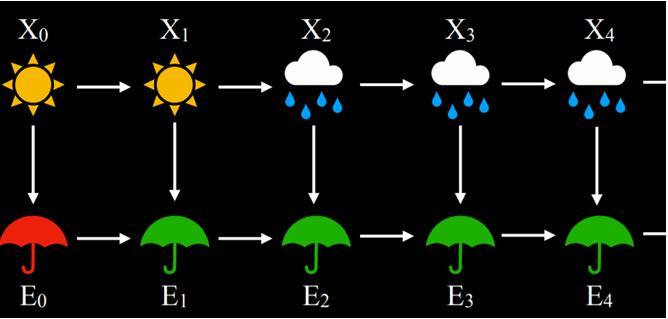
بر اساس مدلهای مارکوف پنهان، میتوان مجموعهای از وظایف تحلیلی را انجام داد:
- پالایش (Filtering): با در اختیار داشتن مشاهدات از ابتدای زمان تا لحظهٔ فعلی، احتمال هر یک از وضعیتهای کنونی محاسبه میشود. برای نمونه، اگر بدانیم مردم از ابتدا تا امروز در چه زمانهایی با چتر وارد ساختمان شدهاند، میتوانیم احتمال بارانی بودن امروز را برآورد کنیم.
- پیشبینی (Prediction): با استفاده از مشاهدات گذشته تا زمان حال، احتمال وضعیتهایی که در آینده رخ خواهند داد تعیین میشود.
- هموارسازی (Smoothing): بر پایهٔ مشاهدات از ابتدا تا زمان کنونی، احتمال وضعیتهایی در گذشته محاسبه میشود. برای مثال، میتوان احتمال بارانی بودن روز گذشته را، با توجه به اینکه افراد امروز با چتر حضور یافتهاند، به دست آورد.
- محتملترین تبیین (Most Likely Explanation): با استفاده از مجموعهٔ مشاهدات گذشته تا اکنون، محتملترین دنبالهٔ وضعیتها استنتاج میشود.
کاربرد مهم بخش اخیر، یعنی یافتن محتملترین تبیین، در حوزههایی مانند تشخیص گفتار است؛ جایی که سامانهٔ هوشمند با تحلیل مجموعهای از سیگنالهای صوتی، محتملترین توالی از واژهها یا هجاهایی را که منجر به تولید این سیگنالها شدهاند بازسازی میکند.
در ادامه، پیادهسازی پایتونی یک مدل مارکوف پنهان ارائه میشود که برای انجام وظیفهٔ یافتن محتملترین تبیین مورد استفاده قرار خواهد گرفت.
from pomegranate import *
# Observation model for each state
sun = DiscreteDistribution({
"umbrella": 0.2,
"no umbrella": 0.8
})
rain = DiscreteDistribution({
"umbrella": 0.9,
22/24
https://cs50.harvard.edu/ai/notes/2/
"no umbrella": 0.1
})
states = [sun, rain]
# Transition model
transitions = numpy.array(
[[0.8, 0.2], # Tomorrow's predictions if today = sun
[0.3, 0.7]] # Tomorrow's predictions if today = rain
)
# Starting probabilities
starts = numpy.array([0.5, 0.5])
# Create the model
model = HiddenMarkovModel.from_matrix(
transitions, states, starts,
state_names=["sun", "rain"]
)
model.bake()
هوش مصنوعی CS50 s2
توجه کنید که مدل ما شامل مدل انتقال و مدل حسگر است. وجود هر دو بخش برای تشکیل یک مدل مارکوف پنهان ضروری است. در قطعهکد زیر، دنبالهای از مشاهداتِ مربوط به اینکه آیا افراد با چتر وارد ساختمان شدهاند یا نه ارائه میشود. بر اساس این دنبالهٔ مشاهدات، مدل اجرا میشود و محتملترین تبیین را ــ یعنی توالی آبوهوا که بیشترین احتمال را دارد این الگوی مشاهدهشده را ایجاد کرده باشد ــ محاسبه و چاپ میکند.
from model import model
# Observed data
observations = [
"umbrella",
"umbrella",
"no umbrella",
"umbrella",
"umbrella",
"umbrella",
"umbrella",
"no umbrella",
"no umbrella"
]
# Predict underlying states
predictions = model.predict(observations)
for prediction in predictions:
print(model.states[prediction].name)
هوش مصنوعی CS50 s2
در این مثال، خروجی برنامه چنین خواهد بود:
rain, rain, sun, rain, rain, rain, rain, sun, sun
این خروجی نشان میدهد که محتملترین الگوی آبوهوا، با توجه به مشاهدات ما دربارهٔ اینکه افراد با چتر وارد ساختمان شدهاند یا نه، چگونه بوده است. به بیان دیگر، مدل بر اساس دنبالهٔ مشاهدات، این توالی را بهعنوان محتملترین روند تغییرات هوا در آن بازهٔ زمانی استنتاج کرده است.
خلاصه:
این فصل به بررسی نقش احتمال و مدلهای آماری در هوش مصنوعی میپردازد؛ ابزاری که برای تصمیمگیری در شرایط عدم قطعیت استفاده میشود. ابتدا مفاهیم بنیادین احتمال معرفی میشود؛ از جمله جهانهای ممکن، احتمال شرطی، قانون بیز، متغیرهای تصادفی و احتمال مشترک. این مفاهیم پایه، چارچوبی برای تحلیل رویدادهایی فراهم میکنند که اطلاعات دربارهٔ آنها ناقص یا مبهم است.
در ادامه، شبکههای بیزی بهعنوان ساختاری قدرتمند برای نمایش وابستگیها میان متغیرها مورد بررسی قرار میگیرد. این شبکهها با استفاده از گرهها و روابط جهتدار، نشان میدهند که چگونه رخدادهای مختلف بر یکدیگر اثر میگذارند. روشهای استنتاج در شبکههای بیزی شامل استنتاج دقیق با شمارش و روشهای تقریبی مانند نمونهبرداری و وزندهی بر اساس شباهت، فرصت محاسبهٔ احتمال متغیرهای ناشناخته را فراهم میسازند.
سپس مدلهای مارکوف معرفی میشوند که برای نمایش پدیدههای وابسته به گذر زمان مناسباند. این مدلها بر فرض مارکوف تکیه دارند، مبنی بر اینکه وضعیت فعلی تنها به وضعیتهای اخیر وابسته است. زنجیرههای مارکوف امکان پیشبینی در دنبالهٔ زمانی را فراهم میکنند و پایهای برای مدلهای پیچیدهتر هستند.
در بخش پایانی، مدلهای مارکوف پنهان (HMM) بررسی میشوند؛ مدلهایی که در آنها وضعیت واقعیِ سیستم قابل مشاهده نیست و تنها نشانههایی از آن ثبت میشود. با کمک مدلهای حسگر و مدل انتقال، میتوان از روی مشاهدات، وضعیتهای پنهان را تخمین زد. وظایف کلیدی این مدل شامل فیلتر کردن، پیشبینی، هموارسازی و یافتن محتملترین دنبالهٔ رویدادهاست. در نهایت، نمونهای از پیادهسازی HMM در پایتون ارائه میشود که از روی الگوی دیدهشدن چترها، توالی احتمالی وضعیت آبوهوا را استنتاج میکند.
این فصل نشان میدهد که چگونه احتمال، شبکههای بیزی و مدلهای مارکوف ابزارهایی بنیادی برای تحلیل دادههای ناقص و اتخاذ تصمیمهای هوشمندانه در سامانههای مبتنی بر هوش مصنوعی هستند.

دیدگاهتان را بنویسید