

هوش مصنوعی
دوره هوش مصنوعی
آموزش هوش مصنوعی
دوره کامل آموزش هوش مصنوعی بر مبنای دوره CS5 دانشگاه هاروارد به عنوان معتبرترین و جامع ترین دوره آموزش مقدماتی و مفهومی هوش مصنوعی شناخته می شود.
این دوره به بررسی دقیق و عمیق مباحث هوش مصنوعی به صورت پایه ای می پردازد و شامل 7 بخش میباشد .جهت دسترسی به سایر دوره ها می توانید از لینک های زیر استفاده نمایید.
و برای مشاهده لیست تمام دوره ها به بخش مقالات مراجه نمایید.
CS50’s Introduction to Artificial Intelligence with Python
Danix Ai
فهرست مطالب:
- مقدمه ای بر هوش مصنوعی
- مفاهیم پایه جستوجو هوش مصنوعی
- حل مسئله با جستوجو هوش مصنوعی
- مثال عملی: یافتن مسیر در یک گراف ساده
- الگوریتمهای جستوجوی بدوناطلاع
- جستوجوی آگاهانه (Informed Search)
- الگوریتم A*
- جستوجوی خصمانه (Adversarial Search)
- بهینهسازی Minimax
- نمونهکد پایتون: پیادهسازی Tic-Tac-Toe با Minimax
مقدمه هوش مصنوعی:
هوش مصنوعی (Artificial Intelligence) یکی از مهمترین و تأثیرگذارترین حوزههای علم رایانه است که به سرعت در حال گسترش بوده و نقش آن در زندگی روزمره انسانها غیرقابلانکار شده است. از سیستمهای توصیهگر شبکههای اجتماعی و موتورهای جستوجو گرفته تا مسیریابها، رباتها و حتی بازیهای رایانهای، همگی از مفاهیم و الگوریتمهایی استفاده میکنند که بنیان هوش مصنوعی را تشکیل میدهند.
درک صحیح این مفاهیم پایهای، نخستین گام در مسیر یادگیری عمیقتر و توسعهٔ سیستمهای هوشمند است. در این مجموعه، مفاهیم کلیدی مانند جستوجو، نمایش دانش، عدم قطعیت، بهینهسازی، یادگیری ماشین و شبکههای عصبی بررسی میشوند. همچنین با الگوریتمهای پایهای در هوش مصنوعی ، جستوجو شامل DFS و BFS، روشهای آگاهانه مانند Greedy و A*، و نیز الگوریتمهای جستوجوی خصمانه همچون Minimax و Alpha-Beta Pruning آشنا میشویم.
هدف این نوشته، ارائهٔ یک دید جامع و قابلفهم از سازوکارهای اصلی هوش مصنوعی است تا خواننده بتواند با دانش کافی وارد مباحث عملیتر و پیچیدهتر شود. امیدواریم این مجموعه بتواند بهعنوان نقطهٔ شروعی اثربخش در مسیر یادگیری هوش مصنوعی مورد استفاده قرار گیرد.
هوش مصنوعی (AI):
هوش مصنوعی مجموعهای از تکنیکها را در بر میگیرد که باعث میشوند رفتار رایانه بهصورت هوشمند یا شبیه به موجودات ذیشعور ظاهر شود. برای مثال، هوش مصنوعی برای تشخیص چهره در عکسهای شبکههای اجتماعی، شکست دادن قهرمان جهان در شطرنج، و پردازش گفتار شما هنگام صحبت با سیری یا الکسا در تلفن همراهتان به کار میرود.
در این درس، ما با برخی از مفاهیمی که هوش مصنوعی را ممکن میسازند آشنا میشویم:
مفاهیم پایه هوش مصنوعی در این درس عبارتند از:
-
جستوجو در هوش مصنوعی
یافتن راهحل برای یک مسئله؛ مانند برنامههای مسیریاب که بهترین مسیر از مبدأ تا مقصد را پیدا میکنند، یا بازیهایی که باید در آنها بهترین حرکت بعدی تعیین شود.
-
دانش هوش مصنوعی
نمایش اطلاعات و استنتاج نتیجه از آن.
-
عدم قطعیت هوش مصنوعی
پرداختن به رویدادهای نامطمئن با استفاده از مفاهیم احتمال.
-
بهینهسازی هوش مصنوعی
یافتن نهتنها یک راه درست برای حل مسئله، بلکه راهی بهتر—یا بهترین راه ممکن.
-
یادگیری هوش مصنوعی
بهبود عملکرد با استفاده از دادهها و تجربه. برای مثال، سرویس ایمیل شما میتواند براساس تجربهٔ قبلی، ایمیلهای اسپم را از غیر اسپم تشخیص دهد.
-
شبکههای عصبی
ساختاری برنامهنویسیشده که از مغز انسان الهامگرفته و توانایی انجام مؤثر بسیاری از وظایف مختلف را دارد.
-
زبان
پردازش زبان طبیعی که توسط انسان تولید و درک میشود.
جستوجو:
مسائل جستوجو شامل عاملی هستند که یک «وضعیت اولیه» و یک «وضعیت هدف» دریافت میکند و راهحلی برای حرکت از وضعیت اولیه به وضعیت هدف ارائه میدهد. برنامههای مسیریاب از یک فرایند جستوجوی معمول استفاده میکنند؛ جایی که عامل (بخش تصمیمگیرنده برنامه) موقعیت فعلی و مقصد موردنظر شما را به عنوان ورودی دریافت کرده و براساس الگوریتم جستوجو، بهترین مسیر را پیشنهاد میدهد.
با این حال، انواع بسیار دیگری از مسائل جستوجو نیز وجود دارند؛ مانند حل پازلها یا عبور از مارپیچها.

-
عامل (Agent)
موجودیتی که محیط خود را ادراک میکند و بر آن اثر میگذارد. برای مثال، در یک برنامهٔ مسیریاب، عامل نمایشی از یک خودرو است که باید تصمیم بگیرد چه اقداماتی انجام دهد تا به مقصد برسد.
-
حالت (State)
یک پیکربندی یا وضعیت از عامل در محیط آن.
برای نمونه، در پازل ۱۵تایی، هر نحوهٔ چیدمان اعداد روی صفحه یک «حالت» محسوب میشود.
-
حالت اولیه (Initial State)
حالتی که الگوریتم جستوجو از آن آغاز میشود.
در یک برنامهٔ مسیریاب، حالت اولیه همان موقعیت فعلی شماست.
-
کنشها (Actions)
انتخابهایی که در یک حالت قابل انجام هستند.
بهطور دقیقتر، «عمل» تابعی است که با دریافت حالت s بهعنوان ورودی، مجموعهٔ تمام اقداماتی را بازمیگرداند که در آن حالت قابل اجرا هستند.
مثلاً در پازل ۱۵تایی، کنشهای یک حالت شامل روشهایی است که میتوان در آن چیدمان، مربعها را جابهجا کرد (۴ حرکت اگر خانهی خالی درمرکز باشد، ۳ حرکت اگر کنار لبه باشد، و ۲ حرکت اگر در گوشه قرار گرفته باشد).
-
مدل گذار (Transition Model)
توصیفی از اینکه اجرای هر کنش در هر حالت، چه حالت جدیدی را ایجاد میکند.
به بیان دقیقتر، مدل گذار تابعی است که با گرفتن حالت s و عمل a به عنوان ورودی، حالت جدیدی را بازمیگرداند که از انجام عمل a در حالت s حاصل میشود.
برای مثال، در یک پیکربندی مشخص از پازل ۱۵تایی، جابهجایی یک مربع در جهتی خاص، پیکربندی جدیدی از پازل ایجاد میکند.
-
فضای حالت (State Space)
مجموعهٔ تمام حالتهایی که از حالت اولیه و با انجام هر دنبالهای از کنشها قابل دستیابی هستند.
مثلاً در پازل ۱۵تایی، فضای حالت شامل همهٔ پیکربندیهای ممکن (برابر با !16/2 حالت) است که از هر حالت اولیه میتوان به آنها رسید.
فضای حالت را میتوان مانند یک گراف جهتدار در نظر گرفت که در آن، «حالتها» به عنوان گره و «کنشها» به عنوان یالهایی از یک گره به گرهٔ دیگر نمایش داده میشوند.
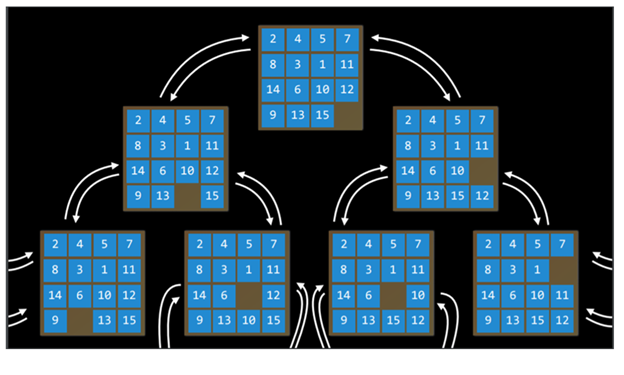
آزمون هدف (Goal Test)
شرطی که تعیین میکند آیا یک حالت مشخص، «حالت هدف» است یا نه.
مثلاً در یک برنامهٔ مسیریاب، آزمون هدف بررسی میکند که آیا موقعیت فعلی عامل (نمایش خودرو) همان مقصد است یا خیر. اگر باشد — مسئله حل شده است؛ اگر نباشد — جستوجو ادامه مییابد.
هزینهٔ مسیر (Path Cost)
یک مقدار عددی که به یک مسیر نسبت داده میشود.
بهعنوان مثال، یک مسیریاب فقط شما را به مقصد نمیرساند؛ بلکه تلاش میکند با کمینهکردن هزینهٔ مسیر، سریعترین راه ممکن را بیابد.
حل مسئلهٔ جستوجو
راهحل (Solution)
دنبالهای از کنشها که از حالت اولیه به حالت هدف میرسد.
راهحل بهینه (Optimal Solution)
راهحلی که کمترین هزینهٔ مسیر را در میان تمام راهحلها دارد.
در فرایند جستوجو، دادهها معمولاً در گرهها (Node) ذخیره میشوند؛ هر گره شامل اطلاعات زیر است:
- یک حالت
- گرهٔ والد، یعنی گرهای که گرهٔ فعلی از آن ایجاد شده است
- کنشی که روی حالت والد اعمال شده تا به حالت فعلی برسیم
- هزینهٔ مسیر از حالت اولیه تا این گره
گرهها اطلاعاتی را نگه میدارند که آنها را برای الگوریتمهای جستوجو بسیار ارزشمند میکند. هر گره شامل یک «حالت» است که میتوان آن را با آزمون هدف بررسی کرد تا ببینیم آیا حالت نهایی است یا خیر. اگر حالت هدف باشد، هزینهٔ مسیر آن گره با سایر گرهها مقایسه میشود تا بهترین راهحل انتخاب شود.
همچنین با ذخیرهکردن گرهٔ والد و کنشی که به گرهٔ فعلی منتهی شده، میتوان تمام مسیر را از حالت اولیه تا گرهٔ هدف دنبال کرد — و این دنبالهٔ کنشها همان «راهحل» است.
با این حال، گرهها فقط ساختارهای داده هستند — خودشان جستوجو انجام نمیدهند، بلکه صرفاً اطلاعات را نگه میدارند. برای انجام واقعی جستوجو، از مرز (Frontier) استفاده میکنیم؛ سازوکاری که گرهها را «مدیریت» میکند.
مرز ابتدا با یک حالت اولیه و یک مجموعهٔ خالی از حالتهای بررسیشده آغاز میشود و تا زمانی که راهحل پیدا شود این مراحل را تکرار میکند:
مراحل تکراری جستوجو
- اگر مرز خالی باشد:
- متوقف شو. راهحلی برای مسئله وجود ندارد.
- یک گره از مرز خارج کن — این گره همان گرهای است که قرار است بررسی شود.
- اگر این گره شامل حالت هدف باشد:
- راهحل را برگردان و متوقف شو.
- در غیر این صورت:
- گره را بسط بده (تمام گرههای جدیدی که میتوان از آن رسید را پیدا کن.)
- گرهٔ فعلی را به مجموعهٔ «بررسیشدهها» اضافه کن.
مثال: پیدا کردن مسیر در یک نقشهٔ ساده
فرض کنید یک ربات باید از نقطهٔ A به نقطهٔ D برسد.
نقشهٔ محیط به شکل زیر است:

مفروضات هزینهٔ حرکتها:
- A → B : هزینه 1
- A → C : هزینه 4
- B → D : هزینه 2
- C → D : هزینه 1
تعریف اجزای مسئلهٔ جستوجو
حالتها (States)
A, B, C, D
(موقعیت فعلی ربات)
حالت اولیه (Initial State)
A
(ربات از نقطهٔ A شروع میکند)
حالت هدف (Goal Test)
هدف: ربات در نقطهٔ D باشد.
یعنی:
Goal-Test(s) : (s == D ? True : False)
کنشها (Actions)
در هر نقطه، ربات میتواند به نقاط متصل حرکت کند.
مثلاً:
- Actions(A) = {move to B , move to C}
- Actions(B) = {move to A , move to D}
- Actions(C) = {move to A , move to D}
مدل گذار (Transition Model)
به ازای هر حرکت، ربات به نقطهٔ بعدی میرود.
مثلاً:
Result(A , move to B) = B
Result(B , move to D) = D
هزینهٔ مسیر (Path Cost)
جمع هزینههای حرکت
مثلاً مسیر A → B → D
برابر است با:
1 + 2 = 3
فرایند جستوجو با استفاده از مرز (Frontier):
مرحله ۱ — شروع
مرز = { گره(A) }
بررسیشده = ∅
مرحله ۲ — برداشتن گره A
آیا A حالت هدف است؟
❌ خیر
بسط (Expand) A
دو گرهٔ جدید : از A میتوان به B و C رفت:
- گره(B) با هزینهٔ 1
- گره(C) با هزینهٔ 4
مرز = { B , C }
بررسیشده = { A }
مرحله ۳ — برداشتن گره B
(فرض کنیم الگوریتم BFS یا UCS باشد)
آیا B حالت هدف است؟
❌ خیر
بسط B
از B میتوان به A و D رفت:
- A قبلاً بررسی شده : رد
- D یک گرهٔ جدید : با هزینهٔ 1+2 =3
مرز = { C , D }
بررسیشده = { A , B }
مرحله ۴ — برداشتن گره D
آیا D حالت هدف است؟
✔ بله!
پس جستوجو متوقف میشود
بازسازی راهحل (Solution Reconstruction):
گره D : والد آن گره B
گره B : والد آن گره A
پس مسیر به صورت معکوس:
D ← B ← A
و مسیر نهایی:
راه حل : A → B → D
هزینهٔ مسیر: 3
جمعبندی مثال:
| مقدار در مثال | مفهوم |
| A | حالت اولیه |
| D | حالت هدف |
| حرکت به نقاط همسایه | کنشها |
| رسیدن به گرهٔ جدید بعد از حرکت | مدل گذار |
| مجموع هزینهٔ لبهها | هزینهٔ مسیر |
| شامل حالت، والد، کنش، هزینهٔ مسیر | گره |
| مجموعهٔ گرههای آمادهٔ بررسی | مرز |
| A → B → D | راهحل |
| بله (کمترین هزینه = 3) | راهحل بهینه |
جستوجوی عمقی (Depth-First Search):
در توضیح قبلی دربارهٔ «مرز جستوجو» (frontier)، یک نکته گفته نشد. در مرحلهٔ ۲ شبهکد، باید مشخص شود که کدام گره باید حذف شود. این انتخاب بر کیفیتِ راهحل و سرعت رسیدن به آن تأثیر دارد. راههای مختلفی برای تعیین اینکه کدام گرهها باید زودتر بررسی شوند وجود دارد؛ دو روش مهم با استفاده از ساختارهای دادهٔ پشته (در جستوجوی عمقی) و صف (در جستوجوی سطحی) مشخص میشوند.
(ویدئویی کوتاه و بامزه هم وجود دارد که تفاوت این دو روش را نشان میدهد.)
در اینجا با روش جستوجوی عمقی (DFS) شروع میکنیم.
الگوریتم DFS در یک مسیر تا حد ممکن به عمق پیش میرود و تنها زمانی که آن مسیر کاملاً بررسی شد، به مسیرهای دیگر میپردازد. در این روش، مرز جستوجو به شکل پشته مدیریت میشود. جملهٔ کلیدی برای بهخاطر سپردن این روش «آخرین ورودی، اولین خروجی» است. یعنی بعد از اضافه شدن گرهها به پشته، گرهای که اول بررسی میشود همان گرهای است که آخر اضافه شده است.
این رفتار باعث میشود الگوریتم تا جایی که بتواند در اولین مسیر موجود فرو برود و بررسی مسیرهای دیگر را برای بعد بگذارد.
(یک مثال بیرون از کلاس: فرض کنید دنبال کلیدهای خود میگردید. در روش DFS، اگر تصمیم بگیرید ابتدا شلوار خود را بگردید، هر جیب را کامل خالی میکنید و با دقت بررسی میکنید. فقط زمانی سراغ جای دیگری میروید که همهٔ جیبهای شلوار را کاملاً بررسی کرده باشید.)
مزایا
- در بهترین حالت، این الگوریتم سریعترین است. اگر «شانس بیاورد» و همیشه مسیر درست را انتخاب کند، کمترین زمان ممکن را برای رسیدن به جواب نیاز خواهد داشت.
معایب
- ممکن است راهحلی که پیدا میکند، بهینه نباشد.
- در بدترین حالت، باید همهٔ مسیرهای ممکن را بررسی کند تا به جواب برسد، و در نتیجه بیشترین زمان ممکن را صرف خواهد کرد.
• def remove(self):
• # اگر frontier خالی باشد، جستوجو باید پایان یابد
• if self.empty():
• raise Exception("empty frontier")
• # آخرین گره اضافهشده (رفتار پشته: LIFO)
• node = self.frontier[-1]
• # حذف آخرین گره از frontier
• self.frontier = self.frontier[:-1]
• return node
هوش مصنوعی
جستوجوی سطحی (Breadth-First Search):
برخلاف جستوجوی عمقی، جستوجوی سطحی یا BFS عمل میکند.
در الگوریتم BFS، جستوجو بهصورت همزمان چند مسیر را دنبال میکند؛ یعنی ابتدا یک قدم در تمام مسیرهای ممکن برداشته میشود، سپس قدم دوم در همهٔ مسیرها، و همینطور ادامه پیدا میکند.در این روش، مرز جستوجو با استفاده از ساختار دادهٔ صف مدیریت میشود. جملهٔ کلیدی برای بهخاطر سپردن این روش «اول وارد، اول خارج» (First-In First-Out) است.
به این ترتیب، همهٔ گرههای جدید پشت سر هم در صف قرار میگیرند و بر اساس ترتیب ورود، یکییکی بررسی میشوند. نتیجه این است که الگوریتم، در تمام مسیرهای ممکن ابتدا یک قدم جلو میرود، قبل از اینکه در هر مسیر قدم دوم بردارد.
(یک مثال روزمره: فرض کنید دنبال کلید خود میگردید. در این روش، اگر با شلوار خود شروع کنید، ابتدا جیب راست را نگاه میکنید. اما بهجای اینکه فوراً جیب چپ را بگردید، ابتدا سراغ یک کشو میروید، سپس روی میز را نگاه میکنید، و همینطور تکتک مکانهای دیگر را بررسی میکنید. فقط وقتی همهٔ مکانهای مختلف را یک بار بررسی کردید، دوباره به سراغ شلوار رفته و جیب بعدی را میگردید.)
مزایا
- این الگوریتم تضمین میکند که بهترین (بهینهترین) راهحل را پیدا کند.
معایب
- تقریباً همیشه بیشتر از حداقل زمان ممکن طول میکشد.
- در بدترین حالت، بیشترین زمان ممکن را برای اجرا نیاز خواهد داشت.
• def remove(self):
• # اگر frontier خالی باشد، جستوجو پایان مییابد
• if self.empty():
• raise Exception("empty frontier")
•
• # قدیمیترین گره (اولین گره اضافهشده) - رفتار صف: FIFO
• node = self.frontier[0]
•
• # حذف اولین گره از frontier
• self.frontier = self.frontier[1:]
•
• return node
BFS VC DFS
| BFS (جستوجوی سطحی) | DFS (جستوجوی عمقی) | ویژگی |
| صف (Queue) – FIFO | پشته (Stack) – LIFO | ساختار دادهٔ مورد استفاده |
| پیشروی یک قدم درمیان در تمام مسیرهای ممکن | رفتن تا عمیقترین نقطهٔ ممکن در یک مسیر، سپس مسیر بعد | نحوهٔ پیشروی در مسیرها |
| همزمان همهٔ مسیرها را پیش میبرد | یک مسیر را کامل میکاود و بعد مسیرهای دیگر | رفتار جستوجو |
| تضمینی است (کوتاهترین مسیر را مییابد) | تضمینی نیست | بهینه بودن راهحل |
| کندتر از DFS | بسیار سریع؛ اگر تصادفاً مسیر درست را انتخاب کند | سرعت (بهترین حالت) |
| بسیار کند؛ ممکن است همهٔ مسیرها را جستوجو کند | بسیار کند؛ ممکن است همهٔ مسیرها را جستوجو کند | سرعت (بدترین حالت) |
| زیاد، چون باید همهٔ گرههای سطح فعلی را نگه دارد | کمتر، چون یک مسیر را دنبال میکند | مصرف حافظه |
| پیدا کردن کوتاهترین مسیر، گرافهای بدون وزن | حل مسائل با عمق زیاد، پیمایش درختها، پازلها | کاربردهای معمول |
نمودار تصویریِ تفاوت جستو جوی عمقی و سطحی:

BFS (جستوجوی سطحی)
در الگوریتم BFS گرهها را بهصورت سطحبهسطح بررسی میکنیم.
در ابتدا گره A در سطح صفر قرار دارد.
پس از آن، گرههای B، C و D در سطح اول بررسی میشوند.
در مرحله بعد، گرههای E، F و G که در سطح دوم قرار دارند مورد بررسی قرار میگیرند.
ترتیب بازدید گرهها به شکل زیر است:
A → B → C → D → E → F → G
DFS (جستوجوی عمقی)
در روش DFS الگوریتم ابتدا یک مسیر را تا انتها دنبال میکند.
برای مثال، اگر از شاخه چپ حرکت کنیم، مسیر زیر طی میشود:
A → B → E
وقتی الگوریتم به E میرسد و مسیر جدیدی پیدا نمیکند، به گره قبلی بازمیگردد و F را بررسی میکند. سپس به ریشه برمیگردد و شاخههای C و D را دنبال میکند تا در نهایت به G برسد.
یکی از ترتیبهای ممکن برای DFS به صورت زیر است:
A → B → E → F → C → D → G
(توجه: ترتیب دقیق اجرای DFS به نحوه چینش یالها بستگی دارد.)
مثال روشن از زندگی واقعی
فرض کن دنبال کلیدت هستی. اگر از شلوارت شروع کنی:
- جیب راست → کامل بگرد
- جیب چپ → کامل بگرد
- جیب عقب → کامل بگرد
تا وقتی شلوارت را کامل جستوجو نکنی، سراغ جای دیگری نمیروی.
- یک نگاه سریع در جیب راست
- بعد یک نگاه در کشو
- بعد روی میز
- بعد داخل کیف
- بعد جیب چپ
- بعد جیب عقب
همهٔ مکانها را یکبار سریع بررسی میکنی قبل از اینکه دوباره به هر کدام برگردی.
جستوجوی حریصانهٔ بهتریناول (Greedy Best-First Search):
جستوجوی سطحی (BFS) و جستوجوی عمقی (DFS) هر دو الگوریتمهای جستوجوی بدوناطلاع هستند؛ یعنی از هیچ دانشی دربارهٔ مسئله استفاده نمیکنند مگر دانشی که خودشان در حین جستوجو به دست آوردهاند.
اما در بسیاری از مسائل، معمولاً دانشی اولیه دربارهٔ مسئله در دسترس است.
مثلاً وقتی یک انسان داخل یک ماز یا هزارتو حرکت میکند، هنگام رسیدن به یک دوراهی میتواند ببیند کدام مسیر بهطور کلی به سمت هدف میرود و کدام مسیر دور میشود. هوش مصنوعی هم میتواند از همین نوع اطلاعات استفاده کند.
به الگوریتمهایی که از این نوع اطلاعات اضافه استفاده میکنند تا عملکردشان را بهتر کنند، الگوریتمهای جستوجوی آگاهانه (Informed Search) گفته میشود.
Greedy Best-First Search چگونه کار میکند؟
در این روش، الگوریتم گرهای را گسترش میدهد که بهنظر میرسد به هدف نزدیکتر است؛
این «نزدیکی» توسط یک تابع تخمینی به نام تابع هیوریستیک (h(n)) سنجیده میشود.
این تابع حدس میزند که یک گره چقدر به هدف نزدیک است – اما فقط یک حدس است و میتواند اشتباه کند.
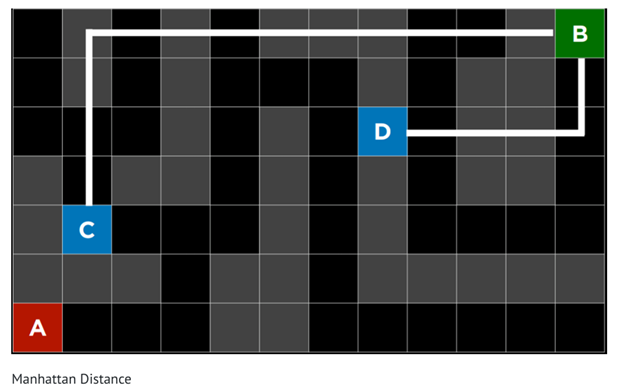
مثال (مسیریابی در یک ماز):
یک هیوریستیک متداول، فاصلهٔ منهتن (Manhattan Distance) است.
این فاصله دیوارها را نادیده میگیرد و فقط حساب میکند چند حرکت بالا، پایین، چپ یا راست لازم است تا از موقعیت فعلی به موقعیت هدف برسیم.
این تخمین با استفاده از مختصات (x, y) موقعیت فعلی و موقعیت هدف بهسادگی بهدست میآید.
نکتهٔ مهم
مثل هر هیوریستیکی، هیوریستیک نیز میتواند اشتباه کند و ممکن است الگوریتم را به مسیری هدایت کند که کندتر از مسیر واقعی باشد.
در برخی موارد، یک الگوریتم بدوناطلاع (مثلاً BFS) میتواند سریعتر به جواب برسد،
اما به طور کلی احتمال اینکه الگوریتمهای آگاهانه بهتر عمل کنند بیشتر است.
جستوجوی *A:
جستوجوی A* نسخهٔ پیشرفتهای از الگوریتم Greedy Best-First Search است.
این الگوریتم نهتنها مقدار h(n) (هزینهٔ تخمینی از موقعیت فعلی تا هدف) را در نظر میگیرد،بلکه مقدار g(n) (هزینهٔ طیشده تا رسیدن به موقعیت فعلی) را هم لحاظ میکند.
با ترکیب این دو مقدار، A* دید دقیقتری نسبت به هزینهٔ واقعی راهحل پیدا میکند و میتواند انتخابهای خود را در طول مسیر بهتر و بهینهتر مدیریت کند.
در این روش، الگوریتم مجموع زیر را محاسبه میکند:
f(n) = g(n) + h(n)
اگر در طول مسیر، این مقدار بیش از هزینهٔ تخمینی یک مسیر قبلی شود،الگوریتم مسیر فعلی را کنار گذاشته و به مسیر قبلی بازمیگردد.
به این ترتیب، از دنبال کردن یک مسیر طولانی و ناکارآمد جلوگیری میشود—حتی اگر h(n) به اشتباه آن مسیر را بهترین مسیر نشان داده باشد.
نکتهٔ مهم دربارهٔ A*
از آنجا که این الگوریتم نیز از یک هیوریستیک استفاده میکند،به اندازهٔ کیفیت هیوریستیک خوب و دقیق خواهد بود.
گاهی ممکن است در شرایطی خاص:
- کمتر از Greedy کارآمد باشد
- حتی بدتر از الگوریتمهای بدوناطلاع عمل کند
برای اینکه A* بهینه باشد، تابع هیوریستیک h(n) باید شرایط زیر را داشته باشد.
شرایط لازم برای بهینه بودن A*
۱. قابل قبول باشد (Admissible)
یعنی هرگز هزینهٔ واقعی را بیش از اندازه تخمین نزند.
(تخیمن همیشه ≤ هزینهٔ واقعی)
۲. سازگار باشد (Consistent)
یعنی تخمین باید با ارزشهای مسیر هماهنگ باشد.
به بیان دقیقتر، برای هر گره n و گره جانشین n′ با هزینهٔ انتقال c:
h(n) ≤ h(n′) + c
اگر این شرط برقرار باشد، جستوجو همیشه رو به هدف حرکت میکند و عقبگرد اشتباه رخ نمیدهد.
جستوجوی خصمانه (Adversarial Search):
تا اینجا الگوریتمهایی را بررسی کردیم که تنها باید به یک سؤال پاسخ دهند.
اما در جستوجوی خصمانه، الگوریتم با یک حریف روبهرو است که هدفش برخلاف هدف الگوریتم است.
این نوع الگوریتمها معمولاً در بازیها استفاده میشوند، مثل تیکتاکتو (tic tac toe)، شطرنج، اوتللو و غیره.
Minimax
Minimax نوعی الگوریتم در جستوجوی خصمانه است.
در این روش:
- یک طرف بازی با مقدار +1(برنده شدن) مشخص میشود
- طرف دیگر با مقدار−1 (باخت)
بازیکن (Minحداقلکننده) سعی میکند امتیاز را کمتر کند
و بازیکن (Maxحداکثرکننده) سعی میکند امتیاز را بیشتر کند
این الگوریتم با بررسی تمام حالتهای ممکن بازی، انتخابی را انجام میدهد که بهترین نتیجهٔ ممکن را در بدترین شرایط تضمین میکند.
ساخت یک هوش مصنوعی برای بازی Tic-Tac-Toe با Minimax:
برای درک نحوه عملکرد الگوریتم Minimax در بازی تیکتاکتو، ابتدا باید اجزای اصلی مدل را مشخص کنیم. این اجزا وضعیت بازی، بازیکنان و توابع تصمیمگیری را تعریف میکنند.
حالت اولیه (S₀)
در ابتدا، بازی با یک صفحهٔ 3×3 کاملاً خالی شروع میشود. این وضعیت را بهعنوان حالت اولیه در نظر میگیریم.
تابع Players(s)
این تابع مشخص میکند در هر وضعیت، نوبت کدام بازیکن است.
به عبارت دیگر، سیستم بررسی میکند که آیا X باید حرکت کند یا O.
تابع Actions(s)
در هر مرحله، الگوریتم باید بداند چه حرکتهایی مجاز هستند.
بنابراین، این تابع تمام خانههای خالی صفحه را بهعنوان حرکتهای قانونی برمیگرداند.
تابع Result(s, a)
هر زمان یک بازیکن حرکتی انجام دهد، وضعیت جدیدی ایجاد میشود.
در نتیجه، این تابع با دریافت وضعیت فعلی و یک حرکت مشخص، صفحهٔ بهروزشده بازی را تولید میکند.
تابع Terminal(s)
در ادامه، الگوریتم بررسی میکند که آیا بازی به پایان رسیده است یا خیر.
بهطور مشخص، سیستم دو حالت را ارزیابی میکند:
-
آیا یکی از بازیکنان سه علامت پشتسرهم قرار داده است؟
-
یا اینکه تمام خانهها پر شده و بازی مساوی شده است؟
اگر یکی از این شرایط برقرار باشد، بازی پایان یافته محسوب میشود.
تابع Utility(s)
در نهایت، اگر بازی به حالت پایانی برسد، مقدار سود محاسبه میشود.
به این ترتیب:
-
اگر بازیکن بیشینهکننده (Max) برنده شود، مقدار +1 ثبت میشود.
-
اگر بازیکن کمینهکننده (Min) پیروز شود، مقدار −1 در نظر گرفته میشود.
-
اما اگر بازی مساوی شود، مقدار 0 اختصاص داده میشود.
الگوریتم چگونه کار میکند؟
الگوریتم Minimax بهصورت بازگشتی تمام بازیهای ممکن را که میتوانند از حالت فعلی شروع شوند
تا رسیدن به یک حالت پایانی شبیهسازی میکند.
هر حالت پایانی با یکی از مقادیر −1، 0، +1 ارزشگذاری میشود.
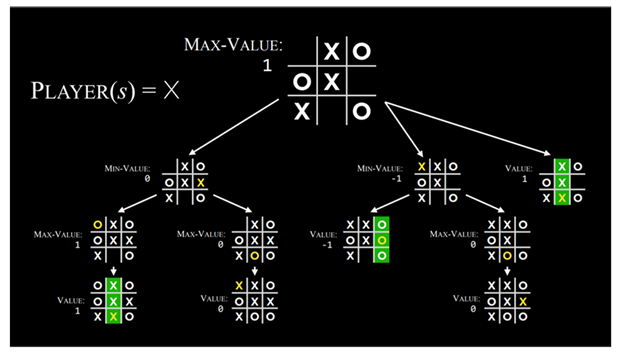
نحوهٔ تصمیمگیری در طول بازی
وقتی الگوریتم میداند نوبت کدام بازیکن است، میتواند پیشبینی کند:
- اگر نوبت بازیکن حداکثرکننده (Max) باشد → حرکتی را انتخاب میکند که بالاترین مقدار را به نتیجه برساند
- اگر نوبت بازیکن حداقلکننده (Min) باشد → حرکتی را انتخاب میکند که پایینترین مقدار را بدهد
الگوریتم برای هر حرکت ممکن، مقدار حالت نتیجه را محاسبه میکند.
مثال برای فهم بهتر فرایند
تصور کن بازیکن Max میخواهد تصمیم بگیرد کدام حرکت بهتر است.
او اینگونه فکر میکند:
اگر این حرکت را انجام دهم، یک حالت جدید ایجاد میشود.
حالا اگر بازیکن Min بهصورت بهینه بازی کند، چه حرکتی انجام میدهد تا مقدار را تا حد ممکن پایین بیاورد؟
اما برای پاسخ دادن به این سؤال، لازم است Max یک سطح عمیقتر فکر کند:
بازیکن Min هم سعی میکند همین فرایند را شبیهسازی کند:
اگر من این حرکت را انجام دهم، بازیکن Max چه حرکتی میتواند انجام دهد
تا مقدار را تا حد ممکن بالا ببرد؟
این فرایند کاملاً بازگشتی است.
آسان نیست که همهچیز را در ذهن تجسم کنیم؛ولی مشاهدهٔ شبهکد Minimax معمولاً درک موضوع را سادهتر میکند.
نتیجهٔ نهایی الگوریتم
در نهایت، بازیکن Max برای وضعیت فعلی بازی:
- مقدار همهٔ حرکتهای ممکن را محاسبه میکند
- و حرکتی را انتخاب میکند که بهترین مقدار (بیشترین سود) را ایجاد کند
یعنی Minimax، بهترین تصمیم ممکن را در بدترین شرایط ممکن تضمین میکند.
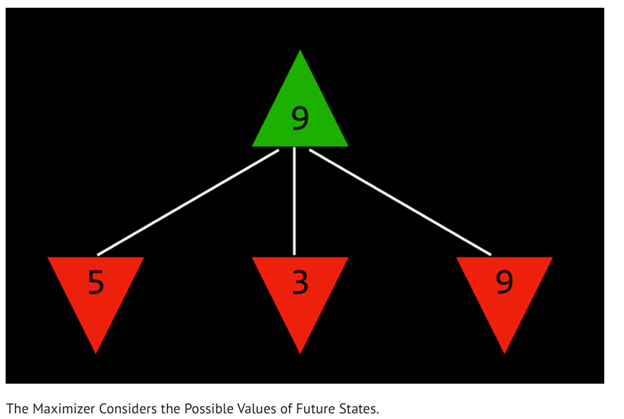
بازیکن حداکثرکننده (Maximizer) مقدار حالتهای آینده را بررسی میکند و تلاش میکند بهترین نتیجه ممکن را به دست آورد. به همین دلیل، او همواره حرکتی را انتخاب میکند که بیشترین سود را در بلندمدت تضمین کند.
برای نمایش این فرآیند در قالب شبهکد، الگوریتم Minimax به صورت زیر عمل میکند.
زمانی که نوبت Max است
در این حالت، بازیکن حداکثرکننده از میان مجموعه Actions(s) یک حرکت را انتخاب میکند.
به طور دقیقتر، او حرکتی را برمیگزیند که مقدار عبارت زیر را بیشینه کند:
Min-Value(Result(s, a))
به بیان دیگر، Max حرکتی را انتخاب میکند که حتی اگر Min بهترین پاسخ ممکن را بدهد، نتیجه نهایی همچنان بیشترین مقدار ممکن باقی بماند. بنابراین او بدترین سناریوی آینده را در نظر میگیرد و بهترین تصمیم را بر اساس آن میگیرد.
زمانی که نوبت Min است
در مقابل، بازیکن حداقلکننده دقیقاً رویکردی معکوس دارد.
او نیز از میان Actions(s) یک حرکت را انتخاب میکند، اما این بار هدف او کمینه کردن مقدار عبارت زیر است:
Max-Value(Result(s, a))
به این ترتیب، Min حرکتی را انتخاب میکند که بیشترین سود احتمالی Max را تا حد امکان کاهش دهد. در نتیجه، هر دو بازیکن به صورت منطقی و بر اساس بدترین پاسخ حریف تصمیمگیری میکنند.
توابع اصلی الگوریتم Minimax:
Function Max-Value(state)
• v = -∞
• if Terminal(state):
• return Utility(state)
• for action in Actions(state):
• v = Min(v, Max-Value(Result(state, action)))
• return v
توضیح روان:
- مقدار اولیه را برابر با منفی بینهایت قرار میدهد (چون هدف بیشینه کردن است).
- اگر حالت پایانی باشد، مقدار سود همان حالت را برمیگرداند.
- برای هر حرکت ممکن، مقدار Min-Value وضعیت حاصل از آن حرکت را محاسبه میکند،
و بزرگترین مقدار را انتخاب میکند. - در نهایت مقدار v برگردانده میشود.
• v = +∞
• if Terminal(state):
• return Utility(state)
• for action in Actions(state):
• v = Min(v, Max-Value(Result(state, action)))
• return v
توضیح روان:
- مقدار اولیه را برابر با مثبت بینهایت قرار میدهد (چون هدف کمینه کردن است).
- اگر حالت پایانی باشد، مقدار Utility آن را برمیگرداند.
- برای هر حرکت ممکن، مقدار Max-Value وضعیت حاصل از آن حرکت را حساب میکند،
و کمترین مقدار را انتخاب میکند. - در نهایت مقدار v برگردانده میشود.
Alpha-Beta Pruning
Alpha-Beta Pruning روشی برای بهینهسازی الگوریتم Minimax است که برخی از محاسبات بازگشتی را که قطعا نامطلوب هستند، نادیده میگیرد.
بعد از اینکه مقدار یک حرکت مشخص شد، اگر شواهد اولیه نشان دهد که حرکت بعدی میتواند به حریف اجازه دهد به امتیازی بهتر از حرکت قبلی برسد، دیگر نیازی به بررسی ادامهٔ آن حرکت نیست،
زیرا قطعا از حرکت قبلی کمتر مطلوب خواهد بود.
مثال برای فهم بهتر:
فرض کنید یک بازیکن حداکثرکننده (Max) میداند که در گام بعد، بازیکن حداقلکننده (Min) سعی خواهد کرد کمترین امتیاز ممکن را انتخاب کند.
- فرض کنید Max سه حرکت ممکن دارد و مقدار اولین حرکت برابر ۴ است.
- حالا Max میخواهد مقدار حرکت بعدی را محاسبه کند.
- برای این کار، Max مقادیر همهٔ حرکتهای Min را در نظر میگیرد تا بداند کمترین مقدار کدام است.
اما قبل از اینکه محاسبهٔ همهٔ حرکتهای ممکن Min تمام شود، Max متوجه میشود که یکی از گزینهها مقدار ۳ دارد.
- این یعنی دیگر نیازی به بررسی بقیهٔ حرکتهای Min نیست.
- مقدار حرکتهای هنوز بررسینشده اهمیتی ندارد، چه ۱۰ باشد چه −۱۰.
چرا؟
- اگر مقدارش ۱۰ باشد → Min باز هم کمترین مقدار ممکن (۳) را انتخاب میکند که از حرکت قبلی ۴ کمتر است.
- اگر مقدارش −۱۰ باشد → Min این گزینه را انتخاب میکند که برای Max حتی بدتر است.
بنابراین، محاسبهٔ حرکتهای اضافی برای Min در این مرحله برای Max بیفایده است،
زیرا Max قبلاً یک گزینهٔ قطعا بهتر با مقدار ۴ دارد.
به طور خلاصه، Alpha-Beta Pruning باعث میشود که الگوریتم Minimax سریعتر عمل کند و نیازی به بررسی تمام مسیرهای ممکن نباشد،
در حالی که نتیجهٔ نهایی همان نتیجهٔ Minimax بدون بهینهسازی خواهد بود.
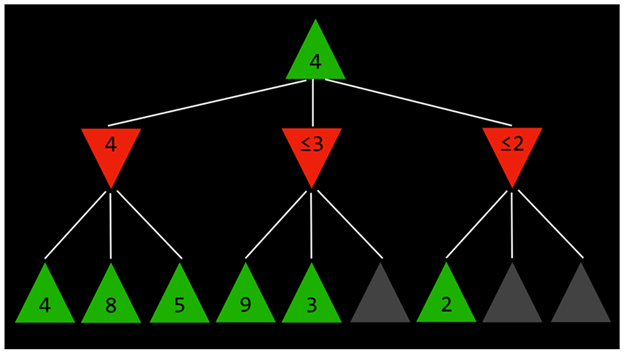
Depth-limited Minimax (مینیمکس با عمق محدود):
تعداد بازیهای ممکن Tic-Tac-Toe برابر ۲۵۵,۱۶۸ و تعداد بازیهای ممکن شطرنج حدود ²⁹⁰⁰⁰ ۱۰ است.
الگوریتم Minimax که تا اینجا توضیح داده شد، نیاز دارد که تمام بازیهای فرضی از نقطهٔ فعلی تا پایان بازی تولید شوند.
- محاسبهٔ تمام بازیهای Tic-Tac-Toe برای یک کامپیوتر مدرن مشکلی ایجاد نمیکند.
- اما انجام همین کار برای شطرنج در حال حاضر غیرممکن است.
راهحل: Depth-limited Minimax
در این روش، الگوریتم تنها تعداد مشخصی حرکت را در نظر میگیرد و بعد از آن متوقف میشود، بدون اینکه به حالت پایانی واقعی برسد.
- این روش باعث میشود که مقدار دقیق هر حرکت به دست نیاید، زیرا بازی فرضی هنوز تمام نشده است.
برای حل این مشکل، Depth-limited Minimax از یک تابع ارزیابی (Evaluation Function) استفاده میکند که:
- مقدار تقریبی سود (utility) بازی را از یک حالت مشخص تخمین میزند.
- یا به عبارتی دیگر، به هر حالت مقدار عددی اختصاص میدهد.
مثال در شطرنج
یک تابع ارزیابی شطرنج:
- ورودی: پیکربندی فعلی صفحهٔ شطرنج
- عملکرد: ارزش تقریبی موقعیت را براساس تعداد و مکان مهرهها تعیین میکند
- خروجی: یک عدد مثبت یا منفی که نشان میدهد موقعیت برای یک بازیکن نسبت به بازیکن دیگر چقدر مطلوب است
این مقادیر سپس برای انتخاب حرکت مناسب استفاده میشوند.
- هرچه تابع ارزیابی دقیقتر باشد، عملکرد Minimax با عمق محدود نیز بهتر خواهد بود.
کد پایتون:
• import math
• # تعریف صفحهٔ بازی 3x3
• def create_board():
• return [' ' for _ in range(9)]
• # نمایش صفحه
• def print_board(board):
• for i in range(3):
• print('|'.join(board[i*3:(i+1)*3]))
• if i < 2:
• print('-'*5)
• # بررسی برنده
• def check_winner(board):
• win_combinations = [
• [0,1,2],[3,4,5],[6,7,8], # ردیفها
• [0,3,6],[1,4,7],[2,5,8], # ستونها
• [0,4,8],[2,4,6] # قطرها
• ]
• for combo in win_combinations:
• if board[combo[0]] == board[combo[1]] == board[combo[2]] != ' ':
• return board[combo[0]]
• if ' ' not in board:
• return 'Tie'
• return None
• # لیست حرکات قانونی
• def available_moves(board):
• return [i for i, spot in enumerate(board) if spot == ' ']
• # تابع Minimax
• def minimax(board, is_maximizing):
• winner = check_winner(board)
• if winner == 'X':
• return 1
• elif winner == 'O':
• return -1
• elif winner == 'Tie':
• return 0
•
• if is_maximizing:
• best_score = -math.inf
• for move in available_moves(board):
• board[move] = 'X'
• score = minimax(board, False)
• board[move] = ' '
• best_score = max(score, best_score)
• return best_score
• else:
• best_score = math.inf
• for move in available_moves(board):
• board[move] = 'O'
• score = minimax(board, True)
• board[move] = ' '
• best_score = min(score, best_score)
• return best_score
• # تصمیمگیری AI
• def best_move(board):
• best_score = -math.inf
• move = None
• for m in available_moves(board):
• board[m] = 'X'
• score = minimax(board, False)
• board[m] = ' '
• if score > best_score:
• best_score = score
• move = m
• return move
• # اجرای بازی
• def play_game():
• board = create_board()
• print("شروع بازی Tic-Tac-Toe!")
• player = input("میخوای X بازی کنی یا O؟ ").upper()
• ai_player = 'O' if player == 'X' else 'X'
•
• while True:
• print_board(board)
• if check_winner(board):
• winner = check_winner(board)
• if winner == 'Tie':
• print("مساوی شد!")
• else:
• print(f"برنده: {winner}")
• break
•
• if player == 'X':
• move = int(input("نوبت تو! خانه (0 تا 8) را وارد کن: "))
• if board[move] != ' ':
• print("این خانه پره! دوباره تلاش کن.")
• continue
• board[move] = player
• player, ai_player = ai_player, player
• else:
• move = best_move(board)
• print(f"نوبت AI: خانه {move}")
• board[move] = ai_player
• player, ai_player = ai_player, player
• # اجرای بازی
• if __name__ == "__main__":
• play_game()
