

معماری( Alex Net سال ۲۰۱۲)
معماری( Alex Net سال ۲۰۱۲)
این دوره به بررسی دقیق و عمیق مباحث معماری( Alex Net سال ۲۰۱۲) به صورت پایه ای می پردازد .جهت دسترسی به سایر دوره ها می توانید از لینک های زیر استفاده نمایید.
- شبکههای عصبی کانولوشنی (Convolutional Neural Networks)
- معماری( LeNet-5 سال 1998)
- معماری( Alex Net سال ۲۰۱۲)
و برای مشاهده لیست تمام دوره ها به بخش مقالات مراجه نمایید.
فهرست مطالب:
- چکیده
- مقدمه
- بیان مسئله و زمینه تاریخی
- معرفی کلی معماری Alex Net
- نوآوریهای کلیدی Alex Net
- ساختار لایههای شبکه Alex Net
- مدل ریاضی و محاسبات در Alex Net
- فرآیند آموزش و الگوریتم Backpropagation
- مثال عددی و شهودی از کانولوشن در Alex Net
- پیادهسازی Alex Net با Python
- مزایا و محدودیتهای Alex Net
- تأثیر Alex Net بر توسعه شبکههای عمیق
- مقایسه تحلیلی Alex Net با LeNet-5 و VGG
- کاربردهای واقعی Alex Net
- چالشها و ملاحظات عملی
- نتیجهگیری پژوهشمحور
- منابع
چکیده:
Alex Net که در سال ۲۰۱۲ توسط الکس کریژفسکی، ایلیا ساتسکور و جفری هینتون معرفی شد، یکی از تأثیرگذارترین معماریهای شبکه عصبی کانولوشنی در تاریخ یادگیری عمیق محسوب میشود. این شبکه با پیروزی قاطع در رقابت ImageNet، آغازگر موج جدیدی از پژوهشها و کاربردهای عملی در حوزه بینایی ماشین شد. در این مقاله، معماری Alex Net بهصورت جامع از جنبههای تاریخی، ساختاری، ریاضی، آموزشی و کاربردی بررسی میشود.
مقدمه:
پیشرفت یادگیری عمیق در دهه ۲۰۱۰ بهطور مستقیم با موفقیت Alex Net گره خورده است. پیش از این معماری، شبکههای عصبی عمیق بهدلیل مشکلات محاسباتی و همگرایی کمتر مورد توجه بودند. Alex Net با بهرهگیری از پردازش موازی GPU و نوآوریهای معماری، نشان داد که شبکههای عمیق میتوانند در مسائل واقعی عملکردی بسیار فراتر از روشهای سنتی داشته باشند.
بیان مسئله و زمینه تاریخی:
پیش از سال ۲۰۱۲، مسئله تشخیص و طبقهبندی اشیاء در تصاویر بزرگمقیاس یکی از چالشهای اساسی حوزه بینایی ماشین محسوب میشد. مجموعهداده ImageNet که شامل بیش از یک میلیون تصویر واقعی در هزار کلاس مختلف بود، بهخوبی نشان داد که روشهای کلاسیک مبتنی بر ویژگیهای دستی مانند SIFT، HOG و مدلهای کیسه کلمات تصویری، توانایی تعمیم مناسب در چنین مقیاسی را ندارند. این روشها بهشدت وابسته به طراحی دستی ویژگیها بودند و در مواجهه با تنوع نور، زاویه دید، مقیاس و پسزمینه عملکرد ناپایداری از خود نشان میدادند.
از سوی دیگر، شبکههای عصبی کانولوشنی اولیه مانند LeNet-5 اگرچه در مسائل سادهتری همچون تشخیص ارقام دستنویس موفق بودند، اما بهدلیل عمق کم، محدودیت محاسباتی و نبود دادههای حجیم، قادر به رقابت در مسائل پیچیدهتری مانند ImageNet نبودند. نبود سختافزار مناسب برای آموزش شبکههای عمیق نیز یکی از موانع اصلی توسعه این مدلها بهشمار میرفت.
در چنین شرایطی، نیاز به معماریای احساس میشد که بتواند هم از قدرت نمایش بالای شبکههای عمیق بهره ببرد و هم با استفاده از منابع محاسباتی موجود آموزشپذیر باشد. Alex Net دقیقاً در پاسخ به این نیاز طراحی شد و با ترکیب نوآوریهای معماری و سختافزاری، نقطه عطفی در تاریخ یادگیری عمیق ایجاد کرد.
معرفی کلی معماری Alex Net:
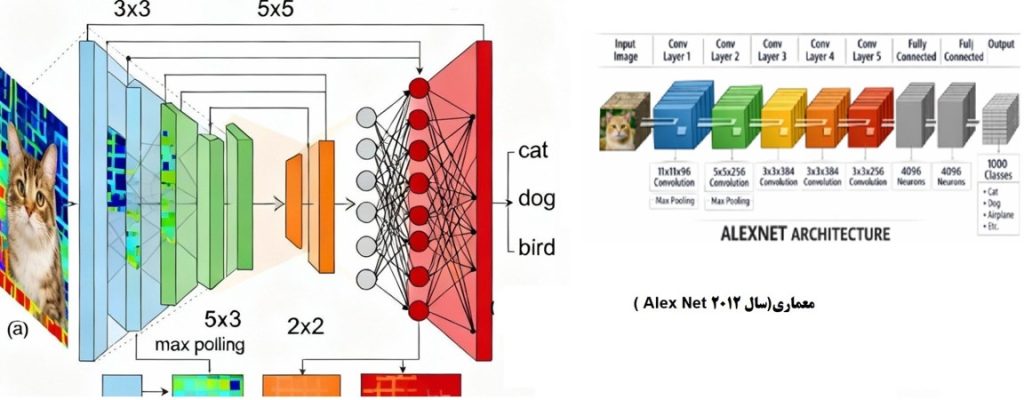
Alex Net که توسط الکس کریژفسکی، ایلیا سوتسکِوِر و جفری هینتون در سال ۲۰۱۲ معرفی شد، یک شبکه عصبی کانولوشنی عمیق است که برای رقابت ImageNet طراحی شد و توانست با اختلاف قابلتوجهی نسبت به رقبا، نرخ خطای طبقهبندی را کاهش دهد. این معماری شامل هشت لایه اصلی (پنج لایه کانولوشن و سه لایه کاملاً متصل) است و از نوآوریهایی مانند تابع فعالساز ReLU، Dropout و آموزش مبتنی بر GPU بهره میبرد.
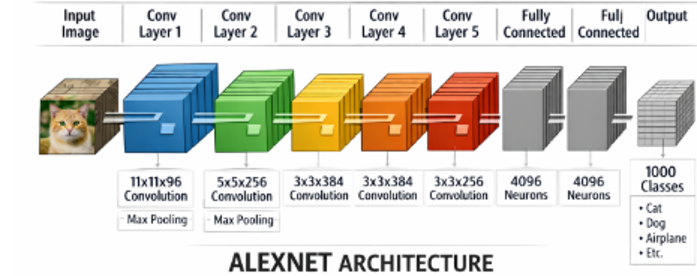
تشریح لایهبهلایه Alex Net و تحلیل پارامترها:
Alex Net ورودیهایی با ابعاد 224×224×3 را دریافت میکند. لایه کانولوشن اول شامل 96 فیلتر با اندازه 11×11 و گام 4 است که خروجی آن نقشههای ویژگی با ابعاد 55×55×96 میباشد. این لایه بهتنهایی بیش از 34 هزار پارامتر دارد. در لایههای بعدی، اندازه فیلترها کوچکتر شده اما تعداد آنها افزایش مییابد؛ بهطوریکه در لایه پنجم کانولوشن، 256 فیلتر 3×3 مورد استفاده قرار میگیرد. سه لایه Fully Connected پایانی مجموعاً بیش از ۵۸ میلیون پارامتر را شامل میشوند که بخش عمده پیچیدگی مدل را تشکیل میدهد.
الگوریتم Backpropagation در( Alex Net تحلیلی–ریاضی):
در Alex Net، تابع فعالساز ReLU بهصورت f(x)=max(0,x) تعریف میشود که با حذف اشباع توابع سیگموئیدی، سرعت همگرایی را بهشدت افزایش میدهد. در فرآیند Backpropagation، گرادیان خطا فقط از نورونهای فعال عبور میکند که این ویژگی موجب کاهش مشکل ناپدیدشدن گرادیان میشود. Dropout نیز با حذف تصادفی نورونها در مرحله آموزش، شبکه را مجبور به یادگیری نمایشهای پایدارتر کرده و از بیشبرازش جلوگیری میکند.
مثال عددی کانولوشن با محاسبات واقعی:
برای درک دقیقتر نحوه عملکرد لایههای کانولوشن در Alex Net، یک مثال عددی گامبهگام ارائه میشود. فرض کنید یک تصویر خاکستری کوچک با ابعاد 5×5 بهصورت زیر در اختیار داریم:
X = [[1,2,0,1,3],
[4,1,2,0,1],
[0,1,3,1,2],
[2,0,1,2,1],
[1,2,0,1,0]]
همچنین یک فیلتر کانولوشن 3×3 بهشکل زیر تعریف میشود:
W = [[1,0,-1],
[1,0,-1],
[1,0,-1]]
برای محاسبه اولین مقدار خروجی، فیلتر روی بخش بالایی–چپ تصویر قرار میگیرد و حاصلضرب عنصربهعنصر محاسبه میشود:
Z(1,1) = (1×1)+(2×0)+(0×-1)+(4×1)+(1×0)+(2×-1)+(0×1)+(1×0)+(3×-1) = 0
این فرآیند برای تمام موقعیتهای معتبر تکرار میشود تا نقشه ویژگی نهایی بهدست آید. این مثال عددی نشان میدهد که چگونه فیلترها قادر به استخراج ویژگیهایی مانند لبههای عمودی هستند.
پیادهسازی Alex Net با Python (PyTorch):
در این بخش، پیادهسازی Alex Net با استفاده از کتابخانه PyTorch بهصورت مفصل بررسی میشود تا ارتباط میان ساختار نظری شبکه و اجرای عملی آن روشن گردد. PyTorch به دلیل ماهیت پویا و سادگی در تعریف گراف محاسباتی، یکی از ابزارهای محبوب برای پیادهسازی شبکههای عصبی عمیق محسوب میشود.
در کد زیر، نسخهای سادهشده اما ساختاریافته از Alex Net ارائه شده است که شامل لایههای کانولوشن، توابع فعالساز ReLU، لایههای Pooling، Dropout و لایههای کاملاً متصل میباشد:
import torch
import torch.nn as nn
class AlexNet(nn.Module):
def __init__(self, num_classes=1000):
super(AlexNet, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 96, kernel_size=11, stride=4, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(96, 256, kernel_size=5, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(256, 384, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(384, 384, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(384, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2)
)
self.classifier = nn.Sequential(
nn.Dropout(p=0.5),
nn.Linear(256 * 6 * 6, 4096),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, num_classes)
)
def forward(self, x):
x = self.features(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
model = AlexNet(num_classes=1000)
print(model)
در این پیادهسازی، بخش features مسئول استخراج ویژگیها از تصویر ورودی است و شامل لایههای کانولوشن، ReLU و Pooling میباشد. بخش classifier وظیفه نگاشت ویژگیهای استخراجشده به کلاسهای خروجی را بر عهده دارد. دستور torch.flatten برای تبدیل خروجی سهبعدی کانولوشنها به بردار یکبعدی مورد استفاده قرار میگیرد.
وجود Dropout در لایههای Fully Connected باعث کاهش بیشبرازش میشود و استفاده از ReLU نیز سرعت همگرایی شبکه را افزایش میدهد. این کد نمونهای آموزشی و عملی از پیادهسازی Alex Net است و میتواند مبنایی مناسب برای آزمایش و توسعه مدلهای کانولوشنی پیشرفتهتر باشد.
مقایسه تحلیلی Alex Net با LeNet-5 و VGG:
- مقایسه Alex Net با LeNet-5 و VGG از جنبههای مختلفی مانند عمق شبکه، تعداد پارامترها، پیچیدگی محاسباتی و نوع داده ورودی قابل انجام است. LeNet-5 دارای ساختاری کمعمق و تعداد پارامتر محدود است و عمدتاً برای تصاویر ساده و تککاناله طراحی شده است. در مقابل، Alex Net با افزایش چشمگیر تعداد پارامترها و پردازش تصاویر رنگی بزرگمقیاس، توانست قدرت نمایش بسیار بالاتری ارائه دهد.
- در مقایسه با VGG، Alex Net معماری سادهتری دارد و از فیلترهای بزرگتری در لایههای ابتدایی استفاده میکند. VGG با افزایش عمق شبکه و استفاده از فیلترهای کوچک ۳×۳، دقت بالاتری بهدست آورد اما هزینه محاسباتی و مصرف حافظه آن بهمراتب بیشتر است. از این منظر، Alex Net را میتوان معماریای دانست که تعادلی میان سادگی و کارایی برقرار کرده و نقش واسطی میان CNNهای اولیه و معماریهای بسیار عمیق ایفا نموده است.
- مقایسه Alex Net با معماریهای قبل و بعد از خود، درک بهتری از جایگاه تاریخی و فنی این شبکه ارائه میدهد. در مقایسه با LeNet-5، Alex Net از نظر عمق شبکه، تعداد پارامترها و نوع داده ورودی تفاوت بنیادین دارد. LeNet-5 عمدتاً برای تصاویر ساده و تککاناله با ابعاد کوچک طراحی شده بود، در حالی که Alex Net تصاویر رنگی بزرگمقیاس را پردازش میکند. این افزایش مقیاس باعث شد Alex Net بتواند ویژگیهای پیچیدهتری مانند الگوهای بافتی، اشکال سهبعدی و ترکیبات رنگی را استخراج کند.
VGG:
- در مقایسه با VGG، Alex Net معماری سادهتری دارد و از فیلترهای بزرگتری در لایههای ابتدایی استفاده میکند. VGG با استفاده از فیلترهای ۳×۳ و افزایش عمق شبکه، توانست دقت بالاتری بهدست آورد اما هزینه محاسباتی و مصرف حافظه آن بهمراتب بیشتر است. بنابراین Alex Net را میتوان نقطه تعادل میان سادگی و توان نمایش دانست که نقش گذار میان CNNهای اولیه و عمیق را ایفا میکند.
- از منظر هزینه محاسباتی و مصرف حافظه، تفاوت Alex Net و VGG اهمیت عملی ویژهای دارد. معماری VGG بهدلیل عمق بسیار زیاد و استفاده گسترده از لایههای کانولوشن و کاملاً متصل، به منابع محاسباتی و حافظه قابلتوجهی نیاز دارد که اجرای آن را در بسیاری از سامانههای محدود دشوار میسازد. در مقابل، Alex Net با وجود تعداد بالای پارامترها، بهویژه بهسبب عمق کمتر و ساختار سادهتر، هزینه محاسباتی کمتری دارد و آموزش و استقرار آن سادهتر است. این موضوع یک trade-off کلاسیک میان عمق و کارایی را نشان میدهد: اگرچه VGG دقت بالاتری ارائه میدهد، Alex Net در سناریوهایی مانند آموزش سریع، محیطهای آموزشی، سامانههای نیمهبلادرنگ یا پروژههایی با محدودیت منابع، همچنان گزینهای منطقی و قابلاتکا محسوب میشود.
کاربردهای واقعی Alex Net:
کاربردهای Alex Net فراتر از رقابت ImageNet بوده و این معماری در حوزههای مختلف صنعتی و پژوهشی مورد استفاده قرار گرفته است. در صنعت خودروهای خودران، Alex Net بهعنوان یکی از نخستین CNNهای موفق برای تشخیص اشیاء جادهای مانند خودروها، عابران پیاده و علائم راهنمایی بهکار گرفته شد. این کاربرد نشان داد که شبکههای عمیق میتوانند در محیطهای واقعی و پویا نیز عملکرد قابلاعتمادی داشته باشند.
در حوزه پزشکی، Alex Net برای تحلیل تصاویر پزشکی مانند MRI، CT و تصاویر پاتولوژی دیجیتال استفاده شده است. در این سناریوها، شبکه قادر است الگوهای پیچیدهای را شناسایی کند که تشخیص آنها برای چشم انسان دشوار است. همچنین در صنعت جستجوی تصویر و شبکههای اجتماعی، Alex Net بهعنوان پایهای برای سیستمهای بازیابی تصویر و برچسبگذاری خودکار تصاویر مورد استفاده قرار گرفته است.
چالشها و ملاحظات عملی:
با وجود موفقیتهای چشمگیر، استفاده از Alex Net با چالشهایی نیز همراه است که بررسی آنها برای درک محدودیتهای عملی این معماری ضروری است. یکی از مهمترین این چالشها، تعداد بسیار بالای پارامترها بهویژه در لایههای کاملاً متصل است. این مسئله نهتنها منجر به مصرف بالای حافظه میشود، بلکه خطر بیشبرازش را نیز افزایش میدهد، بهخصوص در شرایطی که داده آموزشی محدود باشد.
چالش دیگر، هزینه محاسباتی بالای آموزش Alex Net است. اگرچه استفاده از GPU در زمان معرفی این معماری یک نوآوری محسوب میشد، اما همچنان آموزش چنین شبکهای نسبت به مدلهای کمعمق بسیار پرهزینه است. این موضوع در کاربردهای بلادرنگ یا سیستمهای با منابع محدود میتواند مانع استفاده عملی از Alex Net شود.
همچنین، استفاده از فیلترهای بزرگ در لایههای ابتدایی شبکه ممکن است باعث از دست رفتن برخی جزئیات مکانی تصویر گردد. این مسئله بعدها با معرفی معماریهایی مانند VGG که از فیلترهای کوچکتر و عمق بیشتر استفاده میکردند، تا حد زیادی برطرف شد. بنابراین، Alex Net را میتوان معماریای دانست که هم نقاط قوت قابلتوجه و هم محدودیتهای مشخصی دارد و همین محدودیتها مسیر پژوهشهای بعدی را شکل دادهاند.
تأثیر Alex Net بر توسعه CNNهای مدرن:
معماری Alex Net نقطه عطفی در تاریخ یادگیری عمیق محسوب میشود و تأثیر آن بر توسعه شبکههای عصبی کانولوشنی مدرن بسیار عمیق و چندلایه بوده است. پیش از Alex Net، استفاده از شبکههای عصبی عمیق در مقیاس بزرگ با تردیدهای جدی همراه بود و بسیاری از پژوهشگران، شبکههای کمعمق یا روشهای مهندسی ویژگی را ترجیح میدادند. موفقیت Alex Net در رقابت ImageNet نشان داد که با طراحی معماری مناسب، استفاده از GPU و تکنیکهای منظمسازی، میتوان شبکههای عمیق را بهطور مؤثر آموزش داد.
یکی از مهمترین میراثهای Alex Net، تثبیت استفاده از تابع فعالساز ReLU بهجای توابع سیگموئید و تانژانت هیپربولیک بود. این تغییر ساده اما بنیادین، مشکل ناپدید شدن گرادیان را تا حد زیادی کاهش داد و راه را برای شبکههای بسیار عمیقتر هموار کرد. علاوه بر این، مفهوم Dropout که در Alex Net بهصورت عملی و مؤثر بهکار گرفته شد، بعدها به یکی از ابزارهای استاندارد در طراحی شبکههای عصبی تبدیل گردید.
Alex Net همچنین نقش مهمی در تغییر نگرش جامعه علمی نسبت به دادههای بزرگ ایفا کرد. این معماری نشان داد که افزایش حجم داده آموزشی، در کنار مدلهای عمیق، میتواند به بهبود چشمگیر عملکرد منجر شود. این دیدگاه مستقیماً بر توسعه معماریهایی مانند VGG، GoogLeNet و ResNet تأثیر گذاشت که هر یک بهنوعی ایدههای Alex Net را گسترش دادند.
مقایسه Alex Net با معماریهای جدیدتر:
در مقایسه با معماریهای جدیدتر، Alex Net اگرچه سادهتر و کمعمقتر است، اما از نظر تاریخی و مفهومی اهمیت ویژهای دارد. معماری VGG با افزایش عمق شبکه و استفاده از فیلترهای کوچکتر، تلاش کرد قدرت بیان مدل را افزایش دهد، در حالی که Alex Net بیشتر بر کاهش پیچیدگی محاسباتی و امکان آموزش عملی تمرکز داشت.
از سوی دیگر، معماریهایی مانند ResNet با معرفی اتصالات میانبُری، مشکل افت دقت در شبکههای بسیار عمیق را برطرف کردند؛ مشکلی که در زمان Alex Net هنوز بهصورت جدی مطرح نشده بود. با این حال، بسیاری از مفاهیم پایهای این معماریها، از جمله کانولوشن، pooling، ReLU و آموزش مبتنی بر دادههای بزرگ، مستقیماً ریشه در AlexNet دارند.
در نهایت میتوان گفت Alex Net نه بهعنوان یک معماری نهایی، بلکه بهعنوان یک «الگوی تحولساز» در تاریخ CNNها شناخته میشود که مسیر پژوهشهای بعدی را بهطور اساسی تغییر داد.
منابع:
Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2012). ImageNet classification with deep convolutional neural networks. Advances in Neural Information Processing Systems.
LeCun, Y., Bengio, Y., & Hinton, G. (2015). Deep learning. Nature.
Goodfellow, I., Bengio, Y., & Courville, A. (2016). Deep Learning. MIT Press.


