

شبکههای عصبی کانولوشنی (Convolutional Neural Networks)
شبکههای عصبی کانولوشنی (Convolutional Neural Networks)
این دوره به بررسی دقیق و عمیق مباحث شبکههای عصبی کانولوشنی به صورت پایه ای می پردازد .جهت دسترسی به سایر دوره ها می توانید از لینک های زیر استفاده نمایید.
- شبکههای عصبی کانولوشنی (Convolutional Neural Networks)
و برای مشاهده لیست تمام دوره ها به بخش مقالات مراجه نمایید.
فهرست مطالب:
- چکیده
- مقدمه
- بیان مسئله و ضرورت استفاده از CNN
- تاریخچه و سیر تکامل شبکههای کانولوشنی
- الهامگیری زیستی CNN از سیستم بینایی انسان
- ساختار کلی شبکههای عصبی کانولوشنی
- مدل ریاضی عملیات کانولوشن
- پارامترها و ابرپارامترهای CNN
- فرآیند آموزش شبکههای عصبی کانولوشنی
- الگوریتم Backpropagation در CNN
- مثال عددی گامبهگام از عملیات کانولوشن
- پیادهسازی عملی با Python و Keras
- مزایا و محدودیتهای شبکههای CNN
- کاربردهای واقعی شبکههای عصبی کانولوشنی
- مقایسه تحلیلی CNN با MLP و RNN
- چالشها و ملاحظات عملی
- روندهای پژوهشی و توسعههای نوین CNN
- نتیجهگیری علمی و جمعبندی
- منابع
چکیده:
شبکههای عصبی کانولوشنی (CNN) یکی از موفقترین و پرکاربردترین معماریهای یادگیری عمیق در دهههای اخیر بهشمار میروند. این شبکهها بهطور ویژه برای پردازش دادههای دارای ساختار مکانی مانند تصاویر، ویدئوها و سیگنالهای دوبعدی طراحی شدهاند. استفاده از لایههای کانولوشن و تجمیع باعث شده است CNNها بتوانند ویژگیهای محلی و سلسلهمراتبی دادهها را با دقت بالا استخراج کنند. در این مقاله، شبکههای عصبی کانولوشنی بهصورت جامع از جنبههای نظری، ریاضی، ساختاری و کاربردی بررسی میشوند و با سایر معماریهای رایج مقایسه تحلیلی انجام میگیرد.
مقدمه:
پیشرفت چشمگیر یادگیری ماشین و یادگیری عمیق در سالهای اخیر، تأثیر بسزایی در حل مسائل پیچیدهای مانند تشخیص تصویر، پردازش زبان طبیعی و بینایی ماشین داشته است. در میان معماریهای مختلف شبکههای عصبی، شبکههای عصبی کانولوشنی جایگاه ویژهای پیدا کردهاند. دلیل اصلی این موفقیت، توانایی CNNها در بهرهگیری از ساختار مکانی دادهها و کاهش تعداد پارامترهای قابل آموزش نسبت به شبکههای کاملاً متصل است.
پیش از معرفی CNNها، شبکههای عصبی کلاسیک مانند پرسپترون چندلایه برای پردازش تصاویر مورد استفاده قرار میگرفتند، اما این شبکهها بهدلیل تعداد بسیار زیاد پارامترها و عدم درک ساختار مکانی تصویر، عملکرد مطلوبی نداشتند. CNNها با معرفی مفهوم کانولوشن و اشتراک وزنها، این محدودیتها را تا حد زیادی برطرف کردند.
بیان مسئله و ضرورت استفاده از CNN:
دادههای تصویری و مکانی دارای ابعاد بالا و وابستگیهای محلی هستند. برای مثال، در یک تصویر چهره، پیکسلهای اطراف چشم، بینی و دهان ارتباط معنایی قویتری با یکدیگر دارند تا با پیکسلهای دورتر. شبکههای عصبی کلاسیک مانند MLP این ساختار مکانی را نادیده میگیرند و هر پیکسل را بهصورت مستقل پردازش میکنند که منجر به افزایش شدید تعداد پارامترها و کاهش کارایی میشود.
در حوزه تشخیص چهره، چالش اصلی استخراج ویژگیهای پایدار در برابر تغییرات نور، زاویه دید و حالات چهره است. CNNها با یادگیری فیلترهای محلی قادرند لبهها، بافتها و ساختارهای پیچیده صورت را بهصورت سلسلهمراتبی استخراج کنند.
در تصویربرداری پزشکی، مانند تشخیص تومور در تصاویر MRI یا CT، تفاوتهای ظریف بافتی نقش حیاتی دارند. CNNها میتوانند این تفاوتهای محلی را شناسایی کرده و دقت تشخیص را بهطور قابل توجهی افزایش دهند.
در دادههای ماهوارهای نیز، شناسایی کاربری زمین، پوشش گیاهی یا تغییرات اقلیمی نیازمند تحلیل الگوهای مکانی در مقیاسهای مختلف است. CNNها با استفاده از فیلترهای چندمقیاسی، راهحلی مؤثر برای این مسائل فراهم میکنند.
تاریخچه و سیر تکامل شبکههای کانولوشنی:
ریشههای CNN به دهه ۱۹۸۰ و پژوهشهای انجامشده روی سیستم بینایی انسان بازمیگردد. در سال ۱۹۹۸، یان لکون معماری LeNet-5 را برای تشخیص ارقام دستنویس معرفی کرد که یکی از نخستین نمونههای موفق CNN محسوب میشود. پس از آن، با افزایش قدرت محاسباتی و ظهور GPUها، معماریهای عمیقتری مانند AlexNet، VGG، GoogLeNet و ResNet توسعه یافتند که هرکدام نقش مهمی در پیشرفت بینایی ماشین ایفا کردند.
الهامگیری زیستی CNN از سیستم بینایی انسان:
شبکههای عصبی کانولوشنی از نحوه پردازش اطلاعات در قشر بینایی مغز انسان الهام گرفتهاند. در سیستم بینایی، نورونها به نواحی خاصی از میدان دید حساس هستند و بهصورت سلسلهمراتبی ویژگیها را استخراج میکنند. CNNها نیز با استفاده از لایههای کانولوشن متوالی، ویژگیهای ساده را در لایههای ابتدایی و ویژگیهای پیچیدهتر را در لایههای عمیقتر یاد میگیرند.
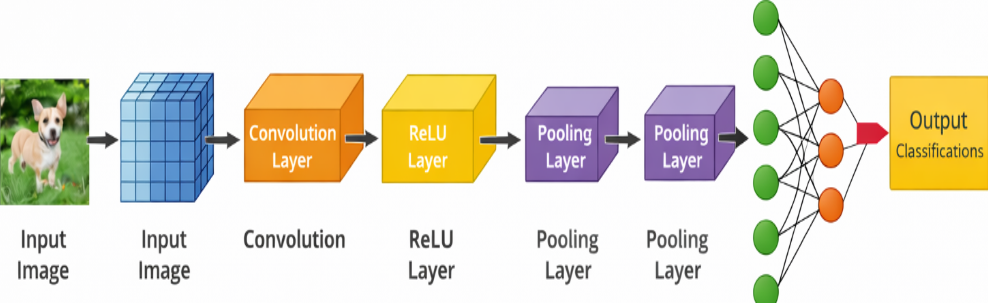
ساختار کلی شبکههای عصبی کانولوشنی:
لایه ورودی
لایه ورودی داده خام مانند تصویر را دریافت میکند که معمولاً بهصورت یک ماتریس یا تانسور چندبعدی نمایش داده میشود.
لایه کانولوشن
در این لایه، فیلترهای کوچک روی تصویر حرکت کرده و حاصل ضرب داخلی محاسبه میشود. خروجی این لایه، نقشههای ویژگی هستند.
لایه تابع فعالساز
توابعی مانند ReLU غیرخطی بودن را به شبکه اضافه میکنند و باعث افزایش توان یادگیری میشوند.
لایه تجمیع (Pooling)
این لایه با کاهش ابعاد نقشههای ویژگی، پیچیدگی محاسباتی را کاهش داده و مقاومت شبکه در برابر تغییرات کوچک را افزایش میدهد.
لایههای کاملاً متصل
در انتهای شبکه، لایههای Fully Connected برای انجام طبقهبندی یا پیشبینی استفاده میشوند.
مدل ریاضی عملیات کانولوشن:
عملیات کانولوشن بهصورت ریاضی به شکل زیر تعریف میشود:
z(i,j)=m∑n∑x(i+m,j+n)w(m,n)+b
برای محاسبه مقدار خروجی در نقطه (i , j):
- یک فیلتر (w) را روی تصویر میگذاریم
- پیکسلهای تصویر (x) که زیر فیلتر قرار گرفتهاند را در وزنهای فیلتر ضرب میکنیم
- همه این ضربها را با هم جمع میکنیم
- در آخر یک عدد ثابت به نام بایاس (b) به آن اضافه میکنیم
- عدد بهدستآمده میشود z(i , j)
- z(i , j) خروجی لایه کانولوشن در مکان (i , j)
- x(i+m , j+n) مقدار پیکسل ورودی تصویر پیکسلی که نسبت به نقطه (i , j) به اندازه m و n جابهجا شده
- w(m , n) وزن فیلتر (کرنل) در موقعیت (m , n)
- ∑∑ جمع روی همه عناصر فیلتر یعنی کل ناحیهای که فیلتر پوشش داده
- b بایاس (عدد ثابت) که در آن x ورودی، w فیلتر و b بایاس است
این فرمول میگوید:
«فیلتر را روی تصویر بگذار، هر پیکسل را در وزنش ضرب کن، همه را جمع کن و بایاس اضافه کن.»
پارامترها و ابرپارامترهای CNN:
در طراحی و پیادهسازی شبکههای عصبی کانولوشنی، انتخاب صحیح پارامترها و ابرپارامترها نقش تعیینکنندهای در عملکرد نهایی مدل دارد. اندازه فیلتر (Kernel Size) مشخص میکند که هر نورون کانولوشنی چه ناحیهای از تصویر را مشاهده کند. فیلترهای کوچکتر معمولاً برای استخراج ویژگیهای محلی مانند لبهها مناسب هستند، در حالی که فیلترهای بزرگتر میتوانند الگوهای کلیتر را شناسایی کنند.
گام حرکت یا Stride تعیین میکند فیلتر با چه فاصلهای روی تصویر جابهجا شود. افزایش مقدار Stride باعث کاهش ابعاد نقشه ویژگی و در نتیجه کاهش هزینه محاسباتی میشود، اما ممکن است بخشی از اطلاعات از دست برود. Padding نیز برای حفظ ابعاد تصویر یا جلوگیری از کاهش سریع اندازه نقشههای ویژگی بهکار میرود.
تعداد فیلترها در هر لایه کانولوشن بیانگر تعداد الگوهایی است که شبکه قادر به یادگیری آنهاست. افزایش تعداد فیلترها قدرت بیان شبکه را افزایش میدهد، اما خطر بیشبرازش و افزایش زمان آموزش را نیز بههمراه دارد. از دیگر ابرپارامترهای مهم میتوان به نوع تابع فعالساز، نرخ یادگیری، اندازه دسته داده (Batch Size) و تعداد دورههای آموزش (Epochs) اشاره کرد.
فرآیند آموزش شبکههای عصبی کانولوشنی:
فرآیند آموزش شبکههای عصبی کانولوشنی شامل چندین مرحله متوالی است که بهصورت تکرارشونده انجام میشوند. در مرحله نخست، دادههای آموزشی به شبکه وارد شده و عملیات عبور رو به جلو (Forward Pass) انجام میشود. در این مرحله، ورودی از لایههای کانولوشن، تابع فعالساز و Pooling عبور کرده و در نهایت به لایههای کاملاً متصل میرسد.
پس از محاسبه خروجی شبکه، مقدار خطا با استفاده از یک تابع هزینه مانند Cross-Entropy یا Mean Squared Error محاسبه میشود. این خطا نشاندهنده میزان اختلاف بین پیشبینی شبکه و مقدار واقعی است. در مرحله بعد، الگوریتم Backpropagation فعال میشود و گرادیان خطا نسبت به وزنها و بایاسها محاسبه میگردد.
در نهایت، وزنها با استفاده از یک روش بهینهسازی مانند Gradient Descent، Adam یا RMSProp بهروزرسانی میشوند. این چرخه برای تمام دادههای آموزشی و در چندین دوره تکرار میشود تا شبکه به همگرایی برسد. انتخاب مناسب تابع هزینه و الگوریتم بهینهسازی تأثیر مستقیمی بر سرعت و کیفیت یادگیری دارد.
الگوریتم Backpropagation در CNN:
الگوریتم Backpropagation در شبکههای کانولوشنی برای بهروزرسانی وزنها و بایاسها بهگونهای طراحی شده است که خطای خروجی شبکه کمینه شود. این فرآیند از لایه خروجی آغاز شده و بهصورت معکوس تا لایههای ابتدایی ادامه مییابد.
در لایههای Fully Connected، گرادیان خطا نسبت به وزنها مشابه شبکههای کلاسیک محاسبه میشود. در لایه Pooling، معمولاً از Max Pooling استفاده میشود که در آن گرادیان تنها به نورونی منتقل میشود که بیشترین مقدار را در مرحله رو به جلو داشته است.
در لایه کانولوشن، محاسبه گرادیان پیچیدهتر است. گرادیان خطا نسبت به فیلترها با کانولوشن معکوس خطا و ورودی محاسبه میشود. این فرآیند باعث میشود فیلترها بهگونهای تنظیم شوند که ویژگیهای مهم تصویر بهتر استخراج شوند.
مثال عددی گامبهگام از عملیات کانولوشن:
فرض کنید یک تصویر خاکستری ۵×۵ بهصورت ماتریس زیر داریم:
1 2 3 0 1
2 1 0 1 2
3 1 2 1 0
0 1 2 3 1
1 0 1 2 3
و یک فیلتر ۳×۳ بهصورت ماتریس زیر:
1 0 -1
1 0 -1
1 0 -1
با حرکت فیلتر روی تصویر و محاسبه ضرب داخلی، مقدار هر پیکسل خروجی محاسبه میشود. برای مثال، خروجی پیکسل بالا-چپ برابر مجموع حاصلضرب عناصر متناظر تصویر و فیلتر است که نشاندهنده تشخیص لبه عمودی در تصویر میباشد.
پیادهسازی عملی با Python و Keras:
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense
model = Sequential([
Conv2D(32, (3,3), activation='relu', input_shape=(28,28,1)),
MaxPooling2D((2,2)),
Flatten(),
Dense(128, activation='relu'),
Dense(10, activation='softmax')
])
model.summary()
مزایا و محدودیتهای شبکههای CNN:
کاهش تعداد پارامترها، استخراج ویژگیهای خودکار و دقت بالا از مزایای CNN هستند. نیاز به دادههای زیاد و هزینه محاسباتی بالا از محدودیتهای آنها محسوب میشوند.
کاربردهای واقعی شبکههای عصبی کانولوشنی:
در حوزه پزشکی، CNNها برای تشخیص بیماریها از تصاویر پزشکی مانند سرطان پوست و بیماریهای ریوی استفاده میشوند. در خودروهای خودران، این شبکهها نقش کلیدی در تشخیص علائم راهنمایی، عابر پیاده و موانع دارند.
در صنعت، CNNها برای کنترل کیفیت، تشخیص نقص محصولات و بینایی ماشین در خطوط تولید بهکار میروند. این کاربردها نشاندهنده اهمیت عملی بالای CNNها هستند.
مقایسه تحلیلی CNN با MLP و RNN:
در مقایسه با MLP، شبکههای CNN تعداد پارامترهای بسیار کمتری دارند، زیرا وزنها در لایههای کانولوشن به اشتراک گذاشته میشوند. این ویژگی باعث افزایش کارایی و کاهش بیشبرازش میشود.
در مقایسه با RNN، CNNها فاقد حافظه زمانی هستند اما در پردازش دادههای مکانی بسیار کارآمدترند. RNNها برای دادههای ترتیبی مناسبترند، در حالی که CNNها برای تصاویر و دادههای دوبعدی عملکرد بهتری دارند.
چالشها و ملاحظات عملی:
چالشهای مرتبط با شبکههای عصبی کانولوشنی تنها به پیچیدگی محاسباتی محدود نمیشوند، بلکه جنبههای دادهمحور و طراحی مدل را نیز در بر میگیرند. یکی از مهمترین چالشها، نیاز به حجم بالای دادههای برچسبخورده است. در بسیاری از حوزههای کاربردی مانند پزشکی یا تصاویر ماهوارهای، تهیه دادههای دقیق و برچسبخورده فرآیندی زمانبر، پرهزینه و نیازمند تخصص انسانی است. این مسئله میتواند مانعی جدی برای توسعه مدلهای CNN کارآمد باشد.
چالش دیگر، بیشبرازش (Overfitting) است که بهویژه در شبکههای عمیق با تعداد پارامترهای بالا مشاهده میشود. استفاده از تکنیکهایی مانند Dropout، Data Augmentation و Regularization تا حدی این مشکل را کاهش میدهد، اما انتخاب صحیح این روشها نیازمند تجربه و آزمایشهای متعدد است. همچنین، تفسیرپذیری پایین CNNها یکی دیگر از محدودیتهای مهم آنهاست. در بسیاری از کاربردهای حساس مانند تشخیص پزشکی، درک دلیل تصمیمگیری مدل اهمیت بالایی دارد، در حالی که CNNها اغلب بهعنوان «جعبه سیاه» شناخته میشوند.
از منظر عملی، نیاز به سختافزارهای قدرتمند مانند GPU یا TPU نیز میتواند مانعی برای استفاده گسترده از CNNها باشد، بهویژه در سیستمهای تعبیهشده یا کاربردهای بلادرنگ. بنابراین، طراحی معماریهای سبکوزن و بهینهسازی مصرف انرژی از جمله موضوعات مهم پژوهشی در این حوزه است.
روندهای پژوهشی و توسعههای نوین CNN:
در سالهای اخیر، پژوهشهای گستردهای برای بهبود کارایی و گسترش قابلیتهای شبکههای عصبی کانولوشنی انجام شده است. یکی از مهمترین روندها، توسعه معماریهای بسیار عمیق مانند ResNet و DenseNet است که با استفاده از اتصالات میانبُر، مشکل ناپدید شدن گرادیان را کاهش میدهند.
همچنین، شبکههای کانولوشنی سهبعدی برای پردازش دادههای حجمی مانند ویدئوها و تصاویر پزشکی سهبعدی معرفی شدهاند. ترکیب CNNها با معماریهای Transformer نیز یکی از مسیرهای نوین پژوهشی است که تلاش میکند مزایای پردازش مکانی CNN و قابلیت توجه Transformer را با یکدیگر ترکیب کند.
از دیگر حوزههای فعال پژوهشی میتوان به یادگیری انتقالی، شبکههای سبکوزن برای سیستمهای تعبیهشده و روشهای کاهش مصرف انرژی اشاره کرد. این روندها نشان میدهند که CNNها همچنان نقش محوری در آینده یادگیری عمیق خواهند داشت.
نتیجهگیری علمی و جمعبندی:
شبکههای عصبی کانولوشنی بهعنوان یکی از مهمترین دستاوردهای یادگیری عمیق، تحولی اساسی در پردازش دادههای تصویری و مکانی ایجاد کردهاند. توانایی این شبکهها در استخراج ویژگیهای سلسلهمراتبی، بهرهگیری از اشتراک وزنها و کاهش چشمگیر تعداد پارامترها نسبت به شبکههای کاملاً متصل، آنها را به ابزاری قدرتمند برای حل مسائل پیچیده تبدیل کرده است. بررسی تاریخی و مفهومی CNNها نشان میدهد که این معماریها نهتنها نتیجه پیشرفتهای محاسباتی، بلکه حاصل درک عمیقتری از ساختار دادههای تصویری و الهامگیری از سیستم بینایی انسان هستند.
در این مقاله، جنبههای مختلف شبکههای عصبی کانولوشنی از جمله بیان مسئله، ساختار معماری، مدل ریاضی، فرآیند آموزش، الگوریتم Backpropagation و مثالهای عددی بهصورت جامع مورد بررسی قرار گرفت. همچنین، کاربردهای واقعی CNNها در حوزههایی مانند پزشکی، خودروهای خودران و صنعت نشان داد که این شبکهها نقش کلیدی در توسعه فناوریهای هوشمند ایفا میکنند. مقایسه تحلیلی با معماریهایی مانند MLP و RNN نیز بیانگر آن است که انتخاب معماری مناسب بهشدت وابسته به نوع داده و ماهیت مسئله است.
با وجود موفقیتهای چشمگیر، CNNها همچنان با محدودیتهایی مانند نیاز به دادههای زیاد، هزینه محاسباتی بالا و تفسیرپذیری محدود مواجه هستند. پژوهشهای آینده بهسمت توسعه مدلهای کارآمدتر، قابل تفسیرتر و سازگار با منابع محدود حرکت خواهند کرد. ترکیب CNNها با معماریهای نوین مانند Transformerها، استفاده از یادگیری خودنظارتی و توسعه شبکههای سبکوزن برای کاربردهای بلادرنگ، از جمله مسیرهای پژوهشی امیدبخش در این حوزه بهشمار میروند. در مجموع، میتوان گفت که شبکههای عصبی کانولوشنی همچنان یکی از ارکان اصلی یادگیری عمیق باقی خواهند ماند و نقش آنها در حل مسائل پیچیده آینده روزبهروز پررنگتر خواهد شد.
منابع:
LeCun, Y., Bengio, Y., & Hinton, G. (2015).
Deep learning. Nature, 521(7553), 436–444.
Goodfellow, I., Bengio, Y., & Courville, A. (2016).
Deep Learning. MIT Press.
Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2012).
ImageNet classification with deep convolutional neural networks.
Advances in Neural Information Processing Systems (NeurIPS).
Simonyan, K., & Zisserman, A. (2015).
Very deep convolutional networks for large-scale image recognition.
International Conference on Learning Representations (ICLR).
He, K., Zhang, X., Ren, S., & Sun, J. (2016).
Deep residual learning for image recognition.
IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
Szegedy, C., Liu, W., Jia, Y., et al. (2015).
Going deeper with convolutions.
IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
Haykin, S. (2009).
Neural Networks and Learning Machines (3rd ed.). Pearson.
O’Shea, K., & Nash, R. (2015).
An introduction to convolutional neural networks.
arXiv:1511.08458.
Rawat, W., & Wang, Z. (2017).
Deep convolutional neural networks for image classification: A comprehensive review.
Neural Computation, 29(9), 2352–2449.
Chollet, F. (2018).
Deep Learning with Python. Manning Publications.


