

شبکههای عصبی پیشخور (Feedforward)
شبکههای عصبی پیشخور (Feedforward)
این دوره به بررسی دقیق و عمیق مباحث شبکههای عصبی پیشخور (Feedforward) به صورت پایه ای می پردازد .جهت دسترسی به سایر دوره ها می توانید از لینک های زیر استفاده نمایید.
-
شبکههای عصبی پیشخور (Feedforward)
و برای مشاهده لیست تمام دوره ها به بخش مقالات مراجه نمایید.
فهرست مطالب:
- چکیده
- مقدمه
- تعریف شبکه عصبی پیشخور
- ساختار شبکههای عصبی پیشخور
- لایه ورودی
- لایههای پنهان
- لایه خروجی
- مدل ریاضی نورون مصنوعی
- توابع فعالساز
- الگوریتم آموزش شبکههای عصبی پیشخور
- مثال عددی کامل با محاسبات گامبهگام
- مثال کدنویسی شبکه عصبی پیشخور (Python + NumPy)
- کاربردهای شبکههای عصبی پیشخور
- مزایا و معایب
- نتیجهگیری
- منابع
چکیده:
شبکههای عصبی مصنوعی یکی از مهمترین ابزارهای هوش مصنوعی و یادگیری ماشین محسوب میشوند که توانایی یادگیری الگوهای پیچیده از دادهها را دارند. در میان انواع مختلف این شبکهها، شبکههای عصبی پیشخور یا فیدفوروارد بهعنوان سادهترین و پایهایترین معماری شناخته میشوند و نقش مهمی در توسعه مدلهای پیشرفتهتر ایفا میکنند. در این مقاله، شبکههای عصبی پیشخور بهصورت جامع مورد بررسی قرار گرفتهاند. ابتدا مفاهیم پایه، ساختار و مدل ریاضی نورون مصنوعی توضیح داده شده و سپس توابع فعالساز و الگوریتم آموزش پسانتشار خطا تشریح شدهاند. در ادامه، یک مثال عددی کامل با محاسبات دقیق گامبهگام و یک پیادهسازی عملی با استفاده از زبان برنامهنویسی Python و کتابخانه NumPy ارائه شده است. در پایان نیز کاربردها، مزایا، معایب و جمعبندی علمی این نوع شبکهها بیان شده است. این مقاله میتواند بهعنوان منبعی مناسب برای دانشجویان و علاقهمندان حوزه یادگیری ماشین مورد استفاده قرار گیرد.
مقدمه:
در دهههای اخیر، رشد سریع فناوری اطلاعات و افزایش چشمگیر حجم دادهها، نیاز به روشهای هوشمند برای تحلیل دادهها و استخراج دانش را بیش از پیش آشکار ساخته است. روشهای سنتی آماری و الگوریتمهای کلاسیک در بسیاری از مسائل پیچیده کارایی لازم را ندارند. در این میان، شبکههای عصبی مصنوعی بهعنوان یکی از مهمترین شاخههای هوش مصنوعی مطرح شدهاند.
شبکههای عصبی مصنوعی با الگوبرداری از سیستم عصبی انسان طراحی شدهاند. مغز انسان از میلیاردها نورون تشکیل شده است که از طریق اتصالات پیچیده با یکدیگر در ارتباط هستند. هر نورون اطلاعات را دریافت، پردازش و به نورونهای دیگر منتقل میکند. شبکههای عصبی مصنوعی نیز با الهام از همین ایده، تلاش میکنند توانایی یادگیری، تعمیم و تصمیمگیری را در سیستمهای کامپیوتری شبیهسازی کنند.
در میان انواع مختلف شبکههای عصبی، شبکههای عصبی پیشخور اولین و سادهترین نوع محسوب میشوند. این شبکهها نقطه شروع مناسبی برای درک مفاهیم شبکههای عصبی و یادگیری عمیق هستند و به همین دلیل در آموزشهای دانشگاهی و صنعتی جایگاه ویژهای دارند.
تعریف شبکه عصبی پیشخور:
شبکه عصبی پیشخور (Feedforward Neural Network) نوعی شبکه عصبی مصنوعی است که در آن جریان اطلاعات تنها در یک جهت حرکت میکند؛ یعنی از لایه ورودی به سمت لایههای پنهان و در نهایت به لایه خروجی منتقل میشود. در این شبکهها هیچگونه حلقه بازخورد یا اتصال برگشتی وجود ندارد.
به عبارت دیگر، خروجی هر نورون فقط به نورونهای لایه بعدی ارسال میشود و هر لایه صرفاً به لایه بعد از خود متصل است. این ویژگی باعث میشود ساختار شبکه ساده و قابل تحلیل باشد.
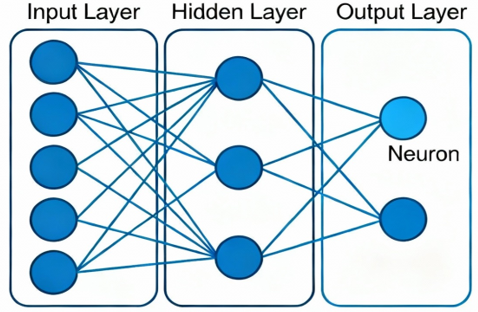
ساختار شبکههای عصبی پیشخور:
یک شبکه عصبی پیشخور معمولاً از سه بخش اصلی تشکیل شده است:
لایه ورودی (Input Layer)
لایه ورودی اولین لایه شبکه است که دادههای خام را دریافت میکند. تعداد نورونهای این لایه برابر با تعداد ویژگیهای داده ورودی است. این نورونها عملیات پردازشی انجام نمیدهند و تنها وظیفه انتقال داده به لایه بعدی را بر عهده دارند.
لایههای پنهان (Hidden Layers)
لایههای پنهان بخش اصلی پردازش شبکه را تشکیل میدهند. هر نورون در این لایهها شامل سه بخش اصلی است:
وزنها (Weights)
بایاس (Bias)
تابع فعالساز (Activation Function)
شبکه میتواند یک یا چند لایه پنهان داشته باشد. افزایش تعداد لایههای پنهان باعث افزایش توانایی شبکه در یادگیری روابط پیچیدهتر میشود، اما در عین حال پیچیدگی محاسباتی و خطر بیشبرازش را نیز افزایش میدهد.
لایه خروجی (Output Layer)
لایه خروجی نتیجه نهایی شبکه را تولید میکند. تعداد نورونهای این لایه به نوع مسئله بستگی دارد. برای مثال، در مسائل طبقهبندی دودویی معمولاً یک نورون خروجی وجود دارد، در حالی که در مسائل چندکلاسه ممکن است چندین نورون خروجی استفاده شود.
مدل ریاضی نورون مصنوعی:
هر نورون مصنوعی را میتوان با یک مدل ریاضی ساده توصیف کرد. فرض کنید ورودیهای نورون بهصورت x1، x2، …، xn و وزنهای متناظر آنها w1، w2، …، wn باشند. خروجی نورون بهصورت زیر محاسبه میشود:
z = w1x1 + w2x2 + … + wnxn + b
y = f(z)
که در آن b بایاس و f تابع فعالساز است.
توابع فعالساز:
توابع فعالساز نقش کلیدی در عملکرد شبکههای عصبی دارند و باعث ایجاد غیرخطی بودن در مدل میشوند. برخی از مهمترین توابع فعالساز عبارتند از:
تابع سیگموید(σ)
این تابع خروجی را به بازه (0،1) نگاشت میکند و بیشتر در مسائل طبقهبندی دودویی استفاده میشود.
تابع تانژانت هیپربولیک (Tanh)
این تابع خروجی را به بازه (-1،1) نگاشت میکند و نسبت به سیگموید عملکرد بهتری دارد.
تابع ReLU
تابع ReLU یکی از پرکاربردترین توابع فعالساز در شبکههای عصبی عمیق است و بهصورت max(0,x) تعریف میشود.
تابع Softmax
این تابع معمولاً در لایه خروجی شبکههای طبقهبندی چندکلاسه استفاده میشود و خروجی را بهصورت توزیع احتمال نمایش میدهد.
الگوریتم آموزش شبکههای عصبی پیشخور:
آموزش شبکههای عصبی پیشخور معمولاً با استفاده از الگوریتم پسانتشار خطا (Backpropagation) انجام میشود. این الگوریتم شامل مراحل زیر است:
-
انتشار رو به جلو (Forward Propagation)
-
محاسبه خطا با استفاده از تابع هزینه
-
محاسبه گرادیانها
-
بهروزرسانی وزنها با استفاده از روش گرادیان نزولی
آموزش شبکههای عصبی پیشخور فرآیندی تکرارشونده است که هدف آن کمینهسازی خطای خروجی شبکه نسبت به مقادیر واقعی میباشد. این فرآیند معمولاً با استفاده از الگوریتم پسانتشار خطا (Backpropagation) و یکی از روشهای بهینهسازی انجام میشود.
در مرحله نخست، دادههای ورودی به شبکه داده شده و انتشار رو به جلو (Forward Propagation) انجام میشود. در این مرحله، خروجی هر لایه با استفاده از وزنها، بایاسها و توابع فعالساز محاسبه میگردد تا خروجی نهایی شبکه به دست آید.
در مرحله دوم، خطای شبکه با استفاده از یک تابع هزینه (Loss Function) محاسبه میشود. انتخاب تابع هزینه به نوع مسئله بستگی دارد. برای مثال، در مسائل رگرسیون معمولاً از خطای میانگین مربعات (MSE) و در مسائل طبقهبندی از تابع آنتروپی متقاطع (Cross-Entropy) استفاده میشود.
در مرحله سوم، الگوریتم پسانتشار خطا با استفاده از قانون زنجیرهای مشتق، گرادیان خطا نسبت به وزنها و بایاسها را محاسبه میکند. این گرادیانها نشان میدهند که هر پارامتر شبکه چه تأثیری بر مقدار خطا دارد.
در مرحله نهایی، وزنها و بایاسها با استفاده از روشهای بهینهسازی مانند گرادیان نزولی ساده، گرادیان نزولی تصادفی (SGD)، Adam یا RMSprop بهروزرسانی میشوند. این فرآیند برای چندین دوره آموزشی (Epoch) تکرار میشود تا شبکه به همگرایی برسد.
مثال عددی کامل با محاسبات گامبهگام:
در این بخش، یک مثال عددی کامل از عملکرد یک شبکه عصبی پیشخور ساده ارائه میشود تا فرآیند محاسبه خروجی شبکه بهصورت دقیق و مرحلهبهمرحله روشن گردد.
تعریف مسئله
فرض کنید میخواهیم با استفاده از یک شبکه عصبی پیشخور، قبولی یا مردودی یک دانشجو را بر اساس دو ویژگی پیشبینی کنیم:
x1:(ساعات مطالعه در هفته)
x2: (نمره آزمون میانترم)
خروجی شبکه عددی بین 0 و 1 است که احتمال قبولی دانشجو را نشان میدهد.
ساختار شبکه
لایه ورودی: 2 نورون
لایه پنهان: 2 نورون با تابع فعالساز ReLU
لایه خروجی: 1 نورون با تابع فعالساز سیگموید
مقداردهی اولیه
فرض میکنیم مقادیر زیر برای وزنها و بایاسها انتخاب شدهاند:
لایه پنهان:
w11 = 0.3 ، w12 = 0.4 ، b1 = 0.1
w21 = 0.5 ، w22 = 0.2 ، b2 = 0.1
لایه خروجی:
v1 = 0.6 ، v2 = 0.7 ، b3 = 0.2
ورودی نمونه
x1 = 5 (ساعت مطالعه)
x2 = 14 (نمره میانترم)
محاسبات لایه پنهان
نورون اول:
z1 = (0.3 × 5) + (0.4 × 14) + 0.1 = 1.5 + 5.6 + 0.1 = 7.2
a1 = ReLU(7.2) = 7.2
نورون دوم:
z2 = (0.5 × 5) + (0.2 × 14) + 0.1 = 2.5 + 2.8 + 0.1 = 5.4
a2 = ReLU(5.4) = 5.4
محاسبات لایه خروجی
z3 = (0.6 × 7.2) + (0.7 × 5.4) + 0.2 = 4.32 + 3.78 + 0.2 = 8.3
خروجی نهایی:
y = Sigmoid(8.3) ≈ 0.9998
تفسیر نتیجه
خروجی شبکه نشان میدهد که احتمال قبولی این دانشجو بسیار بالا است.
مثال کدنویسی شبکه عصبی پیشخور (Python + NumPy):
در این بخش، یک پیادهسازی ساده از شبکه عصبی پیشخور ارائه میشود که محاسبات مثال قبل را با استفاده از کتابخانه NumPy انجام میدهد.
import numpy as np
# توابع فعالساز
def relu(x):
return np.maximum(0, x)
def sigmoid(x):
return 1 / (1 + np.exp(-x))
# ورودیها
X = np.array([5, 14])
# وزنها و بایاسها
W_hidden = np.array([[0.3, 0.4],
[0.5, 0.2]])
b_hidden = np.array([0.1, 0.1])
W_output = np.array([0.6, 0.7])
b_output = 0.2
# انتشار رو به جلو
z_hidden = np.dot(W_hidden, X) + b_hidden
a_hidden = relu(z_hidden)
z_output = np.dot(W_output, a_hidden) + b_output
y = sigmoid(z_output)
print("Output:", y)
این کد خروجیای نزدیک به مقدار محاسبهشده در مثال عددی ارائه میدهد.
کاربردهای شبکههای عصبی پیشخور:
شبکههای عصبی پیشخور در حوزههای متعددی مورد استفاده قرار میگیرند، از جمله:
تشخیص الگو
طبقهبندی دادهها
پیشبینی قیمتها
سیستمهای توصیهگر ساده
تشخیص بیماریها در مراحل اولیه
مزایا و معایب
مزایا
سادگی ساختار و پیادهسازی
قابلیت تعمیم مناسب در مسائل ساده
سرعت آموزش نسبتاً بالا
معایب
ناتوانی در پردازش دادههای ترتیبی
حساسیت به انتخاب پارامترها
نیاز به داده آموزشی مناسب
بحث و تحلیل پیشرفته:
شبکههای عصبی پیشخور اگرچه از نظر ساختاری ساده هستند، اما از دیدگاه نظری و عملی دارای جنبههای تحلیلی مهمی میباشند. یکی از موضوعات اساسی در تحلیل این شبکهها، مسئله ظرفیت یادگیری (Learning Capacity) است. ظرفیت یادگیری به توانایی شبکه در تقریب توابع پیچیده اشاره دارد. طبق قضیه تقریب جهانی (Universal Approximation Theorem)، یک شبکه عصبی پیشخور با تنها یک لایه پنهان و تعداد کافی نورون میتواند هر تابع پیوسته را با دقت دلخواه تقریب بزند. این ویژگی اهمیت شبکههای پیشخور را حتی در مقایسه با مدلهای عمیقتر نشان میدهد.
موضوع مهم دیگر، انتخاب تعداد لایهها و نورونها است. انتخاب نامناسب این پارامترها میتواند منجر به بیشبرازش یا کمبرازش شود. در مسائل واقعی، معمولاً از روشهای تجربی، اعتبارسنجی متقابل و تنظیم ابرپارامترها برای تعیین ساختار بهینه شبکه استفاده میشود.
چالشها و محدودیتهای عملی:
با وجود مزایای متعدد، شبکههای عصبی پیشخور با چالشهایی نیز مواجه هستند. یکی از مهمترین چالشها، مشکل ناپدید شدن گرادیانها (Vanishing Gradient) در شبکههای عمیق است که باعث کند شدن یا توقف فرآیند یادگیری میشود. استفاده از توابع فعالساز مناسب مانند ReLU تا حدی این مشکل را کاهش میدهد.
چالش دیگر، نیاز به دادههای آموزشی کافی و باکیفیت است. عملکرد شبکههای عصبی بهشدت به دادههای ورودی وابسته است و دادههای نویزی یا ناکافی میتوانند دقت مدل را کاهش دهند.
مقایسه شبکههای پیشخور با سایر معماریها:
شبکههای عصبی پیشخور در مقایسه با شبکههای بازگشتی (RNN) و شبکههای کانولوشنی (CNN) دارای ساختار سادهتری هستند. شبکههای بازگشتی برای دادههای ترتیبی و زمانی مناسبتر هستند، در حالی که شبکههای کانولوشنی برای پردازش تصاویر و دادههای مکانی کاربرد گستردهتری دارند. با این حال، شبکههای پیشخور همچنان در مسائل پایه، دادههای جدولی و بسیاری از کاربردهای صنعتی مورد استفاده قرار میگیرند.
کاربردهای صنعتی و پژوهشی:
در حوزه صنعت، شبکههای عصبی پیشخور به دلیل سادگی، سرعت بالا و قابلیت پیادهسازی آسان، کاربردهای فراوانی دارند. یکی از مهمترین کاربردهای آنها پیشبینی تقاضا در زنجیره تأمین و مدیریت موجودی است، جایی که این شبکهها با استفاده از دادههای تاریخی میتوانند الگوهای مصرف را شناسایی کرده و به تصمیمگیریهای مدیریتی کمک کنند.
در حوزه تحلیل ریسک مالی، شبکههای پیشخور برای پیشبینی نوسانات بازار، ارزیابی اعتبار مشتریان و مدیریت پرتفوی مورد استفاده قرار میگیرند. همچنین در سیستمهای تشخیص تقلب، این شبکهها قادرند با تحلیل الگوهای رفتاری غیرعادی، تراکنشهای مشکوک را شناسایی کنند. در بسیاری از سیستمهای پشتیبان تصمیمگیری نیز شبکههای پیشخور بهعنوان هسته اصلی تحلیل دادهها بهکار میروند و نتایج آنها به مدیران در اتخاذ تصمیمهای دقیقتر کمک میکند.
در حوزه پژوهش و دانشگاه، شبکههای عصبی پیشخور اغلب بهعنوان مدل پایه یا خط مبنا (Baseline) برای مقایسه عملکرد الگوریتمهای پیشرفتهتر مورد استفاده قرار میگیرند. پژوهشگران معمولاً ابتدا عملکرد یک شبکه پیشخور را ارزیابی کرده و سپس به سراغ معماریهای پیچیدهتر مانند شبکههای عمیق، کانولوشنی یا بازگشتی میروند. این رویکرد باعث میشود میزان بهبود حاصل از استفاده از مدلهای پیچیدهتر بهصورت دقیقتر قابل سنجش باشد.
نتیجهگیری:
شبکههای عصبی پیشخور بهعنوان یکی از بنیادیترین و در عین حال تأثیرگذارترین مدلهای یادگیری ماشین، نقش بسیار مهمی در شکلگیری و توسعه حوزه هوش مصنوعی ایفا کردهاند. این شبکهها با وجود ساختار ساده و نبود حلقههای بازخورد، قادر به مدلسازی روابط غیرخطی پیچیده از طریق ترکیب لایهها و توابع فعالساز مناسب هستند و در بسیاری از مسائل عملی عملکرد قابل قبولی ارائه میدهند.
در این مقاله، تلاش شد تا شبکههای عصبی پیشخور از جنبههای مختلف مورد بررسی قرار گیرند. ساختار کلی، مبانی ریاضی، الگوریتمهای آموزش، مثالهای عددی و پیادهسازی عملی این شبکهها بهصورت جامع تشریح شد و کاربردهای صنعتی و پژوهشی آنها مورد بحث قرار گرفت. همچنین جایگاه این شبکهها در مقایسه با سایر معماریهای پیشرفتهتر تبیین گردید.
در نهایت، میتوان گفت که درک عمیق شبکههای عصبی پیشخور برای دانشجویان، پژوهشگران و علاقهمندان حوزه یادگیری ماشین ضروری است. این شبکهها نهتنها بهعنوان ابزارهای کاربردی در بسیاری از مسائل واقعی مورد استفاده قرار میگیرند، بلکه پایهای نظری برای فهم معماریهای پیشرفتهتر شبکههای عصبی محسوب میشوند. انتظار میرود مطالب ارائهشده در این مقاله بتواند بهعنوان مرجعی آموزشی و کاربردی برای مطالعه و پژوهش در این حوزه مورد استفاده قرار گیرد.
منابع:
Goodfellow, I., Bengio, Y., & Courville, A. (2016). Deep Learning
Haykin, S. (1999). Neural Networks: A Comprehensive Foundation
Bishop, C. M. (2006). Pattern Recognition and Machine Learning




دیدگاهتان را بنویسید