

شبکه های عصبی بازگشتی:
شبکه های عصبی بازگشتی
این دوره به بررسی دقیق و عمیق مباحث شبکه عصبی به صورت پایه ای می پردازد .جهت دسترسی به سایر دوره ها می توانید از لینک های زیر استفاده نمایید.
- شبکه های عصبی بازگشتی
- شبکه عصبی بازگشتی ساده
- شبکه عصبی بازگشتی دوطرفه
- معماریهای Stacked شبکه عصبی
- شبکه عصبی GRU
- شبکه عصبی LSTM
و برای مشاهده لیست تمام دوره ها به بخش مقالات مراجه نمایید.
فهرست مطالب شبکه های عصبی بازگشتی:
- چکیده شبکههایعصبی بازگشتی
- مقدمه شبکههایعصبی بازگشتی
- بیان مسئله و انگیزه استفاده از شبکههای بازگشتی
- معرفی کلی معماری شبکه عصبی بازگشتی
- مدل مفهومی عملکرد RNN
- مدل محاسباتی و حالت پنهان (Hidden State)
- فرآیند آموزش و الگوریتم Backpropagation Through Time
- مزایا و محدودیتهای شبکه عصبی بازگشتی
- معماریهای مشتقشده از RNN وLSTM و GRU
- کاربردهای عملی شبکه عصبی بازگشتی
- تأثیر RNN بر معماریهای مدرن یادگیری عمیق
- چالشها و ملاحظات عملی
- نتیجهگیری پژوهشمحور
چکیده شبکه های عصبی بازگشتی:
(Recurrent Neural Networks – RNN) یکی از مهمترین معماریهای یادگیری عمیق برای پردازش دادههای ترتیبی و وابسته به زمان بهشمار میروند.
در مقایسه با شبکههای عصبی پیشخور که ورودیها را مستقل از یکدیگر در نظر میگیرند، شبکههای عصبی بازگشتی میتوانند اطلاعات گذشته را در قالب یک حالت درونی حفظ کرده و از آن در تحلیل ورودیهای بعدی بهره ببرند.
کاربردهای این ویژگی در حوزههایی مانند پردازش زبان طبیعی، تشخیص گفتار، پیشبینی سریهای زمانی و تحلیل سیگنالهای زیستی بسیار گسترده است.
در این مقاله، ابتدا ضرورت استفاده از شبکههای بازگشتی و محدودیتهای روشهای سنتی بررسی میشود، سپس ساختار و عملکرد کلی شبکه عصبی بازگشتی (RNN) تشریح شده و نقش آن در توسعه معماریهای پیشرفتهتر مورد بحث قرار میگیرد.
هدف اصلی، ارائه درکی جامع و مفهومی از شبکههای عصبی بازگشتی و جایگاه آنها در یادگیری عمیق مدرن است.
مقدمه شبکههایعصبی بازگشتی:
با گسترش روزافزون دادههای دیجیتال، بخش قابلتوجهی از دادههای دنیای واقعی بهصورت دنبالهای و وابسته به زمان تولید میشوند.
نمونههایی از این دادهها شامل متن، گفتار، ویدئو، دادههای مالی، سیگنالهای زیستی و دادههای حسگرها هستند که ترتیب وقوع آنها اهمیت اساسی دارد.
در این نوع دادهها، مقدار یا مفهوم یک عنصر بهشدت تحت تأثیر عناصر قبلی قرار میگیرد.
روشهای کلاسیک یادگیری ماشین و شبکههای عصبی پیشخور اغلب این وابستگی زمانی را نادیده میگیرند یا تنها بهصورت محدود در نظر میگیرند.
برای پاسخ به این چالش، شبکههای عصبی بازگشتی طراحی شدهاند و با معرفی مفهوم «حافظه» امکان ذخیره و انتقال اطلاعات از گذشته به حال را فراهم میکنند.
این قابلیت، RNNها را به یکی از ارکان اصلی یادگیری عمیق ترتیبی تبدیل کرده است.
اگرچه معماریهای پیشرفتهتر با گذشت زمان معرفی شدهاند، اما شبکههای عصبی بازگشتی همچنان نقش بنیادی در درک مفاهیم یادگیری ترتیبی و توسعه مدلهای نوین ایفا میکنند.
بیان مسئله و انگیزه استفاده از RNN:
مسئله اصلی که شبکههای عصبی بازگشتی به آن میپردازند، مدلسازی وابستگیهای زمانی و ترتیبی در دادهها است.
در بسیاری از مسائل واقعی، دادهها بهصورت توالیهایی از مشاهدات ظاهر میشوند که هر مشاهده تحت تأثیر مشاهدات قبلی قرار دارد.
برای مثال، در یک جمله زبان طبیعی، معنی یک کلمه به کلمات قبل از آن وابسته است؛ یا در پیشبینی قیمت سهام، مقدار امروز به روند روزهای گذشته بستگی دارد.
روشهای سنتی اغلب این وابستگی را نادیده میگیرند یا با مهندسی ویژگیهای دستی سعی در جبران آن دارند، که معمولاً ناکارآمد و غیرقابل تعمیم است.
استفاده از RNN انگیزهاش این است که مدل بتواند این وابستگیها را بهصورت خودکار و دادهمحور یاد بگیرد.
با نگهداری یک حالت درونی که خلاصهای از اطلاعات گذشته را در بر میگیرد، امکان استفاده از تاریخچه ورودیها در هر گام زمانی فراهم میشود.
به کمک این قابلیت، RNNها میتوانند الگوهای زمانی کوتاهمدت و بلندمدت را شناسایی کنند و در مسائلی که ترتیب دادهها نقش تعیینکننده دارد، عملکرد بهتری نسبت به مدلهای غیرترتیبی ارائه دهند.
همین ویژگی باعث شده است که RNNها بهعنوان یک راهحل طبیعی و قدرتمند برای تحلیل دادههای دنبالهای شناخته شوند.
معرفی کلی معماری شبکه های عصبی بازگشتی:
معماری شبکههای عصبی بازگشتی بر پایه ایده بازخورد (Feedback) بنا شده است.
در یک RNN، خروجی هر گام زمانی نهتنها بهعنوان نتیجه نهایی استفاده میشود، بلکه بهصورت غیرمستقیم به ورودی گام بعدی نیز منتقل میگردد.
این انتقال از طریق متغیری به نام حالت پنهان (Hidden State) انجام میشود که نقش حافظه شبکه را ایفا میکند.
هر گام زمانی با دریافت یک ورودی جدید، آن را با حالت قبلی ترکیب میکند تا حالت تازهای ساخته شود. این حالت نمایانگر خلاصهای از اطلاعات فعلی و گذشته است.
یکی از نکات مهم در RNNها این است که وزنهای شبکه در طول زمان ثابت باقی میمانند؛ یعنی همان پارامترها برای پردازش تمام عناصر دنباله بهکار میروند. این ویژگی باعث کاهش تعداد پارامترها و افزایش قابلیت تعمیم مدل میشود.
از دیدگاه مفهومی، RNN را میتوان بهصورت زنجیرهای از واحدهای مشابه در طول زمان تصور کرد که به یکدیگر متصل شدهاند. چنین ساختاری اجازه میدهد دنبالههایی با طول متغیر پردازش شوند و تصمیمگیری هر عنصر بر اساس تاریخچه صورت گیرد.
اگرچه این معماری در سادهترین شکل خود محدودیتهایی دارد، اما بهعنوان پایهای برای توسعه مدلهای حافظهدار پیشرفتهتر، نقش بسیار مهمی در یادگیری عمیق ایفا میکند.
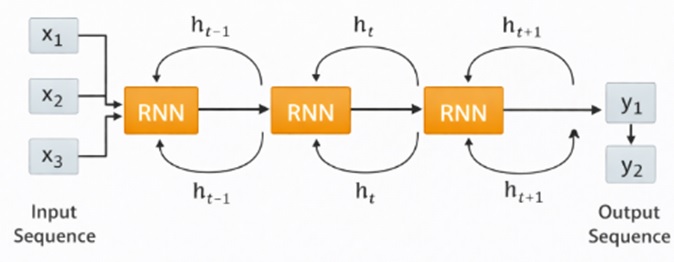
مدل مفهومی عملکرد RNN:
عملکرد RNN را میتوان بهصورت یک زنجیره از واحدهای تکرارشونده در زمان تصور کرد. هر واحد اطلاعات ورودی جدید را با حافظه گذشته ترکیب میکند. به این ترتیب، شبکه نهتنها به ورودی فعلی واکنش نشان میدهد، بلکه تاریخچهای از ورودیهای قبلی را نیز در نظر میگیرد.
این مدل مفهومی باعث میشود RNNها بتوانند الگوهایی مانند توالی کلمات، ریتم گفتار یا روندهای زمانی را یاد بگیرند. با این حال، میزان اطلاعاتی که میتوانند از گذشته حفظ کنند به ساختار شبکه و روش آموزش آن بستگی دارد.
فرض کنید یک دنباله عددی داریم:
X=[1,2,3]
میخواهیم با یک RNN ساده، در هر گام زمانی یک حالت پنهان (Hidden State) را محاسبه کنیم.
فرضیات ساده زیر را در نظر بگیر:
وزن ورودی:
Wx=0.5
وزن حالت قبلی:
Wh=0.8
بایاس:
b=0
تابع فعالساز:
Tanh
حالت اولیه:
h0=0
فرمول محاسبه حالت پنهان در RNN بهصورت زیر است:
ht = tanh( Wx · xt + Wh · h (t-1) + b )
گام اول (t = 1)
h₁ = tanh(0.5×1 + 0.8×0)
h₁ = tanh(0.5)
h₁ ≈ 0.462
گام دوم :(t = 2)
h₂ = tanh(0.5×2 + 0.8×0.462)
h₂ = tanh(1 + 0.3696)
h₂ = tanh(1.3696)
h₂ ≈ 0.879
گام سوم :(t = 3)
h₃ = tanh(0.5×3 + 0.8×0.879)
h₃ = tanh(1.5 + 0.7032)
h₃ = tanh(2.2032)
h₃ ≈ 0.976
این مثال نشان میدهد که چگونه RNN اطلاعات گامهای قبلی را در حالت پنهان خود ذخیره کرده و به گامهای بعدی منتقل میکند.
پیادهسازی همان مثال با Python (NumPy)
شبکه های عصبی بازگشتی
کد زیر دقیقاً همان محاسبات بالا را با پایتون انجام میدهد:
import numpy as np
# ورودی
x = [1, 2, 3]
# پارامترها
W_x = 0.5
W_h = 0.8
b = 0
# حالت اولیه
h = 0
# تابع فعالساز
def tanh(x):
return np.tanh(x)
# محاسبه RNN
for t, x_t in enumerate(x, start=1):
h = tanh(W_x * x_t + W_h * h + b)
print(f"h_{t} = {h:.3f}")
خروجی برنامه
h1 = 0.462
h2 = 0.879
h3 = 0.976
فرآیند آموزش و الگوریتم Backpropagation Through Time:
- آموزش RNNها با استفاده از الگوریتمی به نام Backpropagation Through Time (BPTT) انجام میشود.
در این روش، شبکه در طول زمان «باز» شده و بهصورت یک شبکه پیشخور عمیق در نظر گرفته میشود که هر لایه نمایانگر یک گام زمانی است.
گرادیان خطا سپس از انتهای دنباله به سمت ابتدا محاسبه میشود. - با این حال، این فرآیند ممکن است با مشکلاتی مانند ناپدید شدن یا انفجار گرادیانها مواجه شود.
برای کاهش این مشکلات، معمولاً از تکنیکهایی مانند برش گرادیان (Gradient Clipping) یا محدود کردن طول بازگشایی زمانی استفاده میکنند.
همین چالشها انگیزهای برای توسعه معماریهای پیشرفتهتر مانند LSTM و GRU بودهاند.
مقدمه مفهومی
شبکههای عصبی بازگشتی (RNN) بهدلیل ساختار زنجیرهای خود، قادر به مدلسازی وابستگیهای زمانی بین دادهها هستند.
برخلاف شبکههای پیشخور، در RNN خروجی هر گام زمانی به ورودی همان گام و همچنین به حالت پنهان گامهای قبلی وابسته است.
این ویژگی باعث میشود فرآیند آموزش چنین شبکهای پیچیدهتر از شبکههای معمولی باشد.
برای آموزش RNN از نسخهای تعمیمیافته از الگوریتم پسانتشار خطا استفاده میشود که به آن Backpropagation Through Time (BPTT) گفته میشود.
جمعبندی تحلیلی شبکه های عصبی بازگشتی :
هسته اصلی آموزش شبکههای عصبی بازگشتی را الگوریتم BPTT تشکیل میدهد و امکان یادگیری الگوهای زمانی را فراهم میکند.
با این حال، پیچیدگی محاسباتی، محوشدگی گرادیان و نیاز به حافظه بالا، از چالشهای اصلی آن محسوب میشوند.
این محدودیتها انگیزهای برای توسعه معماریهای پیشرفتهتر مانند LSTM، GRU و Transformer بودهاند. این مدلها همچنان از اصول پایه BPTT بهره میبرند، اما با اصلاحات ساختاری بهینه شدهاند.
مزایا و محدودیتهای شبکه های عصبی بازگشتی (RNN):
- شبکههای عصبی بازگشتی به دلیل ساختار خاص خود، مزایای قابلتوجهی در تحلیل دادههای ترتیبی ارائه میدهند.
یکی از مهمترین ویژگیهای RNN توانایی مدلسازی وابستگیهای زمانی است. با نگهداری یک حالت درونی (Hidden State)، این شبکهها قادرند اطلاعات گذشته را در تصمیمگیریهای فعلی لحاظ کنند؛ قابلیتی که در شبکههای پیشخور وجود ندارد.
به همین دلیل، کاربرد RNNها در مسائل مربوط به زبان طبیعی، صوت، سریهای زمانی و دادههای وابسته به ترتیب بسیار مناسب است. - مزیت دیگر این شبکهها، اشتراک وزنها در طول زمان است. این ویژگی باعث میشود تعداد پارامترهای شبکه نسبتاً ثابت باقی بماند و مدل بتواند دنبالههایی با طولهای متفاوت را پردازش کند. علاوه بر این، RNNها از نظر مفهومی ساده هستند و بهعنوان پایهای آموزشی برای درک معماریهای پیشرفتهتر مانند LSTM و GRU نقش مهمی ایفا میکنند.
- با وجود این مزایا، RNNهای ساده با محدودیتهای جدی مواجهاند. مشکل ناپدید شدن و انفجار گرادیانها در فرآیند آموزش، باعث میشود شبکه در یادگیری وابستگیهای بلندمدت ناکارآمد باشد؛ بهویژه در دنبالههای طولانی.
همچنین، ماهیت ترتیبی محاسبات باعث میشود آموزش این شبکهها معمولاً کندتر از شبکههای پیشخور باشد و بهینهسازی آنها نیازمند تنظیم دقیق پارامترها و استفاده از تکنیکهایی مانند Gradient Clipping است.
کاربردهای عملی شبکه های عصبی بازگشتی:
- شبکههای عصبی بازگشتی در طیف گستردهای از کاربردهای واقعی مورد استفاده قرار گرفتهاند.
یکی از مهمترین زمینهها، پردازش زبان طبیعی (NLP) است. در این حوزه، از RNNها برای مدلسازی جملات، ترجمه ماشینی، تحلیل احساسات، تکمیل خودکار متن و تولید زبان طبیعی بهره گرفته شده است. توانایی این شبکهها در درک ترتیب کلمات و وابستگی معنایی میان آنها نقش کلیدی در موفقیت این کاربردها دارد. - در حوزه تشخیص و پردازش گفتار، این شبکهها قادرند الگوهای زمانی موجود در سیگنالهای صوتی را تحلیل کرده و گفتار پیوسته انسان را به متن تبدیل کنند.
همچنین، در پیشبینی سریهای زمانی مانند قیمت سهام، دادههای اقتصادی، مصرف انرژی و پیشبینی آبوهوا، RNNها ابزار قدرتمندی برای شناسایی روندها و الگوهای زمانی محسوب میشوند. - کاربردهای RNN محدود به این موارد نیست. آنها در تحلیل سیگنالهای زیستی مانند EEG و ECG، تشخیص ناهنجاری در دادههای صنعتی، مدلسازی رفتار کاربران و حتی سیستمهای توصیهگر نیز نقش مهمی دارند. این تنوع کاربرد نشاندهنده انعطافپذیری بالای شبکههای بازگشتی در مواجهه با دادههای دنبالهای است.
تأثیر RNN بر معماریهای پیشرفته تر:
- شبکههای عصبی بازگشتی نقش بنیادینی در شکلگیری معماریهای پیشرفتهتر یادگیری عمیق ایفا کردهاند.
محدودیتهای RNNهای ساده، بهویژه در یادگیری وابستگیهای بلندمدت، منجر به معرفی معماریهایی مانند LSTM (Long Short-Term Memory) و GRU (Gated Recurrent Unit) شد. با استفاده از دروازههای کنترلی، این مدلها جریان اطلاعات و گرادیان را بهتر مدیریت کرده و عملکرد بهتری در دنبالههای طولانی ارائه میدهند. - بسیاری از ایدههای مفهومی RNNها، از جمله مدلسازی ترتیبی و توجه به زمینه (Context)، در توسعه معماریهای مدرنتری مانند Transformerها نیز تأثیرگذار بوده است.
اگرچه Transformerها ساختار بازگشتی ندارند، اما مسئلهای که RNNها مطرح کردند—یعنی درک وابستگیهای زمانی—هسته اصلی طراحی آنها را شکل میدهد. - در نتیجه، میتوان RNNها را نقطه شروعی برای تحول در یادگیری عمیق ترتیبی دانست که مسیر پژوهشهای بعدی را بهطور اساسی تغییر داده است.
شبکه های عصبی بازگشتی
نتیجه گیری شبکه های عصبی بازگشتی :
- شبکههای عصبی بازگشتی یکی از مهمترین گامها در توسعه مدلهای هوشمند برای دادههای ترتیبی محسوب میشوند.
با معرفی مفهوم حافظه و وابستگی زمانی، این شبکهها بسیاری از محدودیتهای شبکههای پیشخور را برطرف کرده و امکان کاربردهای جدید در حوزههای مختلف را فراهم کردند.
اگرچه نسخههای ساده RNN با چالشهایی مانند ناپدید شدن گرادیان و هزینه محاسباتی مواجه هستند، نقش آنها در تاریخ یادگیری عمیق غیرقابل انکار است. - از دید پژوهشی، اهمیت RNNها تنها به معماری مستقل محدود نمیشود؛ بلکه آنها بهعنوان زیربنایی برای توسعه مدلهای پیشرفتهتر نیز عمل میکنند.
درک عمیق این شبکهها به پژوهشگران کمک میکند مفاهیم کلیدی یادگیری ترتیبی را بهتر بفهمند و از آنها در طراحی مدلهای نوین بهره ببرند.
همچنان، شبکههای عصبی بازگشتی جایگاه مهمی در تحلیل دادههای زمانی دارند و پایهای اساسی برای بسیاری از پیشرفتهای آینده در هوش مصنوعی به شمار میروند.
