

شبکه عصبی معماری RNN
شبکه عصبی معماری RNN
این دوره به بررسی دقیق و عمیق مباحث شبکه عصبی به صورت پایه ای می پردازد .جهت دسترسی به سایر دوره ها می توانید از لینک های زیر استفاده نمایید.
- شبکه های عصبی بازگشتی
- شبکه عصبی بازگشتی ساده
- شبکه عصبی بازگشتی دوطرفه
- معماریهای Stacked شبکه عصبی
- شبکه عصبی معماری Encoder–Decoder RNN
- شبکه عصبی GRU
- شبکه عصبی LSTM
و برای مشاهده لیست تمام دوره ها به بخش مقالات مراجه نمایید.
فهرست مطالب:
- چکیده
- مقدمه
- بیان مسئله و انگیزه استفاده از معماری Encoder–Decoder
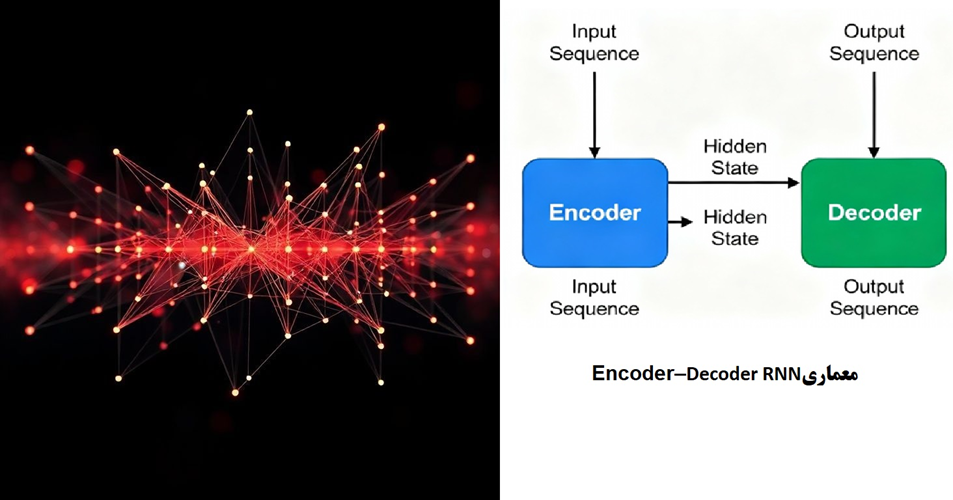
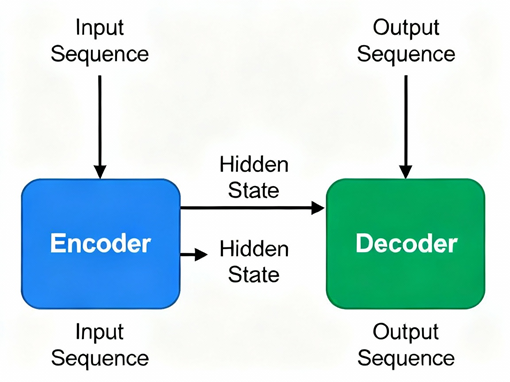
- معرفی معماری Encoder–Decoder RNN
- عملکرد مفهومی Encoder
- عملکرد مفهومی Decoder
- فرآیند آموزش Encoder–Decoder RNN
- مزایا و محدودیتهای معماری Encoder–Decoder
- کاربردهای عملی
- نتیجهگیری پژوهشمحور
- منابع
چکیده:
- معماری Encoder–Decoder یکی از مهمترین چارچوبهای یادگیری عمیق برای حل مسائل نگاشت دنباله به دنباله (Sequence-to-Sequence) بهشمار میرود. در بسیاری از کاربردهای واقعی، دادهها بهصورت دنبالههایی با طول متغیر ظاهر میشوند و رابطهای پیچیده و غیرخطی میان دنباله ورودی و خروجی وجود دارد. شبکههای عصبی بازگشتی کلاسیک، که خروجی را بهطور همزمان با ورودی تولید میکنند، معمولاً در مواجهه با چنین مسائلی با محدودیتهایی روبهرو هستند.
- در این مقاله، معماری Encoder–Decoder RNN بهعنوان راهحلی مؤثر برای مدلسازی نگاشت میان دنبالهها مورد بررسی قرار میگیرد. در این چارچوب، بخش Encoder وظیفه تحلیل و فشردهسازی اطلاعات دنباله ورودی را بر عهده دارد و بخش Decoder با استفاده از این نمایش فشرده، دنباله خروجی را تولید میکند. هدف این مقاله ارائه درکی جامع و مفهومی از معماری Encoder–Decoder RNN، بررسی انگیزه استفاده از آن و تبیین ساختار و عملکرد کلی این معماری در یادگیری عمیق ترتیبی است.
مقدمه:
- با رشد روزافزون دادههای دیجیتال، بسیاری از مسائل یادگیری ماشین بهصورت طبیعی در قالب دادههای ترتیبی و دنبالهای تعریف میشوند. زبان طبیعی، گفتار، دادههای زمانی، توالی رویدادها و سیگنالهای مختلف نمونههایی از دادههایی هستند که ترتیب وقوع آنها نقش اساسی در معنا و تفسیر دارد. در چنین مسائلی، هدف اغلب یادگیری نگاشتی میان یک دنباله ورودی و یک دنباله خروجی است که ممکن است طول آنها با یکدیگر متفاوت باشد.
- شبکههای عصبی بازگشتی بهعنوان یکی از نخستین ابزارهای مؤثر برای پردازش دادههای ترتیبی معرفی شدند و با بهرهگیری از مفهوم حالت پنهان، امکان مدلسازی وابستگیهای زمانی را فراهم کردند. با این حال، RNNهای ساده معمولاً برای تولید خروجی در هر گام زمانی طراحی شدهاند و در مسائل دنبالهبهدنباله، که نیازمند درک کلی ورودی پیش از تولید خروجی هستند، عملکرد محدودی دارند.
- برای رفع این محدودیت، معماری Encoder–Decoder معرفی شد. این معماری با جداسازی فرآیند پردازش ورودی و تولید خروجی، امکان مدلسازی انعطافپذیرتر و قدرتمندتر نگاشت میان دنبالهها را فراهم میکند. معماری Encoder–Decoder نهتنها در بسیاری از کاربردهای عملی موفق بوده است، بلکه نقش مهمی در شکلگیری معماریهای پیشرفتهتر یادگیری عمیق ایفا کرده است.
شبکه عصبی معماری RNN
بیان مسئله و انگیزه استفاده از Encoder–Decoder RNN:
- مسئله اصلی در بسیاری از کاربردهای یادگیری ترتیبی، ناتوانی مدلهای ساده در مدیریت وابستگیهای پیچیده میان دنبالههای ورودی و خروجی است. در یک RNN کلاسیک، خروجی هر گام زمانی مستقیماً به ورودی همان گام و حالتهای قبلی وابسته است. این ساختار برای مسائلی که خروجی تنها پس از مشاهده کامل ورودی معنا پیدا میکند، مناسب نیست.
- بهعنوان مثال، در ترجمه ماشینی، برای تولید ترجمه صحیح یک جمله، اغلب لازم است کل جمله مبدأ ابتدا درک شود. در چنین حالتی، تولید خروجی بهصورت گامبهگام همزمان با ورودی میتواند منجر به نتایج ناپایدار و نادقیق شود. این محدودیت در سایر مسائل مانند خلاصهسازی متن، پاسخدهی به پرسشها و تبدیل گفتار به متن نیز مشاهده میشود.
- انگیزه اصلی استفاده از معماری Encoder–Decoder RNN این است که ابتدا دنباله ورودی بهطور کامل پردازش شده و اطلاعات آن در قالب یک نمایش فشرده و معنادار ذخیره شود. سپس، این نمایش بهعنوان مبنای تولید دنباله خروجی مورد استفاده قرار گیرد. این رویکرد به مدل اجازه میدهد وابستگیهای بلندمدت و روابط غیرمحلی میان عناصر دنبالهها را بهتر یاد بگیرد و نگاشتهای پیچیدهتری را مدلسازی کند.
معرفی معماری Encoder–Decoder RNN:
- معماری Encoder–Decoder RNN از دو بخش اصلی تشکیل شده است: بخش رمزگذار (Encoder) و بخش رمزگشا (Decoder). بخش Encoder یک شبکه عصبی بازگشتی است که دنباله ورودی را بهصورت ترتیبی دریافت میکند و در هر گام زمانی، حالت پنهان خود را بهروزرسانی میکند. حالت پنهان نهایی Encoder بهعنوان خلاصهای از کل دنباله ورودی در نظر گرفته میشود که اطلاعات زمانی و معنایی آن را در خود جای داده است.
- بخش Decoder نیز یک شبکه عصبی بازگشتی مستقل است که فرآیند تولید دنباله خروجی را بر عهده دارد. Decoder با استفاده از نمایش فشرده تولیدشده توسط Encoder بهعنوان حالت اولیه خود، تولید خروجی را آغاز میکند و در هر گام زمانی، یک عنصر از دنباله خروجی را تولید مینماید. این فرآیند تا زمانی ادامه مییابد که نماد پایان دنباله تولید شود.
- در این معماری، Encoder و Decoder میتوانند از واحدهای بازگشتی مختلفی مانند RNN ساده، LSTM یا GRU استفاده کنند. این انعطافپذیری باعث میشود معماری Encoder–Decoder بتواند با توجه به پیچیدگی مسئله و منابع محاسباتی، بهصورت مؤثر تنظیم شود. بهطور کلی، این معماری چارچوبی عمومی و قدرتمند برای مدلسازی مسائل دنبالهبهدنباله فراهم میکند و نقش بنیادینی در یادگیری عمیق ترتیبی ایفا کرده است.
شبکه عصبی معماری RNN
عملکرد مفهومی Encoder:
- Encoder بخش نخست معماری Encoder–Decoder RNN است که وظیفه تحلیل و رمزگذاری دنباله ورودی را بر عهده دارد. این بخش معمولاً از یک شبکه عصبی بازگشتی تشکیل شده است که عناصر دنباله ورودی را بهصورت ترتیبی و گامبهگام دریافت میکند. در هر گام زمانی، Encoder ورودی جدید را با حالت پنهان قبلی ترکیب کرده و یک حالت پنهان بهروزرسانیشده تولید میکند. این حالت پنهان بهعنوان حافظهای از اطلاعات مشاهدهشده تا آن لحظه عمل میکند.
- در طول پردازش دنباله، Encoder بهتدریج اطلاعات زمانی و معنایی ورودی را در حالتهای پنهان خود انباشته میکند. حالت پنهان نهایی Encoder معمولاً بهعنوان یک نمایش فشرده از کل دنباله ورودی در نظر گرفته میشود. این نمایش شامل خلاصهای از مهمترین ویژگیها و وابستگیهای زمانی موجود در دنباله است و نقش کلیدی در عملکرد کل معماری ایفا میکند.
- کیفیت این نمایش فشرده تأثیر مستقیمی بر دقت و پایداری خروجی Decoder دارد. اگر Encoder نتواند اطلاعات حیاتی دنباله ورودی را بهطور کامل یا مؤثر ذخیره کند، Decoder در تولید دنباله خروجی مناسب با مشکل مواجه خواهد شد. این مسئله بهویژه در دنبالههای طولانی اهمیت بیشتری پیدا میکند، زیرا فشردهسازی حجم زیادی از اطلاعات در یک بردار واحد میتواند منجر به از دست رفتن جزئیات مهم شود. به همین دلیل، طراحی Encoder و انتخاب نوع واحد بازگشتی در آن نقش تعیینکنندهای در موفقیت معماری Encoder–Decoder دارد.
عملکرد مفهومی Decoder:
- Decoder بخش دوم معماری Encoder–Decoder RNN است که وظیفه تولید دنباله خروجی را بر عهده دارد. این بخش نیز معمولاً از یک شبکه عصبی بازگشتی تشکیل شده است که با استفاده از نمایش فشرده تولیدشده توسط Encoder، فرآیند تولید خروجی را آغاز میکند. حالت اولیه Decoder معمولاً برابر با حالت پنهان نهایی Encoder در نظر گرفته میشود، که این امر باعث انتقال اطلاعات رمزگذاریشده ورودی به فرآیند رمزگشایی میگردد.
- در هر گام زمانی، Decoder با توجه به حالت پنهان فعلی و خروجی تولیدشده در گام قبلی، یک عنصر جدید از دنباله خروجی را پیشبینی میکند. این وابستگی به خروجیهای قبلی باعث میشود تولید دنباله خروجی بهصورت پیوسته و منسجم انجام شود. فرآیند تولید تا زمانی ادامه مییابد که مدل یک نماد پایان دنباله تولید کند یا به طول مشخصی از خروجی برسد.
- Decoder باید بتواند بر اساس اطلاعات فشرده Encoder، ترتیب، ساختار و وابستگیهای درونی دنباله خروجی را بهدرستی بازسازی کند. این کار مستلزم آن است که Decoder نهتنها اطلاعات کلی دنباله ورودی را درک کند، بلکه بتواند آن را به شکلی مناسب برای تولید خروجی تفسیر نماید. در نتیجه، عملکرد Decoder بهشدت به کیفیت اطلاعات منتقلشده از Encoder وابسته است و تعامل مؤثر میان این دو بخش، عامل اصلی موفقیت معماری Encoder–Decoder محسوب میشود.
فرآیند آموزش Encoder–Decoder RNN:
- آموزش معماری Encoder–Decoder RNN معمولاً با استفاده از الگوریتم Backpropagation Through Time (BPTT) انجام میشود. در این فرآیند، شبکه هم در بعد زمان و هم در بعد ساختاری (Encoder و Decoder) بازگشایی میشود. ابتدا دنباله ورودی توسط Encoder پردازش شده و سپس Decoder بر اساس خروجی Encoder دنباله خروجی را تولید میکند. خطای تولید خروجی با استفاده از تابع هزینه مناسب محاسبه میشود.
- گرادیانهای خطا از خروجی Decoder به سمت لایههای قبلی منتقل میشوند و در نهایت به Encoder نیز بازمیگردند. این امر باعث میشود هر دو بخش Encoder و Decoder بهصورت همزمان و هماهنگ بهینه شوند. با این حال، به دلیل عمق شبکه در بعد زمان و ساختار، آموزش این معماری میتواند با چالشهایی مانند ناپدید شدن یا انفجار گرادیانها همراه باشد.
- برای بهبود پایداری و سرعت آموزش، معمولاً از تکنیکهایی مانند Teacher Forcing استفاده میشود. در این روش، در طول آموزش، خروجی صحیح گام قبلی بهعنوان ورودی گام بعدی Decoder مورد استفاده قرار میگیرد. این کار باعث میشود مدل سریعتر همگرا شود و خطاهای انباشتهشده در مراحل ابتدایی آموزش کاهش یابد. همچنین، استفاده از تکنیکهایی مانند Gradient Clipping و منظمسازی میتواند به بهبود عملکرد و پایداری فرآیند آموزش کمک کند.
- در مجموع، فرآیند آموزش Encoder–Decoder RNN پیچیدهتر از RNNهای ساده است و نیازمند تنظیم دقیق پارامترها و انتخاب مناسب ساختار مدل میباشد. با این حال، در صورت طراحی و آموزش صحیح، این معماری قادر است نگاشتهای پیچیده دنبالهبهدنباله را با دقت بالایی یاد بگیرد.
مثال عددی بسیار مختصر Encoder–Decoder RNN:
دنباله ورودی:
X=[1, 2]
یک Encoder–Decoder RNN ساده با تابع tanh در نظر میگیریم.
Encoder:
ht=tanh(0.5xt+0.5ht−1)
h2≈0.85نمایش فشرده دنباله ورودی
Decoder:
yt=tanh(0.5ht)
y1≈0.40
y2≈0.38
شبکه عصبی معماری RNN
کد پایتون (خیلی کوتاه):
import numpy as np
h = 0
for x in [1, 2]:
h = np.tanh(0.5*x + 0.5*h)
y = [np.tanh(0.5*h), np.tanh(0.5*h)]
print(round(h,2), [round(v,2) for v in y])
این مثال ساده نشان میدهد که Encoder دنباله ورودی را به یک نمایش فشرده تبدیل کرده و Decoder بر اساس آن، دنباله خروجی را تولید میکند.
مزایا و محدودیتهای معماری Encoder–Decoder:
- معماری Encoder–Decoder یکی از انعطافپذیرترین چارچوبها برای مدلسازی مسائل نگاشت دنباله به دنباله محسوب میشود. مهمترین مزیت این معماری، توانایی آن در پردازش دنبالههایی با طول متغیر است. برخلاف RNNهای ساده که معمولاً خروجی را بهصورت همزمان با ورودی تولید میکنند، Encoder–Decoder ابتدا کل دنباله ورودی را تحلیل کرده و سپس فرآیند تولید خروجی را آغاز میکند. این ویژگی باعث میشود مدل بتواند وابستگیهای پیچیده و غیرمحلی میان عناصر ورودی و خروجی را بهتر درک کند.
- از دیگر مزایای مهم این معماری، جداسازی وظیفه رمزگذاری و رمزگشایی اطلاعات است. بخش Encoder مسئول استخراج اطلاعات و فشردهسازی آن در قالب یک نمایش معنادار است، در حالی که Decoder وظیفه بازسازی یا تولید دنباله خروجی را بر عهده دارد. این تفکیک ساختاری، طراحی مدل را سادهتر کرده و امکان استفاده از انواع مختلف واحدهای بازگشتی مانند RNN، LSTM و GRU را در هر یک از بخشها فراهم میسازد. همچنین، معماری Encoder–Decoder پایهای برای توسعه روشهای پیشرفتهتر مانند Attention و Transformer بوده است که نقش مهمی در پیشرفت یادگیری عمیق ترتیبی ایفا کردهاند.
- با وجود مزایای قابلتوجه، این معماری دارای محدودیتهای اساسی نیز هست. مهمترین محدودیت Encoder–Decoder کلاسیک، وابستگی Decoder به یک نمایش فشرده ثابت از دنباله ورودی است. در دنبالههای طولانی، این نمایش ممکن است نتواند تمام اطلاعات ضروری را بهطور کامل ذخیره کند و در نتیجه، کیفیت خروجی کاهش یابد. این مشکل که به «گلوگاه اطلاعاتی» معروف است، یکی از چالشهای اصلی این معماری محسوب میشود.
- علاوه بر این، آموزش مدلهای Encoder–Decoder میتواند پرهزینه و زمانبر باشد، بهویژه زمانی که از واحدهای بازگشتی پیچیده مانند LSTM استفاده میشود. حساسیت به تنظیم پارامترها، خطر بیشبرازش در صورت کمبود داده و نیاز به منابع محاسباتی بالا از دیگر محدودیتهای عملی این معماری بهشمار میروند. این چالشها نشان میدهند که استفاده مؤثر از Encoder–Decoder نیازمند طراحی دقیق و انتخاب آگاهانه ساختار مدل است.
کاربردهای عملی:
- معماری Encoder–Decoder RNN در طیف گستردهای از کاربردهای واقعی مورد استفاده قرار گرفته و نقش مهمی در پیشرفت سیستمهای هوشمند ایفا کرده است. یکی از شناختهشدهترین کاربردهای این معماری، ترجمه ماشینی عصبی است. در این مسئله، جمله ورودی به زبان مبدأ توسط Encoder پردازش شده و Decoder بر اساس نمایش استخراجشده، جملهای معادل در زبان مقصد تولید میکند. این چارچوب پایه بسیاری از سیستمهای ترجمه ماشینی مدرن بوده است.
- در حوزه پردازش زبان طبیعی، Encoder–Decoder در وظایفی مانند خلاصهسازی متن، تولید متن، پاسخدهی به پرسشها و بازنویسی جملات نیز بهکار گرفته شده است. توانایی این معماری در درک ساختار کلی متن و تولید خروجی منسجم، آن را به گزینهای مناسب برای این دسته از کاربردها تبدیل کرده است.
- در پردازش گفتار، از معماری Encoder–Decoder برای تبدیل گفتار به متن و همچنین تبدیل متن به گفتار استفاده میشود. سیگنالهای صوتی دارای ساختار زمانی پیچیدهای هستند و Encoder–Decoder با جداسازی مراحل تحلیل و تولید، امکان مدلسازی مؤثر این سیگنالها را فراهم میکند. علاوه بر این، این معماری در کاربردهایی مانند تشخیص دستخط، تبدیل فرمتهای زمانی داده، تولید توصیف خودکار برای تصاویر و ویدئوها و سیستمهای دیالوگ نیز مورد استفاده قرار گرفته است. تنوع این کاربردها نشاندهنده توان بالای معماری Encoder–Decoder در مواجهه با مسائل دنبالهبهدنباله است.
نتیجهگیری:
- معماری Encoder–Decoder RNN را میتوان یکی از چارچوبهای بنیادین در یادگیری عمیق ترتیبی دانست که امکان مدلسازی نگاشت میان دنبالهها را بهطور مؤثر فراهم میکند. این معماری با جداسازی فرآیند رمزگذاری و رمزگشایی، توانسته است بسیاری از محدودیتهای RNNهای ساده را در مسائل دنبالهبهدنباله برطرف کند و راه را برای توسعه مدلهای پیشرفتهتر هموار سازد.
- اگرچه نسخه کلاسیک Encoder–Decoder با چالشهایی مانند گلوگاه اطلاعاتی و هزینه محاسباتی بالا مواجه است، اما نقش آن در تاریخچه یادگیری عمیق غیرقابل انکار است. بسیاری از معماریهای مدرن، از جمله مدلهای مبتنی بر Attention و Transformer، بهطور مستقیم یا غیرمستقیم از ایدههای این چارچوب الهام گرفتهاند.
- در نهایت، درک دقیق معماری Encoder–Decoder و محدودیتهای آن برای پژوهشگران و مهندسان یادگیری ماشین اهمیت ویژهای دارد، زیرا این معماری همچنان بهعنوان یکی از مفاهیم پایه در طراحی سیستمهای هوشمند مبتنی بر دادههای ترتیبی مورد استفاده قرار میگیرد.
منابع:
شبکه عصبی معماری RNN
- Elman, J. L. (1990). Finding structure in time. Cognitive Science, 14(2), 179–211.
- Rumelhart, D. E., Hinton, G. E., & Williams, R. J. (1986). Learning representations by back-propagating errors. Nature, 323, 533–536.
- Sutskever, I., Vinyals, O., & Le, Q. V. (2014). Sequence to sequence learning with neural networks. Advances in Neural Information Processing Systems.
- Cho, K., et al. (2014). Learning phrase representations using RNN encoder–decoder for statistical machine translation. arXiv:1406.1078.
- Goodfellow, I., Bengio, Y., & Courville, A. (2016). Deep Learning. MIT Press.
