

شبکههای کاملاً متصل پیشخور (Fully Connected Feedforward Neural Networks)
شبکههای کاملاً متصل پیشخور (Fully Connected Feedforward Neural Networks)
این دوره به بررسی دقیق و عمیق مباحث شبکههای کاملاً متصل پیشخور به صورت پایه ای می پردازد .جهت دسترسی به سایر دوره ها می توانید از لینک های زیر استفاده نمایید.
-
شبکههای کاملاً متصل پیشخور (Fully Connected Feedforward Neural Networks)
و برای مشاهده لیست تمام دوره ها به بخش مقالات مراجه نمایید.
فهرست مطالب:
- چکیده
- مقدمه
- بیان مسئله و اهمیت موضوع
- تعریف شبکههای کاملاً متصل پیشخور
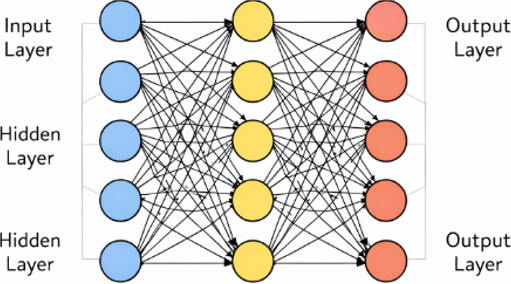
- ساختار و معماری شبکه
- لایه ورودی
- لایههای پنهان
- لایه خروجی
- مدل ریاضی نورون مصنوعی
- توابع فعالساز رایج
- فرآیند انتشار رو به جلو (Forward Propagation)
- الگوریتم آموزش و پسانتشار خطا
- مثال عددی کامل با محاسبات گامبهگام
- پیادهسازی عملی با Python و NumPy
- چالشها و ملاحظات عملی
- کاربردها
- مقایسه با سایر معماریهای شبکه عصبی
- نتیجهگیری علمی و جمعبندی
- منابع
چکیده:
شبکههای عصبی کاملاً متصل پیشخور یکی از بنیادیترین و پرکاربردترین معماریهای شبکههای عصبی مصنوعی به شمار میروند. در این نوع شبکهها، هر نورون در یک لایه به تمام نورونهای لایه بعدی متصل است و جریان داده تنها در یک جهت، از لایه ورودی به سمت لایه خروجی، حرکت میکند. این شبکهها پایه بسیاری از مدلهای یادگیری ماشین و شبکههای عصبی عمیق محسوب میشوند و نقش مهمی در درک مفاهیم اصلی مانند یادگیری غیرخطی، تنظیم وزنها و الگوریتم پسانتشار خطا دارند. در این مقاله، شبکههای کاملاً متصل پیشخور از جنبههای مختلف شامل ساختار، مدل ریاضی، الگوریتم آموزش، مثالهای عددی و پیادهسازی عملی مورد بررسی جامع قرار میگیرند.
مقدمه:
در دهههای اخیر، رشد چشمگیر دادهها و پیشرفت توان محاسباتی باعث شده است که شبکههای عصبی مصنوعی به یکی از مهمترین ابزارهای تحلیل داده و یادگیری ماشین تبدیل شوند. در میان انواع مختلف شبکههای عصبی، شبکههای پیشخور کاملاً متصل بهعنوان سادهترین و در عین حال پایهایترین معماری شناخته میشوند. این شبکهها الهامگرفته از ساختار نورونهای زیستی بوده و با ترکیب وزنها، بایاس و توابع فعالساز، قادر به مدلسازی روابط پیچیده بین دادهها هستند.
اهمیت این شبکهها تنها به کاربردهای عملی آنها محدود نمیشود، بلکه نقش آموزشی بسیار مهمی نیز دارند. بسیاری از مفاهیم کلیدی شبکههای عصبی مانند یادگیری نظارتشده، گرادیان نزولی و پسانتشار خطا نخستین بار در قالب همین معماریها مطرح و بررسی شدهاند. به همین دلیل، شناخت دقیق شبکههای کاملاً متصل پیشخور برای هر دانشجو یا پژوهشگر حوزه هوش مصنوعی ضروری است.
بیان مسئله و اهمیت موضوع:
در بسیاری از کاربردهای واقعی یادگیری ماشین، دادهها دارای ساختار پیچیده، همبستگیهای غیرخطی و الگوهایی هستند که با مدلهای ساده و خطی قابل شناسایی نیستند. روشهای کلاسیک آماری و مدلهای خطی، اگرچه در مسائل ساده عملکرد قابل قبولی دارند، اما در مواجهه با دادههای پرحجم و پیچیده معمولاً با محدودیتهای جدی روبهرو میشوند. مسئله اصلی این است که چگونه میتوان مدلی طراحی کرد که بدون نیاز به تعریف صریح روابط ریاضی پیچیده، بتواند از روی دادهها الگوهای پنهان را استخراج کند.
شبکههای کاملاً متصل پیشخور بهعنوان یکی از نخستین پاسخها به این مسئله مطرح شدند. این شبکهها با الهام از ساختار نورونهای زیستی و با استفاده از لایههای متوالی، قادرند نگاشتی انعطافپذیر بین فضای ورودی و خروجی ایجاد کنند. افزودن لایههای پنهان و استفاده از توابع فعالساز غیرخطی باعث میشود که شبکه بتواند تقریب مناسبی از توابع پیچیده ارائه دهد؛ قابلیتی که از نظر تئوری با قضیه تقریب جهانی نیز پشتیبانی میشود.
اهمیت بررسی این نوع شبکهها تنها به کاربردهای عملی آنها محدود نمیشود. شبکههای کاملاً متصل پیشخور، پایه و اساس بسیاری از معماریهای پیشرفتهتر شبکههای عصبی محسوب میشوند. درک دقیق این معماری به پژوهشگران کمک میکند تا منطق عملکرد شبکههای عمیقتر را بهتر تحلیل کرده و انتخاب آگاهانهتری در طراحی مدلهای یادگیری ماشین داشته باشند.
تعریف شبکههای کاملاً متصل پیشخور:
شبکه عصبی کاملاً متصل پیشخور نوعی شبکه عصبی مصنوعی است که در آن هر نورون یک لایه به تمام نورونهای لایه بعدی متصل میشود. در این شبکهها، هیچ حلقه بازگشتی وجود ندارد و دادهها فقط در یک مسیر مشخص از ورودی به خروجی حرکت میکنند.
این ویژگی باعث میشود تحلیل ریاضی و پیادهسازی این شبکهها نسبتاً ساده باشد. با این حال، همین ساختار ساده میتواند توانایی بالایی در یادگیری روابط غیرخطی ایجاد کند، بهویژه زمانی که تعداد لایههای پنهان افزایش یابد.
ساختار و معماری شبکه:
لایه ورودی
لایه ورودی مسئول دریافت دادههای خام است. هر نورون در این لایه معمولاً متناظر با یک ویژگی از داده ورودی است و عملیات محاسباتی خاصی انجام نمیدهد.
لایههای پنهان
لایههای پنهان هسته اصلی شبکههای کاملاً متصل هستند. این لایهها با ترکیب خطی ورودیها و اعمال توابع فعالساز غیرخطی، الگوهای پیچیده را استخراج میکنند. افزایش تعداد لایههای پنهان باعث افزایش ظرفیت یادگیری شبکه میشود.
لایه خروجی
لایه خروجی نتیجه نهایی شبکه را تولید میکند. نوع تابع فعالساز در این لایه به نوع مسئله بستگی دارد؛ برای مثال، در مسائل طبقهبندی دودویی از تابع سیگموید و در مسائل چندکلاسه از Softmax استفاده میشود.
مدل ریاضی نورون مصنوعی:
مدل ریاضی هر نورون در شبکههای کاملاً متصل بهصورت زیر تعریف میشود:
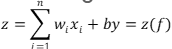
در این روابط، x_i ورودیها، w_i وزنها، b بایاس و f تابع فعالساز است. این مدل نشان میدهد که نورون چگونه اطلاعات ورودی را ترکیب کرده و خروجی تولید میکند.
توابع فعالساز رایج:
توابع فعالساز نقش حیاتی در توانایی شبکه برای یادگیری روابط غیرخطی دارند. از جمله توابع پرکاربرد میتوان به سیگموید، تانژانت هیپربولیک و ReLU اشاره کرد. انتخاب تابع فعالساز مناسب تأثیر مستقیمی بر سرعت همگرایی و عملکرد شبکه دارد.
فرآیند انتشار رو به جلو (Forward Propagation):
در فرآیند انتشار رو به جلو، دادهها از لایه ورودی وارد شبکه شده و بهصورت مرحلهبهمرحله به سمت لایه خروجی منتقل میشوند. در هر لایه، ابتدا مجموع وزندار ورودیها محاسبه شده و سپس تابع فعالساز اعمال میشود. خروجی هر لایه بهعنوان ورودی لایه بعدی استفاده میگردد.
الگوریتم آموزش و پسانتشار خطا:
آموزش شبکههای کاملاً متصل پیشخور معمولاً با استفاده از الگوریتم پسانتشار خطا انجام میشود. این الگوریتم شامل محاسبه خطا در خروجی، انتقال معکوس خطا به لایههای قبلی و بهروزرسانی وزنها با استفاده از گرادیان نزولی است.
مثال عددی کامل با محاسبات گامبهگام:
فرض کنید شبکهای با دو ورودی، یک لایه پنهان و یک خروجی داریم. با مشخص بودن وزنها و بایاسها، میتوان مقدار خروجی هر نورون را بهصورت مرحلهبهمرحله محاسبه کرد تا عملکرد شبکه بهصورت شفاف درک شود
برای درک دقیقتر عملکرد شبکههای کاملاً متصل پیشخور، یک مثال عددی ساده اما کامل را بررسی میکنیم. فرض کنید شبکهای با دو ورودی، یک لایه پنهان شامل دو نورون و یک نورون خروجی داریم. تابع فعالساز لایه پنهان ReLU و تابع فعالساز لایه خروجی سیگموید در نظر گرفته میشود.
ورودیها:
- x1 = 1
- x2 = 0.5
وزنهای لایه پنهان:
- نورون اول: w11 = 0.2 ، w12 = 0.4 ، b1 = 0.1
- نورون دوم: w21 = 0.3 ، w22 = 0.1 ، b2 = -0.2
محاسبه مجموع وزندار برای نورونهای لایه پنهان:
z1 = (0.2 × 1) + (0.4 × 0.5) + 0.1 = 0.5
z2 = (0.3 × 1) + (0.1 × 0.5) − 0.2 = 0.15
اعمال تابع فعالساز ReLU:
a1 = max(0, 0.5) = 0.5
a2 = max(0, 0.15) = 0.15
حال خروجیهای لایه پنهان به نورون خروجی منتقل میشوند. فرض میکنیم وزنها و بایاس لایه خروجی بهصورت زیر باشند:
- w31 = 0.6 ، w32 = 0.9 ، b3 = 0.05
مجموع وزندار نورون خروجی:
z3 = (0.6 × 0.5) + (0.9 × 0.15) + 0.05 = 0.485
اعمال تابع فعالساز سیگموید:
y = 1 / (1 + e^(−0.485)) ≈ 0.62
این مقدار خروجی نهایی شبکه است. این مثال نشان میدهد که چگونه دادهها بهصورت مرحلهبهمرحله در یک شبکه کاملاً متصل پیشخور پردازش میشوند.
پیادهسازی عملی با Python و NumPy:
import numpy as np
def relu(x):
return np.maximum(0, x)
X = np.array([1.0, 0.5])
W = np.array([[0.2, 0.4], [0.3, 0.1]])
b = np.array([0.1, -0.2])
z = np.dot(W, X) + b
y = relu(z)
print(y)
چالشها و ملاحظات عملی:
با وجود مزایای متعدد شبکههای کاملاً متصل پیشخور، استفاده عملی از این شبکهها با چالشهایی همراه است که توجه به آنها برای دستیابی به عملکرد مطلوب ضروری است. یکی از مهمترین چالشها، افزایش سریع تعداد پارامترها با افزایش تعداد لایهها و نورونها است. در شبکههای کاملاً متصل، هر نورون به تمام نورونهای لایه بعدی متصل میشود و این موضوع باعث افزایش قابلتوجه تعداد وزنها و در نتیجه هزینه محاسباتی و حافظه مورد نیاز میگردد.
چالش دیگر، پدیده بیشبرازش است. زمانی که شبکه ظرفیت یادگیری بسیار بالایی داشته باشد، ممکن است بهجای یادگیری الگوی کلی دادهها، نویز موجود در دادههای آموزشی را یاد بگیرد. برای مقابله با این مشکل، روشهایی مانند کاهش پیچیدگی مدل، استفاده از دادههای اعتبارسنجی، توقف زودهنگام و تکنیکهایی مانند Dropout مورد استفاده قرار میگیرند.
از سوی دیگر، حساسیت شبکههای کاملاً متصل به مقیاس دادههای ورودی نیز یک ملاحظه مهم محسوب میشود. دادههایی با دامنههای متفاوت میتوانند فرآیند آموزش را ناپایدار کنند. به همین دلیل، نرمالسازی یا استانداردسازی دادهها پیش از آموزش شبکه یک مرحله ضروری در کاربردهای عملی به شمار میرود.
کاربردها:
این شبکهها در مسائل طبقهبندی، رگرسیون، تحلیل دادههای پزشکی، مالی و سیستمهای پیشبینی کاربرد گستردهای دارند.
شبکههای کاملاً متصل پیشخور به دلیل سادگی ساختار و انعطافپذیری بالا، در طیف گستردهای از مسائل واقعی مورد استفاده قرار گرفتهاند. یکی از مهمترین کاربردهای این شبکهها در مسائل طبقهبندی دادههای جدولی است؛ مسائلی که در آنها هر نمونه داده با مجموعهای از ویژگیهای عددی یا دستهای توصیف میشود و هدف، پیشبینی یک برچسب مشخص است. برای مثال، در تشخیص اعتبار مشتریان بانکی، پیشبینی ریسک اعتباری یا تحلیل دادههای مالی، شبکههای کاملاً متصل عملکرد قابل قبولی از خود نشان دادهاند.
در حوزه پزشکی نیز این شبکهها کاربردهای متعددی دارند. تحلیل دادههای آزمایشگاهی، پیشبینی بیماریها بر اساس ویژگیهای بالینی و مدلسازی روابط بین شاخصهای سلامت از جمله کاربردهای رایج این معماری هستند. در چنین مسائلی، دادهها معمولاً بهصورت ویژگیمحور ارائه میشوند و فاقد ساختار مکانی یا زمانی پیچیده هستند؛ بنابراین شبکههای کاملاً متصل گزینهای مناسب محسوب میشوند.
علاوه بر این، این شبکهها در مسائل رگرسیون نیز کاربرد گستردهای دارند. پیشبینی قیمت مسکن، تخمین میزان مصرف انرژی و مدلسازی روابط اقتصادی از جمله مثالهایی هستند که در آنها شبکههای کاملاً متصل پیشخور میتوانند نگاشت دقیقی بین ورودی و خروجی ایجاد کنند. سادگی پیادهسازی و تفسیر نتایج باعث شده است که این شبکهها همچنان در بسیاری از پروژههای صنعتی و دانشگاهی مورد استفاده قرار گیرند.
مقایسه با سایر معماریهای شبکه عصبی:
در مقایسه با CNN و RNN، شبکههای کاملاً متصل برای دادههای جدولی مناسبتر هستند اما در پردازش دادههای مکانی و ترتیبی عملکرد ضعیفتری دارند.
شبکههای کاملاً متصل پیشخور در مقایسه با سایر معماریهای شبکه عصبی دارای مزایا و محدودیتهای خاص خود هستند. در مقایسه با شبکههای کانولوشنی (CNN)، شبکههای کاملاً متصل برای دادههایی که ساختار مکانی مشخصی ندارند، مانند دادههای جدولی و ویژگیمحور، مناسبتر هستند. CNNها با استفاده از فیلترهای کانولوشنی و اشتراک وزنها، در پردازش دادههای تصویری و مکانی عملکرد بسیار بهتری دارند و از نظر محاسباتی نیز بهینهتر عمل میکنند.
در مقایسه با شبکههای بازگشتی (RNN)، شبکههای کاملاً متصل فاقد حافظه زمانی هستند و نمیتوانند وابستگیهای ترتیبی بین دادهها را مدلسازی کنند. RNNها و بهویژه معماریهایی مانند LSTM و GRU برای دادههای سری زمانی و متنی طراحی شدهاند. با این حال، سادگی ساختار و پیادهسازی شبکههای کاملاً متصل باعث میشود که همچنان در بسیاری از مسائل پایه و آموزشی، گزینهای مناسب باشند.
بهطور کلی، انتخاب بین این معماریها به ماهیت داده و نوع مسئله بستگی دارد و شبکههای کاملاً متصل اغلب بهعنوان نقطه شروع طراحی مدلها مورد استفاده قرار میگیرند.
نتیجهگیری علمی و جمعبندی:
شبکههای کاملاً متصل پیشخور (Fully Connected Feedforward Neural Networks) بهعنوان یکی از بنیادیترین معماریهای شبکههای عصبی مصنوعی، نقش بسیار مهمی در شکلگیری و توسعه حوزه یادگیری ماشین و هوش مصنوعی ایفا کردهاند. این شبکهها با وجود ساختار نسبتاً ساده، توانایی بالایی در یادگیری روابط غیرخطی بین دادهها دارند و از این نظر، پلی میان مدلهای خطی کلاسیک و شبکههای عصبی عمیق محسوب میشوند.
در این مقاله تلاش شد تا این نوع شبکهها بهصورت جامع و مرحلهبهمرحله بررسی شوند. ابتدا مفهوم کلی شبکههای پیشخور کاملاً متصل و ضرورت استفاده از آنها برای مدلسازی مسائل پیچیده مطرح گردید. سپس ساختار شبکه، مدل ریاضی نورون مصنوعی، توابع فعالساز و فرآیند انتشار رو به جلو تشریح شد. در ادامه، الگوریتم آموزش و پسانتشار خطا بهعنوان هسته اصلی یادگیری شبکه مورد بررسی قرار گرفت و با ارائه یک مثال عددی کامل، نحوه پردازش دادهها در شبکه بهصورت عملی و شفاف نشان داده شد.
نتایج این بررسی نشان میدهد که شبکههای کاملاً متصل پیشخور، علیرغم ظهور معماریهای پیشرفتهتری مانند شبکههای کانولوشنی و بازگشتی، همچنان جایگاه مهمی در مسائل یادگیری ماشین دارند. این شبکهها بهویژه برای دادههای جدولی و مسائل فاقد ساختار مکانی یا زمانی پیچیده، انتخابی مناسب و کارآمد محسوب میشوند. همچنین، سادگی پیادهسازی و تحلیل آنها باعث شده است که بهعنوان نقطه شروع طراحی بسیاری از مدلهای یادگیری عمیق مورد استفاده قرار گیرند.
از سوی دیگر، بررسی چالشها و ملاحظات عملی نشان داد که استفاده مؤثر از این شبکهها نیازمند انتخاب آگاهانه ساختار، تنظیم دقیق پارامترهای آموزشی و پیشپردازش مناسب دادهها است. بیتوجهی به این عوامل میتواند منجر به مشکلاتی مانند بیشبرازش، همگرایی کند یا کاهش دقت مدل شود.
در مجموع، میتوان گفت که شبکههای کاملاً متصل پیشخور نهتنها از نظر تاریخی، بلکه از نظر آموزشی و کاربردی نیز اهمیت بالایی دارند. درک عمیق این معماری، زمینه لازم برای فهم بهتر شبکههای عصبی عمیق و معماریهای پیشرفتهتر را فراهم میکند و به پژوهشگران و دانشجویان کمک میکند تا با دیدی تحلیلیتر به طراحی و استفاده از مدلهای یادگیری ماشین بپردازند.
منابع:
Haykin, S. Neural Networks: A Comprehensive Foundation
Bishop, C. Pattern Recognition and Machine Learning
Goodfellow, I., Bengio, Y., & Courville, A. Deep Learning
Nielsen, M. Neural Networks and Deep Learning
Mitchell, T. Machine Learning
Schmidhuber, J. Deep Learning in Neural Networks: An Overview



دیدگاهتان را بنویسید