

شبکه پرسپترون چندلایه (MLP – Multilayer Perceptron)
شبکه پرسپترون چندلایه (MLP – Multilayer Perceptron)
این دوره به بررسی دقیق و عمیق مباحث شبکه پرسپترون چندلایه (MLP – Multilayer Perceptron) به صورت پایه ای می پردازد .جهت دسترسی به سایر دوره ها می توانید از لینک های زیر استفاده نمایید.
-
شبکه پرسپترون چندلایه (MLP – Multilayer Perceptron)
و برای مشاهده لیست تمام دوره ها به بخش مقالات مراجه نمایید.
فهرست مطالب:
- چکیده
- مقدمه
- بیان مسئله و اهمیت پژوهش
- تعریف شبکه پرسپترون چندلایه
- ساختار شبکه پرسپترون چندلایه
- لایه ورودی
- لایههای پنهان
- لایه خروجی
- مدل ریاضی نورون در شبکه MLP
- توابع فعالساز در شبکههای MLP
- الگوریتم آموزش پرسپترون چندلایه
- مثال عددی کامل با محاسبات گامبهگام
- مثال کدنویسی شبکه MLP (Python + NumPy)
- کاربردهای شبکه پرسپترون چندلایه
- مزایا و معایب
- چالشها و ملاحظات عملی
- نتیجهگیری
- منابع
چکیده:
شبکه پرسپترون چندلایه (Multilayer Perceptron – MLP) یکی از مهمترین و پرکاربردترین معماریهای شبکههای عصبی مصنوعی است که بهعنوان هسته اصلی بسیاری از الگوریتمهای یادگیری عمیق شناخته میشود. این شبکه با استفاده از چندین لایه پردازشی و توابع فعالساز غیرخطی، قادر به مدلسازی روابط پیچیده میان دادهها میباشد. در این مقاله، شبکه پرسپترون چندلایه بهصورت جامع بررسی شده است. ابتدا مفاهیم پایه، ساختار و مدل ریاضی نورون تشریح میشود، سپس الگوریتم آموزش پسانتشار خطا بهطور کامل توضیح داده شده و در ادامه یک مثال عددی گامبهگام به همراه پیادهسازی عملی با زبان Python ارائه میگردد. در پایان نیز کاربردها، مزایا، معایب و جمعبندی علمی این معماری بیان میشود.
مقدمه:
با رشد روزافزون دادهها و پیچیدهتر شدن مسائل تحلیلی، نیاز به مدلهایی که بتوانند الگوهای غیرخطی و پیچیده را شناسایی کنند بیش از پیش احساس میشود. پرسپترون تکلایه بهعنوان یکی از اولین مدلهای شبکه عصبی، تنها قادر به حل مسائل خطی بود و محدودیتهای زیادی داشت. این محدودیتها باعث شکلگیری شبکه پرسپترون چندلایه شد.
پرسپترون چندلایه با افزودن یک یا چند لایه پنهان به ساختار شبکه، امکان یادگیری روابط غیرخطی را فراهم میکند. این ویژگی، MLP را به یکی از قدرتمندترین و پرکاربردترین ابزارهای یادگیری ماشین تبدیل کرده است.
بیان مسئله و اهمیت پژوهش:
در بسیاری از مسائل واقعی یادگیری ماشین، دادهها بهگونهای هستند که نمیتوان آنها را با یک رابطه خطی ساده مدلسازی کرد. روابط بین متغیرها اغلب پیچیده، غیرخطی و وابسته به ترکیب چندین ویژگی هستند. مدلهای خطی مانند رگرسیون خطی یا پرسپترون تکلایه در چنین شرایطی توانایی لازم برای استخراج الگوهای پنهان در دادهها را ندارند و معمولاً با خطای بالا مواجه میشوند.
مسئله اصلی در این نوع کاربردها، یافتن مدلی است که بتواند بدون نیاز به تعریف صریح روابط ریاضی پیچیده، از خود دادهها الگوهای غیرخطی را یاد بگیرد. اینجاست که شبکههای عصبی پرسپترون چندلایه مطرح میشوند. با افزودن لایههای پنهان و استفاده از توابع فعالساز غیرخطی، این شبکهها قادرند مرزهای تصمیم پیچیدهتری ایجاد کنند و دادههایی را که بهصورت خطی قابل تفکیک نیستند، بهدرستی طبقهبندی نمایند.
اهمیت پژوهش:
اهمیت بررسی شبکه پرسپترون چندلایه تنها به توانایی بالای آن در حل مسائل غیرخطی محدود نمیشود. این شبکه بهعنوان پایه و زیربنای بسیاری از معماریهای پیشرفتهتر مانند شبکههای عصبی عمیق، شبکههای کانولوشنی و شبکههای بازگشتی شناخته میشود. به عبارت دیگر، درک سازوکار MLP به پژوهشگران و دانشجویان کمک میکند تا منطق عملکرد شبکههای عصبی پیچیدهتر را بهتر درک کنند.
بنابراین، مسئله اصلی این پژوهش بررسی ساختار، مدل ریاضی و الگوریتم آموزش شبکه پرسپترون چندلایه و تحلیل تواناییها و محدودیتهای آن در یادگیری الگوهای پیچیده است. چنین بررسیای میتواند دید روشنی نسبت به کاربرد عملی این شبکه در مسائل واقعی فراهم کند.
تعریف شبکه پرسپترون چندلایه:
پرسپترون چندلایه نوعی شبکه عصبی پیشخور است که شامل حداقل یک لایه پنهان بین لایه ورودی و لایه خروجی میباشد. در این شبکه، اطلاعات تنها در یک جهت، از ورودی به خروجی، جریان پیدا میکنند و هیچ حلقه بازخوردی وجود ندارد.
وجود لایههای پنهان باعث میشود شبکه بتواند مرزهای تصمیمگیری غیرخطی ایجاد کند و مسائل پیچیدهتری را حل نماید.
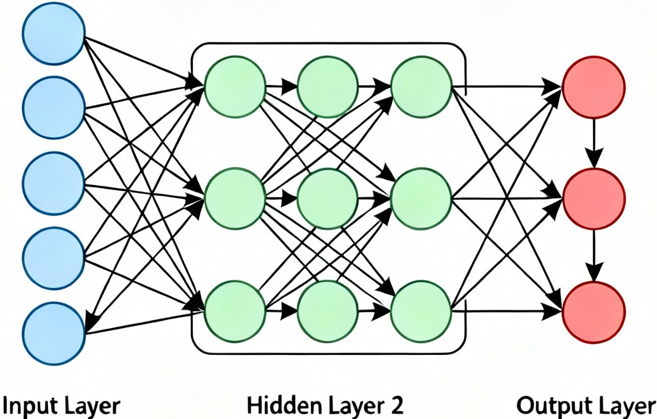
ساختار شبکه پرسپترون چندلایه:
شبکه MLP معمولاً از سه بخش اصلی تشکیل شده است:
لایه ورودی
این لایه دادههای خام را دریافت میکند و تعداد نورونهای آن برابر با تعداد ویژگیهای داده ورودی است.
لایههای پنهان
لایههای پنهان عملیات پردازش اصلی را انجام میدهند. هر نورون در این لایهها شامل وزن، بایاس و تابع فعالساز است. تعداد این لایهها و نورونها به پیچیدگی مسئله بستگی دارد.
لایه خروجی
این لایه خروجی نهایی شبکه را تولید میکند. نوع تابع فعالساز در این لایه به نوع مسئله (رگرسیون یا طبقهبندی) وابسته است.
مدل ریاضی نورون در شبکه (MLP – Multilayer Perceptron):
وزنها اهمیت ورودیها را تعیین میکنند و بایاس آستانه تصمیم را جابهجا میکند. تابع فعالساز غیرخطی، توان یادگیری روابط پیچیده را فراهم میسازد.
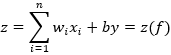
توابع فعالساز در شبکههای (MLP – Multilayer Perceptron):
توابع فعالساز نقش کلیدی در ایجاد غیرخطی بودن شبکه دارند. از مهمترین آنها میتوان به موارد زیر اشاره کرد:
- Sigmoid
- Tanh
- ReLU
- Leaky ReLU
- Softmax
انتخاب تابع فعالساز مناسب تأثیر مستقیمی بر سرعت همگرایی و دقت مدل دارد.
الگوریتم آموزش پرسپترون چندلایه:
آموزش شبکه MLP معمولاً با الگوریتم پسانتشار خطا انجام میشود. این الگوریتم شامل انتشار رو به جلو، محاسبه خطا، محاسبه گرادیانها و بهروزرسانی وزنها با استفاده از روشهایی مانند گرادیان نزولی است.
آموزش شبکه پرسپترون چندلایه معمولاً با استفاده از الگوریتم پسانتشار خطا (Backpropagation) انجام میشود. این الگوریتم یکی از مهمترین دستاوردهای حوزه شبکههای عصبی است و امکان آموزش شبکههای دارای لایههای پنهان را فراهم میکند.
الگوریتم پسانتشار خطا مهمترین روش آموزش شبکههای پرسپترون چندلایه است و امکان تنظیم وزنها در شبکههای دارای لایههای پنهان را فراهم میکند. این الگوریتم بر پایه گرادیان نزولی و قانون زنجیرهای مشتق عمل میکند و بهصورت تکرارشونده اجرا میشود.
مرحله اول: انتشار رو به جلو (Forward Propagation)
در این مرحله، دادههای ورودی به شبکه داده میشوند و خروجی هر لایه بهترتیب محاسبه میگردد. برای هر نورون، ابتدا مجموع وزندار ورودیها بهعلاوه بایاس محاسبه شده و سپس تابع فعالساز روی آن اعمال میشود. این فرآیند تا رسیدن به لایه خروجی ادامه مییابد و خروجی نهایی شبکه به دست میآید.
مرحله دوم: محاسبه خطا (Error Calculation)
پس از محاسبه خروجی شبکه، مقدار خروجی پیشبینیشده با مقدار واقعی مقایسه میشود. اختلاف بین این دو مقدار بهعنوان خطای شبکه در نظر گرفته میشود. این خطا معمولاً با استفاده از یک تابع هزینه مانند خطای میانگین مربعات یا آنتروپی متقاطع محاسبه میگردد.
مرحله سوم: انتشار معکوس خطا (Backward Propagation)
در این مرحله، خطای محاسبهشده از لایه خروجی به سمت لایههای پنهان منتقل میشود. با استفاده از قانون زنجیرهای مشتق، گرادیان خطا نسبت به وزنها و بایاسهای هر لایه محاسبه میگردد. این گرادیانها نشان میدهند که هر پارامتر چه میزان در ایجاد خطا نقش داشته است.
مرحله چهارم: بهروزرسانی وزنها و بایاسها
پس از محاسبه گرادیانها، وزنها و بایاسها در جهت کاهش خطا بهروزرسانی میشوند. این بهروزرسانی معمولاً با استفاده از نرخ یادگیری انجام میشود. انتخاب نرخ یادگیری مناسب نقش مهمی در پایداری و سرعت همگرایی الگوریتم دارد.
مرحله پنجم: تکرار فرآیند آموزش
مراحل فوق برای تمام نمونههای آموزشی و در چندین دوره آموزشی (Epoch) تکرار میشود تا زمانی که خطای شبکه به مقدار قابل قبولی برسد یا معیار توقف مشخصشده برآورده شود.
بهطور خلاصه، الگوریتم پسانتشار خطا این امکان را فراهم میکند که شبکه پرسپترون چندلایه بهصورت تدریجی و مبتنی بر خطا، وزنهای خود را تنظیم کرده و بهمرور زمان عملکرد بهتری در پیشبینی دادهها داشته باشد.
مثال عددی کامل با محاسبات گامبهگام:
فرض کنید هدف پیشبینی قبولی دانشجو بر اساس ساعات مطالعه و نمره میانترم است.
ورودیها:
- x1 = 4
- x2 = 15
ساختار شبکه:
- 2 نورون ورودی
- 2 نورون پنهان با ReLU
- 1 نورون خروجی با Sigmoid
وزنها و بایاسها:
- w11 = 0.2 ، w12 = 0.4 ، b1 = 0.1
- w21 = 0.3 ، w22 = 0.5 ، b2 = 0.1
- v1 = 0.6 ، v2 = 0.7 ، b3 = 0.2
محاسبات لایه پنهان:
z1 = (0.2×4) + (0.4×15) + 0.1 = 6.9
z2 = (0.3×4) + (0.5×15) + 0.1 = 8.8
a1 = ReLU(6.9) = 6.9
a2 = ReLU(8.8) = 8.8
خروجی شبکه:
z3 = (0.6×6.9) + (0.7×8.8) + 0.2 = 10.5
y = Sigmoid(10.5) ≈ 0.99997
مثال کدنویسی شبکه MLP (Python + NumPy):
import numpy as np
def relu(x):
return np.maximum(0, x)
def sigmoid(x):
return 1 / (1 + np.exp(-x))
X = np.array([4, 15])
W_hidden = np.array([[0.2, 0.4],
[0.3, 0.5]])
b_hidden = np.array([0.1, 0.1])
W_output = np.array([0.6, 0.7])
b_output = 0.2
z_hidden = np.dot(W_hidden, X) + b_hidden
a_hidden = relu(z_hidden)
z_output = np.dot(W_output, a_hidden) + b_output
y = sigmoid(z_output)
print(y)
مثلا اگر:
z_output = 10.5
(10.5)y = sigmoid
نتیجه می شود:
0.99997247
این مقدار نشان میدهد که شبکه با اطمینان بسیار بالا کلاس مثبت (مثلاً قبولی دانشجو) را پیشبینی کرده است.
کاربردهای شبکه پرسپترون چندلایه(MLP – Multilayer Perceptron):
شبکههای MLP در حوزههای مختلفی مانند تشخیص الگو، پیشبینی، تحلیل دادههای مالی، تشخیص پزشکی، پردازش سیگنال و سیستمهای توصیهگر کاربرد گستردهای دارند.
مزایا و معایب:
مزایا
- توانایی مدلسازی روابط غیرخطی
- انعطافپذیری بالا
- کاربرد گسترده در مسائل واقعی
معایب
- نیاز به داده آموزشی زیاد
- حساسیت به تنظیم پارامترها
- هزینه محاسباتی بالا در شبکههای بزرگ
چالشها و ملاحظات عملی:
با وجود توانایی بالای شبکههای پرسپترون چندلایه در یادگیری روابط غیرخطی و پیچیده، استفاده عملی از این شبکهها با چالشها و محدودیتهایی همراه است که در صورت بیتوجهی میتواند منجر به کاهش عملکرد مدل شود. یکی از مهمترین این چالشها، پدیده بیشبرازش (Overfitting) است. بیشبرازش زمانی رخ میدهد که شبکه بهجای یادگیری الگوی کلی دادهها، جزئیات و نویز موجود در دادههای آموزشی را حفظ میکند. در چنین شرایطی، اگرچه دقت مدل روی دادههای آموزشی بالا است، اما عملکرد آن روی دادههای جدید و دیدهنشده بهطور قابل توجهی کاهش مییابد.
یکی از عوامل اصلی ایجاد بیشبرازش، انتخاب ساختار نامناسب شبکه است. افزایش بیش از حد تعداد لایهها یا نورونها، ظرفیت مدل را فراتر از نیاز مسئله افزایش میدهد و خطر یادگیری نویز دادهها را بالا میبرد. از سوی دیگر، ساختار بیش از حد ساده نیز میتواند منجر به کمبرازش (Underfitting) شود که در آن شبکه قادر به یادگیری الگوهای موجود در داده نیست. بنابراین، تعیین تعداد مناسب لایههای پنهان و نورونها یک مسئله مهم و اغلب تجربی است که نیازمند آزمون و خطا و ارزیابی دقیق مدل میباشد.
ملاحظات عملی:
از دیگر ملاحظات عملی مهم میتوان به انتخاب نرخ یادگیری اشاره کرد. نرخ یادگیری مقدار تغییر وزنها در هر مرحله آموزش را تعیین میکند. اگر این مقدار بیش از حد بزرگ باشد، فرآیند آموزش ناپایدار شده و شبکه ممکن است هرگز به همگرایی نرسد. در مقابل، نرخ یادگیری بسیار کوچک باعث کند شدن آموزش و افزایش زمان محاسباتی میشود. به همین دلیل، استفاده از روشهای بهینهسازی تطبیقی مانند Adam یا RMSprop در بسیاری از کاربردهای عملی توصیه میشود.
مقیاس دادههای ورودی نیز نقش مهمی در عملکرد شبکههای MLP ایفا میکند. دادههایی که دارای مقیاسهای متفاوت هستند میتوانند باعث کندی همگرایی یا ناپایداری آموزش شوند. به همین دلیل، نرمالسازی یا استانداردسازی دادهها یکی از مراحل ضروری پیشپردازش در استفاده عملی از شبکههای پرسپترون چندلایه محسوب میشود.
مقایسه شبکه پرسپترون چندلایه با سایر معماریها:
شبکه پرسپترون چندلایه در مقایسه با سایر معماریهای شبکه عصبی، جایگاه ویژهای دارد. در مقایسه با پرسپترون تکلایه، MLP قادر به حل مسائل غیرخطی و پیچیده است و محدودیتهای خطی بودن را برطرف میکند. این ویژگی، MLP را به یکی از پرکاربردترین مدلهای پایه در یادگیری ماشین تبدیل کرده است.
در مقایسه با شبکههای کانولوشنی (CNN)، شبکههای MLP ساختار سادهتری دارند و برای دادههای جدولی و ویژگیمحور مناسبتر هستند، در حالی که CNNها در پردازش دادههای تصویری و مکانی عملکرد بهتری دارند. همچنین در مقایسه با شبکههای بازگشتی (RNN)، شبکههای MLP فاقد حافظه زمانی هستند و برای دادههای ترتیبی مناسب نیستند، اما از نظر سادگی پیادهسازی و سرعت آموزش مزیت دارند.
نتیجهگیری:
شبکه عصبی پرسپترون چندلایه یکی از بنیادیترین و در عین حال قدرتمندترین معماریهای شبکههای عصبی مصنوعی به شمار میرود. این شبکه با افزودن لایههای پنهان و استفاده از توابع فعالساز غیرخطی، محدودیتهای مدلهای خطی را برطرف کرده و امکان یادگیری روابط پیچیده بین دادهها را فراهم میکند. به همین دلیل، MLP بهعنوان پایه بسیاری از شبکههای عصبی عمیق و الگوریتمهای پیشرفته یادگیری ماشین شناخته میشود.
در این مقاله، تلاش شد تا شبکه پرسپترون چندلایه بهصورت گامبهگام و با زبانی روان بررسی شود. ابتدا ساختار و مدل ریاضی نورون معرفی شد، سپس الگوریتم آموزش و فرآیند پسانتشار خطا توضیح داده شد و در ادامه، مثال عددی و پیادهسازی عملی ارائه گردید. بررسی چالشها و ملاحظات عملی نشان داد که طراحی و آموزش یک شبکه MLP موفق نیازمند انتخاب آگاهانه ساختار شبکه، تنظیم دقیق پارامترهای آموزشی و پیشپردازش مناسب دادهها است.
در نهایت میتوان گفت که درک صحیح پرسپترون چندلایه نهتنها برای حل مسائل عملی، بلکه برای فهم معماریهای پیشرفتهتر مانند شبکههای عمیق، شبکههای کانولوشنی و بازگشتی ضروری است. از این رو، MLP همچنان یکی از مهمترین و کاربردیترین مدلها در آموزش و پژوهش حوزه یادگیری ماشین و هوش مصنوعی محسوب میشود.
منابع:
Haykin, S. (1999). Neural Networks: A Comprehensive Foundation
Goodfellow, I., Bengio, Y., & Courville, A. (2016). Deep Learning
Bishop, C. M. (2006). Pattern Recognition and Machine Learning

