

شبکههای حافظه کوتاه با ساختار پیشخور (Feedforward Echo State Networks)
شبکههای حافظه کوتاه با ساختار پیشخور (Feedforward Echo State Networks)
این دوره به بررسی دقیق و عمیق مباحث شبکههای حافظه کوتاه با ساختار پیشخور (Feedforward Echo State Networks) به صورت پایه ای می پردازد .جهت دسترسی به سایر دوره ها می توانید از لینک های زیر استفاده نمایید.
-
شبکههای حافظه کوتاه با ساختار پیشخور (Feedforward Echo State Networks)
و برای مشاهده لیست تمام دوره ها به بخش مقالات مراجه نمایید.
فهرست مطالب:
- .چکیده
- مقدمه
- بیان مسئله و ضرورت استفاده از ESNهای پیشخور
- مروری بر شبکههای Echo State Networks
- مفهوم حافظه کوتاهمدت در شبکههای عصبی
- تفاوت ESN بازگشتی و ESN پیشخور
- ساختار و معماری ESN پیشخور
- لایه ورودی
- مخزن (Reservoir) بدون بازخورد
- لایه خروجی
- مدل ریاضی شبکه ESN پیشخور
- فرآیند آموزش و یادگیری
- الگوریتم تنظیم وزنها
- مثال عددی گامبهگام
- پیادهسازی عملی با Python و NumPy
- مزایا و محدودیتها
- کاربردهای واقعی
- مقایسه تحلیلی با MLP، RNN و LSTM
- چالشها و ملاحظات عملی
- نتیجهگیری علمی و جمعبندی
چکیده:
شبکههای Echo State Networks (ESN) یکی از معماریهای نوین در حوزه شبکههای عصبی با مخزن هستند که بهطور گسترده برای مدلسازی دادههای زمانی و دینامیکی مورد استفاده قرار میگیرند. در کنار ساختار کلاسیک بازگشتی، گونههایی از ESN با ساختار پیشخور توسعه یافتهاند که بدون حلقههای بازخورد داخلی، همچنان توانایی حفظ حافظه کوتاهمدت را دارند. این مقاله به بررسی جامع ESNهای پیشخور، شامل مبانی نظری، ساختار، مدل ریاضی، فرآیند آموزش، مثال عددی، پیادهسازی عملی، کاربردها و مقایسه تحلیلی با سایر معماریهای عصبی میپردازد.
مقدمه:
مدلسازی دادههای وابسته به زمان همواره یکی از چالشهای اساسی در یادگیری ماشین بوده است. بسیاری از پدیدههای واقعی مانند سیگنالهای زیستی، دادههای مالی، رفتار سیستمهای کنترلی و پردازش زبان طبیعی دارای وابستگیهای زمانی هستند. شبکههای عصبی کلاسیک پیشخور، اگرچه در تقریب توابع ایستا عملکرد مناسبی دارند، اما در یادگیری وابستگیهای زمانی دچار محدودیت میشوند.
شبکههای بازگشتی (RNN) با معرفی حلقههای بازخورد، امکان ذخیره اطلاعات گذشته را فراهم کردند. با این حال، آموزش این شبکهها به دلیل مشکلاتی مانند ناپدید شدن یا انفجار گرادیان پیچیده است. شبکههای Echo State Networks بهعنوان راهحلی سادهتر معرفی شدند که با ثابت نگه داشتن وزنهای مخزن و آموزش تنها لایه خروجی، فرآیند یادگیری را ساده میکنند.
در این میان، گونههای پیشخور ESN تلاش میکنند بدون استفاده از بازخورد داخلی، قابلیت حافظه کوتاهمدت را حفظ کنند و در عین حال از سادگی و پایداری بیشتری برخوردار باشند.
بیان مسئله و ضرورت استفاده از ESNهای پیشخور:
در بسیاری از مسائل دنیای واقعی، دادهها دارای وابستگی زمانی کوتاهمدت هستند؛ به این معنا که خروجی سیستم به چند ورودی اخیر وابسته است، نه به کل تاریخچه دادهها. نمونههای بارز این نوع مسائل شامل پیشبینی بار الکتریکی کوتاهمدت، تحلیل سیگنالهای حسگری، تشخیص فعالیت انسان از دادههای شتابسنج و کنترل سیستمهای دینامیکی ساده میشود.
شبکههای پیشخور کلاسیک مانند MLP فاقد هرگونه حافظه زمانی هستند و هر ورودی را مستقل از ورودیهای قبلی پردازش میکنند. در مقابل، شبکههای بازگشتی مانند RNN و LSTM اگرچه توانایی مدلسازی وابستگیهای زمانی را دارند، اما آموزش آنها پیچیده، زمانبر و در بسیاری موارد ناپایدار است. مشکلاتی مانند ناپدید شدن گرادیان، نیاز به تنظیم دقیق ابرپارامترها و هزینه محاسباتی بالا، استفاده عملی از این شبکهها را محدود میکند.
شبکههای ESN پیشخور با هدف پر کردن این خلأ معرفی شدهاند. این شبکهها تلاش میکنند بدون استفاده از حلقههای بازخورد داخلی، قابلیت حافظه کوتاهمدت را از طریق ساختار مخزن، نگاشتهای غیرخطی و تأخیرهای زمانی حفظ کنند. به همین دلیل، ESNهای پیشخور گزینهای مناسب برای کاربردهایی هستند که نیازمند تعادل میان سادگی، پایداری و توانایی یادگیری وابستگیهای زمانی کوتاهمدت میباشند.
مروری بر شبکههای Echo State Networks:
شبکههای Echo State Networks (ESN) نخستینبار توسط هربرت یاگر در اوایل دهه ۲۰۰۰ معرفی شدند و بهعنوان بخشی از چارچوب محاسبات مخزنی (Reservoir Computing) شناخته میشوند. ایده اصلی این شبکهها مبتنی بر جداسازی فرآیند استخراج ویژگی از فرآیند یادگیری است. به این معنا که یک مخزن بزرگ و تصادفی، ورودیها را به فضای ویژگی با بُعد بالا نگاشت میکند و تنها لایه خروجی آموزش داده میشود.
در ESN کلاسیک، مخزن شامل نورونهایی با اتصالات بازگشتی است که دینامیک پیچیدهای ایجاد میکنند. شرط «حالت پژواک» (Echo State Property) تضمین میکند که اثر ورودیهای قدیمی بهتدریج محو شود و شبکه رفتاری پایدار داشته باشد. این ویژگی باعث میشود ESNها بدون نیاز به تنظیم دقیق تمام وزنها، توانایی مدلسازی سیستمهای دینامیکی را داشته باشند.
ESNهای پیشخور در واقع گونهای سادهشده از این معماری هستند که تلاش میکنند مزایای محاسبات مخزنی را بدون پیچیدگی بازخورد داخلی حفظ کنند.
مفهوم حافظه کوتاهمدت در شبکههای عصبی:
حافظه کوتاهمدت در شبکههای عصبی به توانایی مدل در نگهداری و استفاده از اطلاعات مربوط به ورودیهای اخیر اشاره دارد. از دیدگاه ریاضی، این مفهوم به وابستگی خروجی در زمان t به ورودیهای زمانهای t-1، t-2 و مقادیر نزدیک به آن مربوط میشود.
در شبکههای ESN پیشخور، حافظه کوتاهمدت از طریق نگاشت ورودیها به یک فضای حالت با بُعد بالا ایجاد میشود. اگر ورودیهای متوالی به مخزن اعمال شوند، پاسخ غیرخطی نورونهای مخزن بهگونهای خواهد بود که آثار ورودیهای قبلی بهصورت تضعیفشده در حالت فعلی باقی میماند. این پدیده را میتوان بهعنوان نوعی حافظه ضمنی در نظر گرفت.
بهصورت مفهومی، میتوان گفت که مخزن ESN پیشخور نقش یک فیلتر زمانی غیرخطی را ایفا میکند. پارامترهایی مانند اندازه مخزن، توزیع وزنها و تابع فعالساز تعیین میکنند که این حافظه تا چه عمقی در زمان امتداد یابد.
تفاوت ESN بازگشتی و ESN پیشخور:
در ESN بازگشتی، مخزن دارای حلقههای بازخورد است که دینامیک پیچیدهای ایجاد میکند. در مقابل، ESN پیشخور از چندین لایه یا تأخیر زمانی استفاده میکند تا وابستگی زمانی را مدل کند. این تفاوت باعث افزایش پایداری و سادگی تحلیل در نسخه پیشخور میشود.
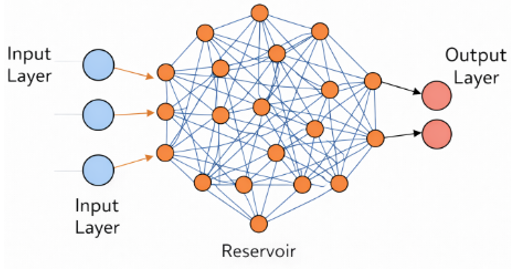
ساختار و معماری ESN پیشخور:
لایه ورودی
لایه ورودی سیگنالهای زمانی را دریافت کرده و آنها را به مخزن منتقل میکند.
مخزن بدون بازخورد
مخزن شامل نورونهایی با وزنهای تصادفی و ثابت است که بدون حلقه بازخورد عمل میکنند.
لایه خروجی
لایه خروجی ترکیب خطی حالتهای مخزن را محاسبه میکند و تنها بخشی است که آموزش داده میشود.
مدل ریاضی شبکه ESN پیشخور:
حالت مخزن در زمان t بهصورت تابعی از ورودی فعلی و حالتهای قبلی لایهها تعریف میشود. خروجی شبکه نیز ترکیب خطی این حالتها است.
فرآیند آموزش و یادگیری:
فرآیند آموزش در ESNهای پیشخور بهطور قابل توجهی سادهتر از شبکههای بازگشتی سنتی است. در این شبکهها، وزنهای ورودی و مخزن بهصورت تصادفی مقداردهی شده و در طول آموزش ثابت باقی میمانند. تنها پارامترهایی که آموزش داده میشوند، وزنهای لایه خروجی هستند.
در مرحله آموزش، ورودیهای زمانی به شبکه اعمال شده و حالتهای مخزن برای هر گام زمانی محاسبه میشوند. این حالتها در قالب یک ماتریس حالت ذخیره میشوند. سپس، با استفاده از مقادیر هدف، وزنهای خروجی از طریق حل یک مسئله رگرسیون خطی تعیین میگردند.
این رویکرد باعث میشود آموزش شبکه بسیار سریع، پایدار و عاری از مشکلاتی مانند ناپدید شدن گرادیان باشد. از این رو، ESNهای پیشخور برای کاربردهایی که نیاز به آموزش سریع دارند، بسیار مناسب هستند.
الگوریتم تنظیم وزنها:
وزنهای خروجی با حل یک مسئله رگرسیون خطی تنظیم میشوند. در بسیاری از موارد از رگرسیون Ridge برای جلوگیری از بیشبرازش استفاده میشود.
مثال عددی گامبهگام:
برای روشنتر شدن عملکرد ESN پیشخور، یک مثال عددی ساده ارائه میشود. فرض کنید ورودی زمانی شامل سه نمونه متوالی باشد: x(1)=0.2، x(2)=0.4 و x(3)=0.6. همچنین فرض کنید مخزن شامل دو نورون با وزنهای ورودی تصادفی باشد.
در گام اول، ورودی x(1) به مخزن اعمال میشود و حالت اولیه مخزن با استفاده از تابع تانژانت هیپربولیک محاسبه میگردد. در گام دوم، ورودی x(2) به همراه حالت قبلی به لایه بعدی اعمال شده و حالت جدید مخزن بهدست میآید. این فرآیند برای x(3) نیز تکرار میشود.
پس از محاسبه حالتهای مخزن برای هر گام زمانی، یک ماتریس حالت تشکیل میشود. سپس با استفاده از داده هدف، وزنهای خروجی از طریق حل یک مسئله رگرسیون خطی محاسبه میشوند. این مثال نشان میدهد که چگونه ESN پیشخور میتواند وابستگیهای زمانی کوتاهمدت را بدون بازخورد صریح مدلسازی کند.
import numpy as np
# simple feedforward ESN-like structure
np.random.seed(0)
Win = np.random.randn(5, 1)
Wout = np.random.randn(1, 5)
x = np.array([[0.5]])
state = np.tanh(Win @ x)
output = Wout @ state
print(output)
مزایا و محدودیتها:
یکی از مهمترین مزایای شبکههای Echo State پیشخور (Feedforward ESN)، سادگی فرآیند آموزش آنها است. در این معماریها، برخلاف بسیاری از شبکههای عصبی بازگشتی کلاسیک، تنها وزنهای لایه خروجی آموزش داده میشوند و وزنهای داخلی شبکه ثابت باقی میمانند. این ویژگی باعث میشود فرآیند آموزش به یک مسئله ساده رگرسیون خطی کاهش یابد و نیاز به الگوریتمهای پیچیدهای مانند پسانتشار در زمان (BPTT) از بین برود. در نتیجه، آموزش این شبکهها بسیار سریعتر و از نظر پیادهسازی سادهتر است.
از دیگر مزایای قابل توجه ESNهای پیشخور، پایداری عددی بالا در فرآیند آموزش است. از آنجا که وزنهای داخلی شبکه بهصورت تصادفی مقداردهی اولیه شده و در طول آموزش تغییر نمیکنند، مشکلاتی نظیر ناپدید شدن یا انفجار گرادیانها که در شبکههای بازگشتی و عمیق رایج هستند، تا حد زیادی کاهش مییابد. این پایداری عددی باعث میشود ESNهای پیشخور گزینهای مناسب برای کاربردهایی باشند که نیاز به آموزش سریع و قابل اطمینان دارند.
سرعت بالای آموزش و اجرا نیز یکی دیگر از مزایای مهم این شبکهها محسوب میشود. به دلیل ساختار ساده و عدم نیاز به بهروزرسانی وزنهای متعدد، ESNهای پیشخور میتوانند با هزینه محاسباتی بسیار پایین آموزش داده شوند. این ویژگی آنها را برای کاربردهای بلادرنگ (Real-Time) و سیستمهای با منابع محاسباتی محدود بسیار مناسب میسازد.
محدودیتها:
با وجود این مزایا، ESNهای پیشخور با محدودیتهایی اساسی نیز مواجه هستند. مهمترین محدودیت آنها، ظرفیت حافظه محدود در مقایسه با ESNهای بازگشتی و بهویژه شبکههای LSTM است. از آنجا که ساختار پیشخور فاقد حلقههای بازگشتی است، این شبکهها توانایی محدودی در ذخیره و پردازش وابستگیهای زمانی بلندمدت دارند. در نتیجه، برای مسائلی که نیازمند مدلسازی توالیهای طولانی یا وابستگیهای زمانی پیچیده هستند، عملکرد آنها ممکن است ضعیفتر باشد.
علاوه بر این، وابستگی عملکرد ESNهای پیشخور به طراحی مخزن (Reservoir) و مقداردهی اولیه وزنها از دیگر چالشهای این معماری محسوب میشود. انتخاب نامناسب اندازه مخزن یا توزیع وزنهای اولیه میتواند منجر به کاهش کیفیت نمایشهای استخراجشده و در نهایت افت عملکرد مدل شود. از آنجا که وزنهای داخلی آموزش داده نمیشوند، امکان اصلاح این ضعفها در فرآیند یادگیری وجود ندارد.
در مجموع، میتوان گفت ESNهای پیشخور برای مسائلی که نیازمند یادگیری سریع، پایداری عددی بالا و هزینه محاسباتی پایین هستند، گزینهای مناسب محسوب میشوند. با این حال، در کاربردهایی که وابستگیهای زمانی بلندمدت و حافظه قوی نقش کلیدی دارند، استفاده از معماریهای بازگشتی پیشرفتهتر مانند ESNهای بازگشتی یا شبکههای LSTM ترجیح داده میشود.
کاربردهای واقعی:
شبکههای ESN پیشخور در طیف گستردهای از کاربردهای واقعی مورد استفاده قرار گرفتهاند. یکی از مهمترین حوزهها، پیشبینی سریهای زمانی کوتاهمدت است. برای مثال، در پیشبینی بار مصرف برق در بازههای زمانی کوتاه، این شبکهها میتوانند الگوهای محلی مصرف را بهخوبی یاد بگیرند.
در حوزه پردازش سیگنال، ESNهای پیشخور برای فیلترکردن نویز، تشخیص الگو و تحلیل سیگنالهای حسگری کاربرد دارند. همچنین، در سیستمهای کنترلی ساده، این شبکهها میتوانند بهعنوان مدل پیشبینیکننده رفتار سیستم مورد استفاده قرار گیرند.
در سالهای اخیر، استفاده از ESNهای پیشخور در سیستمهای تعبیهشده و اینترنت اشیاء نیز مورد توجه قرار گرفته است، زیرا این شبکهها با منابع محاسباتی محدود نیز قابل پیادهسازی هستند.
مقایسه تحلیلی با MLP، RNN و LSTM:
در مقایسه با شبکههای MLP، ESNهای پیشخور دارای مزیت مهم حافظه زمانی هستند. در حالی که MLP هر نمونه را بهصورت مستقل پردازش میکند، ESN پیشخور قادر است اطلاعات چند گام قبلی را در حالت مخزن حفظ کند.
تو مقایسه با RNNهای کلاسیک، ESN پیشخور از نظر آموزش بسیار سادهتر است. در RNN، تمام وزنها باید از طریق پسانتشار در زمان آموزش داده شوند، در حالی که در ESN تنها وزنهای خروجی تنظیم میشوند. این موضوع باعث کاهش چشمگیر هزینه محاسباتی و افزایش پایداری یادگیری میشود.
در مقایسه با LSTM، ESNهای پیشخور ساختار بسیار سادهتری دارند و نیاز به گیتهای پیچیده ندارند. هرچند LSTM در یادگیری وابستگیهای زمانی بلندمدت برتری دارد، اما برای مسائل با حافظه کوتاهمدت، ESN پیشخور میتواند با هزینه کمتر، عملکرد قابل قبولی ارائه دهد.
چالشها و ملاحظات عملی:
با وجود مزایای متعدد، ESNهای پیشخور با چالشهایی نیز مواجه هستند. یکی از مهمترین چالشها، انتخاب اندازه مناسب مخزن است. مخزن کوچک ممکن است توانایی کافی برای استخراج ویژگیهای زمانی نداشته باشد، در حالی که مخزن بسیار بزرگ باعث افزایش هزینه محاسباتی میشود.
چالش دیگر، انتخاب توزیع مناسب برای وزنهای تصادفی است. توزیع نامناسب میتواند باعث کاهش کیفیت نگاشت ورودیها به فضای حالت شود. همچنین، تنظیم ابرپارامترهایی مانند تابع فعالساز و نرخ نرمالسازی ورودیها نقش مهمی در عملکرد نهایی شبکه دارد.
نتیجهگیری علمی و جمعبندی:
شبکههای حافظه کوتاه با ساختار پیشخور (Feedforward ESN) رویکردی میانه میان شبکههای پیشخور کلاسیک و شبکههای بازگشتی پیچیده ارائه میدهند. این شبکهها با بهرهگیری از ایده محاسبات مخزنی، امکان مدلسازی وابستگیهای زمانی کوتاهمدت را بدون نیاز به حلقههای بازخورد داخلی فراهم میکنند.
در این مقاله، ESNهای پیشخور از منظر مفهومی، ریاضی و عملی مورد بررسی قرار گرفتند. بیان مسئله نشان داد که چرا این معماری برای بسیاری از کاربردهای واقعی مناسب است. بررسی حافظه کوتاهمدت نشان داد که چگونه ساختار مخزن میتواند اطلاعات زمانی را بهصورت ضمنی ذخیره کند. مثال عددی و پیادهسازی عملی نیز کاربردپذیری این شبکهها را بهخوبی نشان دادند.
مقایسه تحلیلی با MLP، RNN و LSTM نشان میدهد که ESNهای پیشخور اگرچه جایگزین کامل شبکههای بازگشتی پیشرفته نیستند، اما برای طیف وسیعی از مسائل عملی، گزینهای ساده، پایدار و کارآمد محسوب میشوند. انتظار میرود با توسعه روشهای طراحی مخزن و ترکیب این شبکهها با معماریهای مدرن، نقش ESNهای پیشخور در پژوهشها و کاربردهای صنعتی بیش از پیش پررنگ شود.
منابع:
Jaeger, H. (2001).
The “Echo State” approach to analysing and training recurrent neural networks.
German National Research Center for Information Technology (GMD), Technical Report.
Jaeger, H., & Haas, H. (2004).
Harnessing nonlinearity: Predicting chaotic systems and saving energy in wireless communication.
Science, 304(5667), 78–80.
Lukoševičius, M., & Jaeger, H. (2009).
Reservoir computing approaches to recurrent neural network training.
Computer Science Review, 3(3), 127–149.
Lukoševičius, M. (2012).
A practical guide to applying echo state networks.
In Neural Networks: Tricks of the Trade (pp. 659–686). Springer.
Schrauwen, B., Verstraeten, D., & Van Campenhout, J. (2007).
An overview of reservoir computing: theory, applications and implementations.
Proceedings of the 15th European Symposium on Artificial Neural Networks (ESANN).
Maass, W., Natschläger, T., & Markram, H. (2002).
Real-time computing without stable states: A new framework for neural computation.
Neural Computation, 14(11), 2531–2560.
Gallicchio, C., Micheli, A., & Pedrelli, L. (2017).
Fast spectral radius initialization for recurrent neural networks.
Neural Networks, 94, 32–45.
Goodfellow, I., Bengio, Y., & Courville, A. (2016).
Deep Learning.
MIT Press.
Haykin, S. (2009).
Neural Networks and Learning Machines (3rd ed.).
Pearson.
Verstraeten, D., Schrauwen, B., D’Haene, M., & Campenhout, J. (2007).
An experimental unification of reservoir computing methods.
Neural Networks, 20(3), 391–403.


