

آموزش هوش مصنوعی
دوره کامل آموزش هوش مصنوعی بر مبنای دوره CS5 دانشگاه هاروارد به عنوان معتبرترین و جامع ترین دوره آموزش مقدماتی و مفهومی هوش مصنوعی شناخته می شود.
این دوره به بررسی دقیق و عمیق مباحث هوش مصنوعی به صورت پایه ای می پردازد و شامل 7 بخش میباشد.دوره جاری آخرین دوره از 7 دوره می باشد .جهت دسترسی به سایر دوره ها می توانید از لینک های زیر استفاده نمایید.
-
آموزش هوش مصنوعی بخش آخر CS506
و برای مشاهده لیست تمام دوره ها به بخش مقالات مراجه نمایید.
CS50’s Introduction to Artificial Intelligence with Python
Danix Ai
آموزش هوش مصنوعی بخش آخر CS506
فهرست:
مقدمهای بر پردازش زبان طبیعی
- انواع وظایف NLP خلاصهسازی، استخراج اطلاعات، تشخیص زبان، ترجمه ماشینی، تشخیص موجودیت، تشخیص گفتار، طبقهبندی متن، رفع ابهام معنایی واژهها
نحو و معنا شناسی
- ساختار جمله و قواعد نحوی
- ابهام نحوی
- معناشناسی و اختلاف ساختار و معنا
- مثالهای کلاسیک مانند عبارت چامسکی
دستور مستقل از بافت (Context-Free Grammar)
- برچسبگذاری اجزای سخن
- گروههای اسمی و فعلی
- ساخت درخت نحوی
- نمایش رسمی قواعد
کتابخانهٔ NLTK
- تعریف قواعد
- تجزیهٔ جملات
- تولید درخت نحوی و رسم آن
n-grams
- تعریف n-gram
- استفاده در پردازش متن و پیشبینی کلمهٔ بعدی
- نمونههای کاربردی
توکنیزهکردن (Tokenization)
- تقسیم متن به واژهها و جملات
- چالشهای نشانهگذاری، علائم، آپاستروف و مخففها
مدلهای مارکوف برای تولید متن
- استفاده از n-gram برای ساخت مدل
- ساخت توزیع احتمال برای انتخاب کلمهٔ بعدی
- تولید متن شبهطبیعی
مدل کیسهٔ واژگان (Bag-of-Words)
- حذف ساختار نحوی
- کاربرد در طبقهبندی و تحلیل احساس
- مثال کاربردی
روش بیز ساده (Naive Bayes)
- استفاده در تحلیل احساس
- سادهسازی احتمالها با فرض استقلال
- مسئلهٔ صفر بودن احتمالها
- هموارسازی افزودنی و لاپلاس
نمایش واژهها
- نمایش یکداغ (One-hot)
- مشکلات ابعاد بزرگ
- نمایش توزیعی
- ایدهٔ فیِرث درباره معنای واژهها
word2vec
- معماری Skip-gram
- لایهٔ پنهان کوچک برای تولید بردارهای معنایی
- شباهت معنایی و محاسبات برداری مانند king − man + woman ≈ queen))
شبکههای عصبی برای زبان
- ترجمهٔ ماشینی و مسئلهٔ دنبالهبهدنباله
- شبکههای بازگشتی و حالت پنهان
- چالشهای وابستگی طولانی
توجه (Attention)
- اهمیتبخشی به واژههای کلیدی
- ایجاد بردار زمینه بر اساس اهمیت واژهها
- بهبود ترجمه و فهم متن
ترنسفورمرها (Transformers)
- پردازش موازی
- جایگذاری موقعیت (Positional Encoding)
- خودتوجهی چندمرحلهای
- معماری رمزگذار–رمزگشا
- نقش کلیدی در مدلهای زبانی مدرن
جمعبندی
- نقش NLP در تکمیل مسیر هوش مصنوعی
- ارتباط آن با شبکهها، یادگیری، احتمال و معناشناس
مقدمهٔ:
پردازش زبان طبیعی یکی از بنیادیترین شاخههای هوش مصنوعی است که میکوشد توانایی انسان در فهم و تولید زبان را در ماشین بازآفرینی کند. تا این مرحله از مسیر یادگیری، با مسائلی سروکار داشتیم که نیازمند بازنمایی دقیق دادهها، استنتاج منطقی، تصمیمگیری در شرایط عدم قطعیت، و یادگیری از طریق نمونهها بودند. با این حال، هیچیک از این حوزهها به پیچیدگی تعامل با زبان انسانی نمیرسند؛ زبانی که ساختاری پویا، سرشار از ابهام، وابسته به زمینه و دارای لایههای عمیق معنایی است.
آموزش هوش مصنوعی
در این درس با مفاهیم و ابزارهایی آشنا میشویم که به هوش مصنوعی امکان میدهند متون انسانی را تحلیل، پردازش و تولید کند. نخست به سازوکارهای نحوی و معنایی میپردازیم و میآموزیم چگونه میتوان ساختار جمله را بهصورت صوری بازنمایی کرد. سپس با الگوهای آماری همچون n-gram، مدلهای مارکوف و روشهای کلاسیک تحلیل متن آشنا میشویم. در ادامه، مدلهای سادهای مانند کیسهٔ واژگان و طبقهبندی مبتنی بر بیز ساده را بررسی میکنیم و پس از آن به مباحث پیشرفتهتر از جمله نمایش توزیعی واژهها، شبکههای عصبی، مکانیسم توجه و معماری ترنسفورمر میرسیم؛ معماریای که بنیان بسیاری از مدلهای زبانی امروزی را شکل میدهد.
این درس پلی میان مبانی نظری هوش مصنوعی و کاربردهای عملی آن در حوزهٔ زبان است؛ حوزهای که در قلب تعامل انسان و ماشین قرار دارد و نقشی اساسی در توسعهٔ سیستمهای هوشمند امروزی ایفا میکند.
زبان:
تا این مرحله از درس، لازم بود مسئلهها و دادهها را به گونهای قالببندی کنیم که یک سامانهٔ هوش مصنوعی قادر به پردازش آنها باشد. اکنون به این میپردازیم که چگونه میتوان سامانهای ساخت که زبان انسان را پردازش کند.
پردازش زبان طبیعی (NLP) تمامی وظایفی را دربرمیگیرد که در آنها ورودیِ سامانه، زبان انسانی است. نمونههایی از این وظایف عبارتاند از:
- خلاصهسازی خودکار: در این وظیفه، متن بهعنوان ورودی داده میشود و سامانه خلاصهای از همان متن تولید میکند.
- استخراج اطلاعات: در این حالت، سامانه مجموعهای از متون را دریافت میکند و دادههای ساختاریافته را از میان آنها استخراج مینماید.
- تشخیص زبان: در این وظیفه، سامانه متنی را دریافت کرده و زبان متن را تشخیص میدهد.
- ترجمهٔ ماشینی: سامانه متنی را در یک زبان دریافت کرده و ترجمهٔ آن را در زبان مقصد تولید میکند.
- شناسایی موجودیتهای نامدار (NER): سامانه متن را دریافت میکند و نام موجودیتهایی مانند افراد، شرکتها یا مکانها را استخراج میکند.
- تشخیص گفتار: ورودی سامانه صدا یا گفتار است و خروجی آن تبدیل همان گفتار به متن نوشتاری است.
- طبقهبندی متن: سامانه متن ورودی را دریافت میکند و آن را در یکی از دستههای از پیش تعریفشده قرار میدهد.
- تشخیص معنای درست واژه (Word Sense Disambiguation): سامانه باید برای واژهای که چند معنا دارد، معنای صحیح را با توجه به متن انتخاب کند (مثلاً واژهٔ bank میتواند «بانک مالی» یا «کرانهٔ رودخانه» باشد).
آموزش هوش مصنوعی
نحو و معناشناسی:
نحو (Syntax) به ساختار جمله اشاره دارد. ما بهعنوان سخنگویان طبیعی یک زبان، در تولید جملههای دستوری و تشخیص جملههای نادرست از نظر دستوری مشکلی نداریم. برای مثال، جملهٔ
«چند دقیقه مانده به ساعت نه، شرلوک هولمز با گامهایی تند وارد اتاق شد»
کاملاً دستوری است؛ در حالی که جملهٔ
«چند دقیقه شرلوک هولمز مانده به ساعت نه وارد تند اتاق شد»
از نظر نحوی نادرست است.
با این حال، یک جمله میتواند از نظر نحوی درست اما همچنان مبهم باشد؛ مانند جملهٔ «I saw the man with the telescope».
در این جمله مشخص نیست «با تلسکوپ» توصیف «مرد» است یا اینکه گوینده «مرد را با استفاده از تلسکوپ دیده است». بنابراین، برای آنکه هوش مصنوعی بتواند زبان انسان را تحلیل کرده و خود نیز جمله تولید کند، باید قادر به فهم و مدیریت ساختار نحوی باشد.
معناشناسی (Semantics) به معنی واژهها و جملهها مربوط میشود.
برای نمونه، جملهٔ
«شرلوک هولمز درست پیش از ساعت نه وارد اتاق شد»
از نظر دستوری با جملهٔ
«درست پیش از ساعت نه، شرلوک هولمز وارد اتاق شد»
متفاوت است، اما معنای هر دو یکسان است. همچنین جملهٔ
«چند دقیقه مانده به ساعت نه، شرلوک هولمز با سرعت وارد اتاق شد»
از واژههای متفاوتی استفاده میکند، اما معنایی بسیار مشابه دارد.
از سوی دیگر، ممکن است جملهای از نظر نحوی کاملاً درست باشد اما هیچ معنای قابلفهمی نداشته باشد. نمونهٔ کلاسیک این موضوع جملهٔ چامسکی است:
«ایدههای سبز بیرنگ با شدّت میخوابند.»
این جمله از نظر ساختار کاملاً صحیح است، اما معنای منطقی ندارد.
بنابراین، برای اینکه یک سامانهٔ هوشمند بتواند زبان انسان را تحلیل یا تولید کند، به درک درست هم نحو و هم معناشناسی نیاز دارد.
گرامرِ مستقل از بافت (Context-Free Grammar):
گرامر صوری مجموعهای از قواعد است که امکان تولید جملهها را در یک زبان فراهم میکند. در گرامر مستقل از بافت، متن از معنای خود جدا میشود تا ساختار جمله تنها بر اساس قواعد نحوی و بهصورت صوری نمایش داده شود.
به جملهٔ زیر توجه کنید:
- She saw the city.
این جمله ساده و دستوری است و هدف ما ساختن یک درخت نحوی برای نمایش ساختار آن است.
نخست، هر واژه را بر اساس نقش دستوری آن مشخص میکنیم.
واژههای she و city اسماند و آنها را با N نشان میدهیم.
واژهٔ saw فعل است و با V مشخص میشود.
واژهٔ the یک تعیینکننده است که اسم بعدی را تعریف یا نامعین میکند و با D نمایش داده میشود.
بنابراین جمله را میتوان به شکل زیر بازنویسی کرد:
-
N V D N
تا این مرحله، معنای واژهها را نادیده گرفته و تنها نقشهای دستوریشان را در نظر گرفتهایم.
اما واژهها در جمله با یکدیگر پیوند دارند و برای تحلیل جمله لازم است این پیوندها را تشخیص دهیم.
- گروه اسمی (Noun Phrase – NP) مجموعهای از واژههاست که حول یک اسم شکل میگیرند.
در این جمله، she یک گروه اسمی است.
همچنین the city نیز یک گروه اسمی تشکیل میدهد که شامل یک تعیینکننده و یک اسم است. - گروه فعلی (Verb Phrase – VP) نیز گروهی از واژههاست که به فعل وابستهاند.
در سادهترین حالت، saw خود یک گروه فعلی است؛ اما عبارت saw the city نیز یک گروه فعلی کامل است که دربرگیرندهٔ یک فعل و یک گروه اسمی است — گروه اسمیای که خود از یک تعیینکننده و یک اسم تشکیل شده.
در نهایت، کل جمله (S) را میتوان به صورت زیر نمایش داد:
آموزش هوش مصنوعی
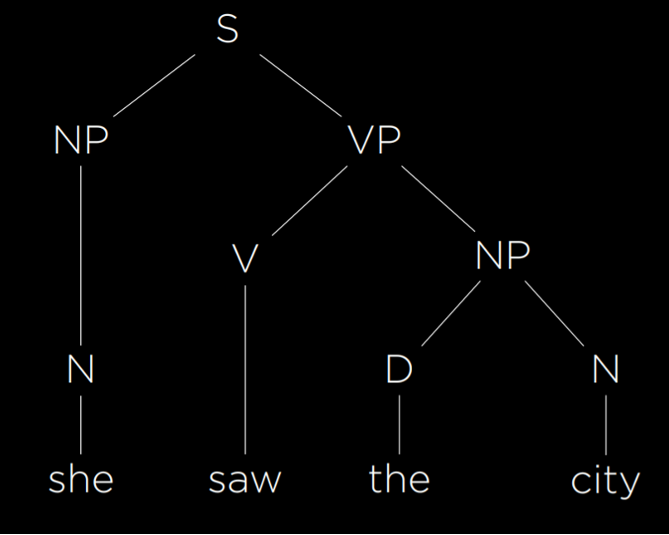
با استفاده از گرامر صوری، یک سامانهٔ هوش مصنوعی قادر میشود ساختار جملهها را بازنمایی کند. در گرامری که تاکنون توصیف شد، قواعد کافی برای نمایش جملهٔ سادهٔ پیشین وجود دارد. با این حال، برای نمایش جملههای پیچیدهتر، باید قواعد بیشتری به گرامر صوری اضافه کنیم.
Nltk:
همانگونه که در بسیاری از حوزههای پایتون رایج است، کتابخانههای متعددی برای پیادهسازی این مفاهیم طراحی شدهاند. یکی از مهمترین این کتابخانهها nltk (Natural Language Toolkit) است. برای تحلیل جملهٔ پیشین، کافی است مجموعهای از قواعد دستوری را در اختیار این ابزار قرار دهیم تا بتواند ساختار جمله را مطابق گرامر تعیینشده تشخیص دهد.
هوش مصنوعی
import nltk
grammar = nltk.CFG.fromstring("""
S -> NP VP
NP -> D N | N
VP -> V | V NP
D -> "the" | "a"
N -> "she" | "city" | "car"
V -> "saw" | "walked"
""")
parser = nltk.ChartParser(grammar)
بهشیوهای مشابه آنچه پیشتر انجام دادیم، تعیین میکنیم که هر جزء زبانی چگونه میتواند شامل اجزای دیگر باشد. یک جمله میتواند از یک گروه اسمی (NP) و یک گروه فعلی (VP) تشکیل شود، و هر یک از این گروهها نیز ممکن است خود شامل گروهها یا اجزای دیگری باشند؛ مانند گروههای اسمی کوچکتر، گروههای فعلی، اسمها، فعلها و جزئیات دیگر. در نهایت، هر نقش دستوری مجموعهای از واژههای موجود در زبان را دربرمیگیرد.
هوش مصنوعی
sentence = input("Sentence: ").split()
try:
for tree in parser.parse(sentence):
tree.pretty_print()
tree.draw()
except ValueError:
print("No parse tree possible.")
پس از آنکه جملهٔ ورودی را بهصورت فهرستی از واژهها در اختیار الگوریتم قرار دهیم، این تابع درخت نحوی حاصل را چاپ میکند با استفاده از pretty_print و همچنین یک نمایش گرافیکی از ساختار جمله را نیز تولید میکند با استفاده از draw
آموزش هوش مصنوعی
nگرامها:
nگرام دنبالهای متشکل از n واحد از یک متن است. در nگرامِ کاراکتری، این واحدها کاراکترها هستند و در nگرامِ واژگانی، واحدها واژهها.
یک تکگرام (unigram) شامل یک واحد، دوگرام (bigram) شامل دو واحد و سهگرام (trigram) شامل سه واحد است.
در جملهٔ زیر، سه nگرام نخست عبارتاند از:
«how often have»، «often have I»، و «have I said».
“How often have I said to you that when you have eliminated the impossible whatever remains, however improbable, must be the truth?”
nگرامها در پردازش متن کاربرد فراوان دارند. ممکن است سامانهٔ هوش مصنوعی پیشتر کل جمله را ندیده باشد، اما بهاحتمال زیاد بخشهایی از آن را دیده است؛ مانند «have I said».
از آنجا که برخی واژهها بیش از بقیه همراه یکدیگر ظاهر میشوند، میتوان بر اساس احتمالات، ادامهٔ جمله یا واژهٔ بعدی را پیشبینی کرد. برای نمونه، گوشی هوشمند شما واژههای پیشنهادی را بر اساس توزیع احتمالیای که از آخرین واژههای تایپشده به دست آمده است، ارائه میدهد.
بنابراین، شکستن جملهها به nگرامها یک گام سودمند و اولیه در پردازش زبان طبیعی به شمار میرود.
توکنسازی (Tokenization)
توکنسازی فرایند تقسیم یک رشتهٔ کاراکتر به واحدهای کوچکتر به نام توکن است.
توکن میتواند کلمه باشد یا جمله؛ به همین ترتیب، این کار میتواند توکنسازیِ واژهای یا توکنسازیِ جملهای نامیده شود.
برای آنکه بتوانیم nگرامها را بررسی کنیم، ابتدا باید متن را به توکنها تقسیم کنیم؛ زیرا nگرامها بر پایهٔ دنبالههایی از توکنها ساخته میشوند.
سادهترین راه برای شروع، شکستن متن براساس فاصلهٔ بین کلمات است.
اما این روش کامل نیست، زیرا در نتیجه، کلماتی همراه با نشانهگذاری ظاهر میشوند، مانند:
- «remains,»
- «impossible.»
پس تلاش میکنیم نشانهگذاریها (punctuation) را حذف کنیم؛ ولی این کار مشکلات دیگری ایجاد میکند، مانند:
- کلمات دارای آپوستروف (o’clock)
- کلمات دارای خط تیره (pearl-grey)
علاوه بر این، برخی نشانهگذاریها برای ساختار جمله بسیار مهماند؛ مثلاً نقطه.
اما باید بتوانیم تفاوت بین نقطهٔ پایان جمله و نقطهای که در انتهای کلمهای مانند Mrقرار میگیرد را تشخیص دهیم.
رسیدگی به تمام این موارد بخشی از فرایند توکنسازی است.
پس از آنکه توکنها را بهدرستی استخراج کردیم، اکنون میتوانیم از آنها برای تشکیل nگرامها استفاده کنیم.
مدلهای مارکوف (Markov Models):
همانگونه که در جلسات پیشین توضیح داده شد، مدلهای مارکوف از مجموعهای از گرهها تشکیل میشوند که مقدار هر گره بر اساس توزیع احتمالی وابسته به تعداد محدودی از گرههای پیشین تعیین میشود. یکی از کاربردهای این مدلها، تولید متن است.
برای این منظور، ابتدا مدل را بر روی یک متن آموزش میدهیم و سپس احتمال رخ دادن هر توکن در یک n-گرام را بر اساس n واژهٔ پیش از آن محاسبه میکنیم.
برای مثال، در استفاده از تریگرامها (trigrams)، زمانی که مدل دو واژهٔ نخست را در اختیار دارد، میتواند واژهٔ سوم را مطابق با یک توزیع احتمالی مبتنی بر آن دو واژه انتخاب کند. پس از آن، واژهٔ چهارم بر اساس توزیع احتمالی حاصل از واژهٔ دوم و سوم انتخاب میشود و روند به همین ترتیب ادامه مییابد.
برای مشاهدهٔ پیادهسازی چنین مدلی با استفاده از کتابخانهٔ nltk میتوان به فایل generator.py در کد منبع مراجعه کرد؛ در آنجا مدلی آموزش داده میشود که قادر است جملاتی با حالوهوای مشابه سبک شکسپیر ایجاد کند.
در نهایت، مدلهای مارکوف قادرند متنی تولید کنند که اغلب از نظر ساختار دستوری صحیح بوده و شباهتی سطحی به زبان انسانی دارد؛ اما معمولاً فاقد معنا، انسجام و هدف واقعی است.
مدل کیسهٔ واژگان (Bag-of-Words Model):
مدل «کیسهٔ واژگان» روشی است که در آن متن بهصورت مجموعهای نامرتب از واژهها نمایش داده میشود. در این مدل، ساختار نحویِ جمله نادیده گرفته میشود و تنها وجود یا تکرار واژهها اهمیت دارد. این رویکرد در برخی مسائلِ طبقهبندی، مانند تحلیل احساسات یا تشخیص هرزنامهبودن ایمیل، بسیار سودمند است.
برای نمونه، در تحلیل احساسات مربوط به نقد و بررسی محصولات، هدف آن است که هر متن در دستهٔ «مثبت» یا «منفی» قرار گیرد. به جملات زیر توجه کنید:
- «نوهام عاشقش شد! بسیار سرگرمکننده بود!»
- «محصول پس از چند روز خراب شد.»
- «یکی از بهترین بازیهایی است که پس از مدتها انجام دادهام.»
- «ارزان و بیدوام؛ به درد نمیخورد.»
با تکیه بر خودِ واژهها و بدون توجه به دستور زبان، میتوان دریافت که جملات ۱ و ۳ ماهیتی مثبت دارند («عاشق»، «سرگرمکننده»، «بهترین»). در مقابل، جملات ۲ و ۴ منفی هستند («خراب»، «ارزان»، «بیدوام»).
نِیو بیز (Naive Bayes):
نِیو بیز یک روش آماری است که میتوان آن را در کنار مدل کیسهٔ واژگان برای تحلیل احساسات بهکار برد. در مسئلهٔ تحلیل احساسات، پرسش اصلی این است:
«با توجه به واژههای موجود در جمله، احتمال مثبت یا منفی بودن آن چقدر است؟»
برای پاسخ به این پرسش، باید احتمالهای شرطی را محاسبه کنیم؛ زیرا میخواهیم بدانیم احتمال تعلق یک جمله به یک طبقهٔ خاص (مثبت یا منفی) با توجه به نشانههایی که از متن مشاهده میکنیم، چیست.
در این زمینه، یادآوری قانون بیز که در درس دوم مطرح شد، بسیار مفید خواهد بود.
آموزش هوش مصنوعی
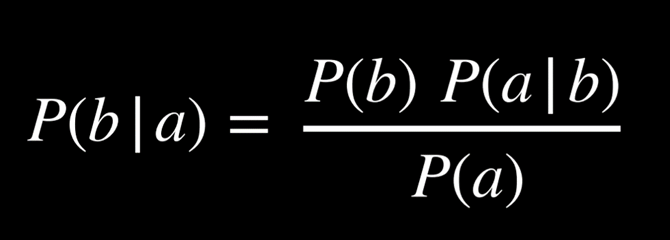
اکنون میخواهیم این فرمول را برای محاسبهٔ P(sentiment | text) بهکار ببریم؛ برای مثال، احتمال مثبت بودن جملهٔ
«my grandson loved it» را بیابیم، یعنی P(positive | “my”, “grandson”, “loved”, “it”).
ابتدا متن ورودی را توکنسازی میکنیم تا جمله به مجموعهای از واژهها تبدیل شود. با استفادهٔ مستقیم از قانون بیز، به عبارت زیر خواهیم رسید:
P(“my”, “grandson”, “loved”, “it” | positive) × P(positive) / P(“my”, “grandson”, “loved”, “it”)
این فرمول پاسخ دقیق احتمال مثبت بودن جمله را ارائه میکند؛ اما محاسبهٔ آن پیچیده و پرهزینه است. برای سادهتر کردن مسئله، میتوانیم تنها مقداری را بیابیم که با احتمال اصلی متناسب باشد، نه لزوماً برابر آن. سپس، در مرحلهٔ نهایی، با توجه به اینکه مجموع احتمالات باید برابر یک باشد، مقدار بهدستآمده را نرمالسازی میکنیم تا به احتمال واقعی تبدیل شود.
بر این اساس، میتوانیم عبارت فوق را به صورت سادهشدهٔ صورت کسر بازنویسی کنیم:
P(“my”, “grandson”, “loved”, “it” | positive) × P(positive)
از آنجا که میدانیم احتمال شرطیِ «a با فرض b» متناسب با احتمال مشترک «a و b» است، این رابطه را میتوان به شکل زیر بازنویسی کرد:
P(positive, “my”, “grandson”, “loved”, “it”) × P(positive)
با این حال، محاسبهٔ این احتمال مشترک دشوار است، زیرا احتمال هر واژه به واژههای پیش از خود وابسته است. محاسبهٔ دقیق نیازمند تعیین مفاهیمی از این دست است:
P(positive) × P(“my” | positive) × P(“grandson” | positive, “my”) × P(“loved” | positive, “my”, “grandson”) × P(“it” | positive, “my”, “grandson”, “loved”)
در این مرحله، فرض سادهکنندهٔ نایو بیز به کار میآید:
فرض میکنیم احتمال هر واژه از احتمال دیگر واژهها مستقل است.
این فرض در واقع درست نیست، زیرا واژهها در زبان طبیعی همبستگی زیادی دارند، اما با وجود این سادهسازی، روش نایو بیز معمولاً تخمینهای بسیار خوبی ارائه میدهد.
با اعمال این فرض استقلال، عبارت پیچیدهٔ پیشین به شکل زیر ساده میشود:
P(positive) × P(“my” | positive) × P(“grandson” | positive) × P(“loved” | positive) × P(“it” | positive)
اکنون محاسبهٔ هر یک از این مؤلفهها آسان است:
- P(positive) برابر است با:
تعداد نمونههای مثبت / تعداد کل نمونهها. - P(“loved” | positive) برابر است با:
تعداد نمونههای مثبت شامل واژهٔ «loved» / تعداد کل نمونههای مثبت.
در ادامه، مثالی ارائه میشود که در آن از دو شکلک خندان و ناراحت بهجای برچسبهای «مثبت» و «منفی» استفاده شده است.
آموزش هوش مصنوعی

- در جدول سمت راست، احتمالهای شرطیِ مربوط به هر واژه (در ستون چپ) مشاهده میشود؛ یعنی احتمال وقوع هر واژه در جملهای که برچسب آن مثبت یا منفی است.
- در جدول کوچک سمت چپ، احتمال کلیِ مثبت یا منفی بودن یک جمله نشان داده شده است.
- در جدول پایینِ سمت چپ، نتایج حاصل از محاسبات قرار دارند. در این مرحله، این مقادیر صرفاً نسبتهای احتمالات را نشان میدهند و بهتنهایی معنای دقیقی از احتمال ارائه نمیدهند. برای تبدیل این مقادیر به احتمال واقعی، باید آنها را نرمالسازی کنیم. پس از نرمالسازی، به نتایج زیر میرسیم:
P(positive) = 0.6837
P(negative) = 0.3163
- قدرت روش نِیو بیز در این است که نسبت به واژههایی حساس است که در یک نوع جمله (مثبت یا منفی) بیشتر تکرار میشوند. برای مثال، در نمونهٔ ما واژهٔ “loved” در جملات مثبت بسیار بیشتر از جملات منفی دیده شده است.بنابراین، وجود این واژه احتمال مثبت بودن جمله را افزایش میدهد. برای مشاهدهٔ پیادهسازی تحلیل احساسات با استفاده از نایو بیز در کتابخانهٔ nltk میتوانید به فایل sentiment.py مراجعه کنید.یکی از مشکلات احتمالی این است که ممکن است برخی واژهها در هیچ جملهٔ متعلق به یک دسته دیده نشوند. فرض کنید در هیچیک از جملات مثبت واژهٔ “grandson” وجود نداشته باشد؛ در این صورت:
P(“grandson” | positive) = 0
و هنگام محاسبهٔ احتمال مثبت بودن جمله، کل حاصلضرب به صفر تبدیل میشود؛ حال آنکه در واقعیت، جملههایی که واژهٔ «grandson» در آنها ظاهر میشود لزوماً منفی نیستند.
- یکی از راههای حل این مشکل، استفاده از هموارسازی جمعی (Additive Smoothing) است. در این روش، عددی به نام α به تمام مقادیر توزیع افزوده میشود تا دادهها هموار شوند. در نتیجه، حتی اگر مقدار احتمالی برابر صفر باشد، با افزودن α از بین نمیرود و احتمال کامل جمله به صفر ضرب نمیشود.نوع خاصی از این روش که هموارسازی لاپلاس (Laplace Smoothing) نام دارد، مقدار ۱ را به همهٔ فراوانیها اضافه میکند؛ بدین معنا که وانمود میکنیم هر واژه حداقل یک بار مشاهده شده است.
آموزش هوش مصنوعی
- ما میخواهیم معنای واژهها را در سامانهٔ هوش مصنوعی بازنمایی کنیم. همانگونه که پیشتر مشاهده کردیم، مناسبترین شیوه برای ارائهٔ ورودی به هوش مصنوعی، استفاده از دادههای عددی است. یکی از روشهای متداول برای این کار، بازنمایی تکداغ (One-Hot Representation) است.در این شیوه، هر واژه با برداری نشان داده میشود که تعداد مؤلفههای آن برابر با تعداد کل واژههاست. در این بردار، تنها یکی از مؤلفهها مقدار ۱ دارد و سایر مؤلفهها برابر ۰ هستند. تمایز میان واژهها از طریق همان موقعیتی ایجاد میشود که مقدار ۱ در آن قرار گرفته است؛ بدین ترتیب، هر واژه دارای برداری منحصربهفرد خواهد بود.برای نمونه، جملهٔ «He wrote a book» را میتوان با چهار بردار نشان داد که هر یک نمایندهٔ یکی از واژههای جمله است.

با این حال، هرچند این شیوهٔ بازنمایی در دنیایی با تنها چهار واژه کارآمد به نظر میرسد، در مقیاسهای بزرگتر—برای مثال زمانی که قصد داشته باشیم واژههای یک فرهنگ لغت با ۵۰ هزار واژه را نمایش دهیم—با مشکلی جدی روبهرو میشویم. در چنین حالتی، باید ۵۰ هزار بردارِ ۵۰ هزارعنصری تولید کنیم، که از نظر محاسباتی و ذخیرهسازی بسیار ناکارآمد است.
آموزش هوش مصنوعی
مسئلهٔ دیگر این روش آن است که نمیتواند شباهت معنایی میان واژهها را بازنمایی کند؛ برای نمونه، در این ساختار هیچ ارتباطی میان واژههای “wrote” و “authored” برقرار نمیشود، در حالی که از نظر معنایی بسیار نزدیکاند.
برای رفع این محدودیتها، رویکردی متفاوت به نام بازنمایی توزیعی (Distributed Representation) مطرح میشود. در این روش، معنا در میان چندین مقدار عددی در یک بردار پخش میشود. هر واژه با برداری نسبتاً کوتاه (بهمراتب کوتاهتر از ۵۰ هزار مؤلفه) نمایش داده میشود و این مقادیر به گونهای انتخاب میشوند که بتوانند شباهت معنایی میان واژهها را نیز منعکس کنند. شکل کلی این نوع بردارها به صورت زیر است:

آموزش هوش مصنوعی
این رویکرد به ما امکان میدهد که برای هر واژه برداری یکتا تولید کنیم، بیآنکه مجبور باشیم از بردارهای بسیار بزرگ استفاده کنیم. افزون بر این، اکنون میتوانیم شباهت میان واژهها را نیز بر اساس میزان تفاوت یا نزدیکی مقادیر موجود در بردارهای آنها بازنمایی کنیم.
جملهٔ مشهور «معنای یک واژه را میتوان از همراهانی که در کنار آن ظاهر میشوند شناخت» از زبانشناس انگلیسی، جان روپرت فرث، مبنای نظری مهمی در پردازش زبان طبیعی است. بر اساس این ایده، میتوان واژهها را از طریق واژههایی که معمولاً در کنار آنها میآیند تعریف کرد.
برای نمونه، تنها تعداد محدودی از واژهها میتوانند جای خالی جملهٔ «for ___ he ate» را پر کنند. واژههایی مانند breakfast، lunch و dinner از گزینههای معقول هستند. این مشاهده ما را به این نتیجه میرساند که با بررسی بافت (Context) یا محیطی که واژهها در آن ظاهر میشوند، میتوانیم به معنای آنها پی ببریم.
word2vec:
Word2vec الگوریتمی است برای تولید بازنماییهای توزیعشده از واژهها. این الگوریتم از معماری Skip-Gram بهره میگیرد؛ معماریای مبتنی بر شبکههای عصبی که در آن، مدل میکوشد با داشتن یک واژهٔ هدف، واژههای پیرامونی یا واژههایی را که معمولاً در همان بافت ظاهر میشوند پیشبینی کند.
در این ساختار، شبکهٔ عصبی دارای یک لایهٔ ورودی است که برای هر واژهٔ هدف یک واحد مشخص دارد. سپس یک لایهٔ پنهان کوچک—معمولاً با ۵۰ یا ۱۰۰ واحد (اما این تعداد قابل تغییر است)—وجود دارد که مقادیر حاصل از آن همان بازنمایی توزیعشدهٔ واژهها را شکل میدهد. هر واحد در این لایهٔ پنهان به تمامی واحدهای لایهٔ ورودی متصل است.
در نهایت، لایهٔ خروجی واژههایی را تولید میکند که احتمال دارد در همان بافت معناییِ واژهٔ هدف ظاهر شوند. همانند آنچه در جلسهٔ پیش مشاهده کردیم، این شبکه نیز باید با استفاده از یک مجموعهدادهٔ آموزشی و از طریق الگوریتم پسانتشار خطا (Backpropagation) آموزش داده شود تا بتواند بازنماییهای دقیق و معناداری از واژهها بیافریند.
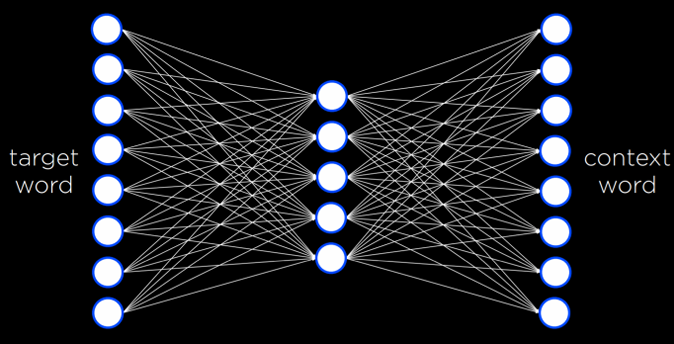
آموزش هوش مصنوعی
این شبکهٔ عصبی در عمل توانمندی چشمگیری دارد. در پایان فرایند آموزش، هر واژه بهصورت صرفاً یک بردار یا سلسلهای از اعداد بازنمایی میشود. برای مثال:

بهخودیِ خود، این اعداد معنای خاصی ندارند. اما با سنجش اینکه کدام واژههای دیگر در پیکرهٔ زبانی، بردارهایی مشابهتر دارند، میتوان تابعی اجرا کرد که واژههای بیشترین قرابت معنایی با book را بازتولید کند. در مورد این شبکه، خروجی چنین خواهد بود: book، books، essay، memoir، essays، novella، anthology، blurb، autobiography، audiobook. این نتیجه برای یک رایانه چندان کماهمیت نیست!
مجموعهای از اعداد که بهتنهایی حامل هیچ معنای مشخصی نیستند، به شبکه اجازه میدهند واژههایی را بیابد که نه از نظر نوشتار یا آوا، بلکه از نظر معنا به book نزدیکاند.
آموزش هوش مصنوعی
همچنین میتوانیم با سنجش میزان اختلاف میان بردارها، فاصلهٔ معنایی میان واژهها را اندازهگیری کنیم. برای مثال، تفاوت میان king و man مشابه تفاوت میان queen و woman است. به بیان دیگر، اگر اختلاف بردارهای king و man را به بردار woman اضافه کنیم، نزدیکترین بردار به نتیجه، واژهٔ queen خواهد بود. بهطور مشابه، اگر اختلاف میان ramen و japan را به america بیفزاییم، خروجی به واژهٔ burritos میرسد.
با بهرهگیری از شبکههای عصبی و بازنمایی توزیعی واژهها، میتوانیم به هوش مصنوعی توانایی درک شباهتهای معنایی میان واژههای زبان را بدهیم؛ تواناییای که ما را یک گام دیگر به ساخت سامانههایی نزدیک میکند که قادر به فهم و تولید زبان انسانیاند.
شبکههای عصبی:
به یاد داریم که یک شبکهٔ عصبی ورودی را دریافت میکند، آن را در شبکه پردازش میکند و در نهایت خروجیای تولید میکند. هنگامی که دادههای آموزشی در اختیار شبکه قرار میگیرد، شبکه بهتدریج در تبدیل ورودیها به خروجیهای دقیقتر توانمندتر میشود. یکی از کاربردهای رایج این شبکهها، ترجمهٔ ماشینی است.
در عمل، هنگام ترجمهٔ واژهها، هدف ترجمهٔ یک جمله یا یک بند است. از آنجا که طول جمله ثابت نیست، با مسئلهٔ ترجمهٔ «یک دنباله به دنبالهای دیگر با طول متغیر» روبهرو میشویم. اگر تاکنون با یک چتبات گفتوگو کرده باشید، میدانید که سامانه باید یک دنبالهٔ از کلمات را درک کند و سپس دنبالهای مناسب را بهعنوان پاسخ تولید نماید.
شبکههای عصبی بازگشتی
شبکههای عصبی بازگشتی (RNN) با اجرای چندبارهٔ یک شبکه و نگهداشتن حالتی که اطلاعات مرتبط را ذخیره میکند، این چالش را مدیریت میکنند. ورودی نخست وارد شبکه میشود و یک «حالت پنهان» میسازد. سپس، ورودی دوم همراه با حالت پنهان قبلی وارد رمزگذار میشود و حالت پنهان جدیدی را شکل میدهد. این روند تا رسیدن به نشانهٔ پایان ادامه مییابد.
پس از آن، مرحلهٔ رمزگشایی آغاز میشود؛ شبکه یکی پس از دیگری حالتهای پنهان را میسازد تا سرانجام به واژهٔ نهایی و نشانهٔ پایان خروجی برسد.
چالشها
با وجود کارآمدی RNNها، دو مشکل اساسی در این روش دیده میشود:
- فشردهسازی تمام اطلاعات در یک حالت نهایی
در مرحلهٔ رمزگذاری، تمام اطلاعات ورودی باید در یک حالت نهایی ذخیره شود. برای دنبالههای طولانی، قرار دادن این حجم از اطلاعات در یک حالت منفرد بسیار دشوار است. - اهمیت نابرابر واژهها در توالی
در یک جمله، همهٔ واژهها اهمیت یکسان ندارند. برخی واژهها نقش کلیدیتری در معنا دارند. بنابراین پرسش این است که آیا میتوان روشی داشت که تعیین کند کدام حالتها (یا کلمات) از اهمیت بیشتری برخوردارند؟
توجه: (Attention)
«توجه» به توانایی شبکهٔ عصبی اشاره دارد که تشخیص دهد کدام بخشهای ورودی اهمیت بیشتری دارند. برای مثال، در جملهٔ «پایتخت ماساچوست چیست؟»، سازوکار توجه به شبکه کمک میکند هنگام تولید پاسخ، تصمیم بگیرد در هر مرحله بر کدام واژهها تمرکز کند.
در چنین محاسباتی، شبکهٔ عصبی نشان میدهد که هنگام تولید آخرین واژهٔ پاسخ، دو واژهٔ «capital» و «Massachusetts» بیشترین اهمیت را دارند. شبکه با گرفتن «امتیازهای توجه»، ضرب آنها در حالتهای پنهان تولیدشده و سپس جمعکردن نتیجهها، یک «بردار زمینهٔ نهایی» میسازد؛ برداری که رمزگشا از آن برای محاسبهٔ واژهٔ نهایی استفاده میکند.
با این حال، رویکردهای مبتنی بر شبکههای بازگشتی با چالشی مهم مواجهاند:
لزوم آموزش ترتیبی، واژهبهواژه و گامبهگام. این ویژگی فرایند آموزش را بسیار زمانبر میکند؛ مشکلی که با افزایش اندازهٔ مدلهای زبانی و گسترش مجموعههای داده هر روز شدیدتر میشود.
در نتیجه، نیاز به پردازش موازی بهطور چشمگیری افزایش یافته است. همین نیاز، زمینهساز معرفی معماری جدیدی شد که امروز اساس بسیاری از مدلهای پیشرفتهٔ زبانی به شمار میآید.
ترنسفورمرها (Transformers):
«ترنسفورمر» نسل جدیدی از معماریهای آموزش شبکههای عصبی است که در آن، تمام واژههای ورودی بهصورت همزمان وارد شبکه میشوند. هر واژه پس از ورود، از میان یک شبکهٔ عصبی عبور میکند و به شکلی «رمزشده» (encoded representation) بازنمایی میشود.
از آنجا که همهٔ واژهها به طور موازی پردازش میشوند، ترتیب واژهها ممکن است از دست برود.
به همین دلیل، رمزگذاری موقعیت (positional encoding) به ورودی اضافه میشود تا شبکه، علاوه بر خودِ واژه، از جایگاه آن در جمله نیز آگاه باشد.
علاوه بر این، مرحلهای به نام خودتوجهی (self-attention) به مدل افزوده میشود که به شبکه کمک میکند با توجه به سایر واژههای جمله، معنای دقیقتر و بافت مناسبتری از هر واژه استخراج کند. معمولاً چندین لایهٔ خودتوجهی پشتسر هم استفاده میشود تا شبکه بتواند وابستگیها و روابط پیچیدهتری را میان واژهها درک کند. این فرایند برای تمامی واژههای دنبالهٔ ورودی تکرار میشود و در نهایت، مجموعهای از بازنماییهای رمزشده به دست میآید که برای مرحلهٔ «رمزگشایی» بسیار کارآمد هستند.
در مرحلهٔ رمزگشایی، واژهٔ خروجی قبلی همراه با رمزگذاری موقعیت آن، وارد چندین مرحلهٔ خودتوجهی و سپس شبکهٔ عصبی میشود. علاوه بر این، لایههای توجه دیگری نیز وجود دارند که بازنماییهای رمزشدهٔ مرحلهٔ رمزگذاری را دریافت میکنند و در اختیار رمزگشا قرار میدهند. بدین ترتیب،
واژههای خروجی میتوانند انحصاراً بر یکدیگر و همچنین بر واژههای ورودی تمرکز کنند.
ترنسفورمرها این امکان را فراهم میکنند که پردازش بهطور کامل موازی انجام شود؛ نتیجه آن است که محاسبات سریعتر، دقیقتر و مقیاسپذیرتر از معماریهای پیشین—بهویژه شبکههای بازگشتی—خواهد بود. همین ویژگیها سبب شده است که ترنسفورمرها به معماری اصلی در مدلهای زبانی پیشرفتهٔ امروزی تبدیل شوند.
جمعبندی:
- در این مسیر، هوش مصنوعی را در مجموعهای گسترده از زمینهها بررسی کردیم. ابتدا با مسائل جستوجو آشنا شدیم و دیدیم که یک سامانهٔ هوشمند چگونه میتواند برای یافتن راهحلها در فضاهای پیچیده جستوجو کند. سپس آموختیم که هوش مصنوعی چگونه دانش را بازنمایی میکند و از آن دانش، آگاهیهای جدید به دست میآورد.
- در ادامه، با مفهوم عدم قطعیت روبهرو شدیم؛ شرایطی که در آن سیستم همه چیز را بهطور کامل نمیداند، اما همچنان باید بهترین تصمیم ممکن را اتخاذ کند. همچنین با بهینهسازی آشنا شدیم؛ فرایندی برای بیشینهسازی یا کمینهسازی یک تابع برای رسیدن به کاراترین نتیجه.
- در بخشهای بعد، وارد حوزهٔ یادگیری ماشین شدیم—جایی که سیستم با مشاهدهٔ دادههای آموزشی، الگوها را کشف میکند. سپس شبکههای عصبی را بررسی کردیم و دیدیم چگونه وزنها و پارامترها امکان تبدیل ورودیها به خروجیها را فراهم میکنند.
- در نهایت، به سراغ پردازش زبان طبیعی رفتیم و تلاش کردیم بفهمیم چگونه میتوان رایانه را قادر ساخت زبان انسان را درک کند و به آن واکنش نشان دهد. آنچه بررسی کردیم، تنها مقدمهای بر این جهان گسترده است.
- امیدواریم این مسیر یادگیری برای شما ارزشمند و الهامبخش بوده باشد. این دوره، مقدمهای بر هوش مصنوعی با پایتون بود.
خلاصهٔ :
- این درس به بررسی شیوههایی میپردازد که هوش مصنوعی از طریق آنها قادر میشود زبان انسانی را درک و پردازش کند. ابتدا مفهوم پردازش زبان طبیعی (NLP) و نمونههایی از کاربردهای آن معرفی میشود؛ از جمله خلاصهسازی خودکار، استخراج اطلاعات، تشخیص زبان، ترجمهٔ ماشینی، بازشناسی گفتار، طبقهبندی متون و تشخیص معنای درست واژهها در بافت جمله.
آموزش هوش مصنوعی
- در بخش نخست، دو مؤلفهٔ بنیادین زبان یعنی نحو (Syntax) و معناشناسی (Semantics) بررسی میشود. سپس مفهوم دستور زبان مستقل از متن (Context-Free Grammar) معرفی میگردد که امکان نمایش ساختار یک جمله از طریق قواعد صوری را فراهم میکند. کتابخانهٔ nltk نمونهای از ابزارهایی است که برای تحلیل نحوی و ساخت درختهای تجزیه مورد استفاده قرار میگیرد.
- در ادامه، درس به الگوهای آماری زبان میپردازد. n-gramها به عنوان توالیهای پرکاربردی از واژهها یا حروف معرفی میشوند که میتوانند احتمال رخداد واژهٔ بعدی را پیشبینی کنند. سپس اهمیت توکنسازی (Tokenization) توضیح داده میشود که نخستین گام در بیشتر پردازشهای زبانی است.
- پس از آن، مدلهای زبانی مبتنی بر مارکوف مطرح میشوند که میتوانند با تکیه بر احتمال رخداد توالیهای کوتاه، جملات جدید تولید کنند. هرچند این مدلها قادرند خروجیهایی شبیه زبان طبیعی ایجاد کنند، اما فاقد درک معناییاند.
آموزش هوش مصنوعی
- سپس درس به مدل کیسهٔ واژگان (Bag-of-Words) و کاربرد آن در تحلیل احساسات میپردازد. روش بیز ساده (Naive Bayes) معرفی میشود که با فرض استقلال سادهسازانهٔ واژهها، احتمال مثبت یا منفی بودن یک متن را محاسبه میکند. مسئلهٔ صفر بودن احتمالها و راهکار هموارسازی لاپلاس نیز بررسی میشود.
- در بخش بعد، موضوع نمایش عددی واژهها مطرح میشود. ابتدا محدودیتهای نمایش تکداغ (One-Hot) بررسی میشود و سپس نمایش توزیعی (Distributed Representation) توضیح داده میشود؛ نمایشی که شباهت معنایی واژهها را نیز حفظ میکند. این مفهوم زمینهساز معرفی الگوریتم word2vec است که با یادگیری بردارهای معنایی، توانایی کشف شباهتها و روابط معنایی میان واژهها را به هوش مصنوعی میدهد.
- در پایان، درس به شبکههای عصبی پردازش زبان میرسد. محدودیتهای شبکههای بازگشتی مطرح شده و نقش مکانیسم توجه (Attention) در تمرکز بر بخشهای مهم جمله توضیح داده میشود. نهایتاً، ساختار ترنسفورمر (Transformer) معرفی میشود که با بهرهگیری از توجه خود-بازگشتی و پردازش موازی، بنیان بسیاری از مدلهای زبانی مدرن را تشکیل میدهد.
قابل به ذکر است نرم افزار Danix یک سیستم بر پایه هوش مصنوعی می باشد و از متدهای روز دنیا جهت آنالیز اطلاعات سازمان استفاده می کند شما می توانید اطلاعات بیشتر را در همین سایت مشاهده نمایید.
