

هوش مصنوعی CS50 s4
دوره هوش مصنوعی CS50 s4
آموزش هوش مصنوعی
دوره کامل آموزش هوش مصنوعی بر مبنای دوره CS5 دانشگاه هاروارد به عنوان معتبرترین و جامع ترین دوره آموزش مقدماتی و مفهومی هوش مصنوعی شناخته می شود.
این دوره به بررسی دقیق و عمیق مباحث هوش مصنوعی به صورت پایه ای می پردازد و شامل 7 بخش میباشد .جهت دسترسی به سایر دوره ها می توانید از لینک های زیر استفاده نمایید.
و برای مشاهده لیست تمام دوره ها به بخش مقالات مراجه نمایید.
CS50’s Introduction to Artificial Intelligence with Python
Danix Ai
فهرست :
یادگیری ماشین
- تعریف یادگیری ماشین
- انواع یادگیری: نظارتشده، بدون نظارت، تقویتی
یادگیری نظارتشده (Supervised Learning)
- تعریف و کاربرد
- مثال بارش و تابع فرضیه
- نمایش دادهها در فضای ویژگیها
- طبقهبندی
- نزدیکترین همسایه و k-NN
- پرسپترون
- تابع تصمیم و قوانین یادگیری
- محدودیت پرسپترون
- رگرسیون لجستیک
- ماشین بردار پشتیبان (SVM)
- مرز تصمیم و حاشیه
- جداکنندهٔ با بیشترین حاشیه
- مدلهای غیرخطی و کرنلها
رگرسیون (Regression)
- تعریف و تفاوت با طبقهبندی
- مثال درآمد تبلیغات
- تابع فرضیه در رگرسیون
توابع زیان (Loss Functions)
- تابع زیان صفر و یک
- L₁ و L₂
- نقش توابع زیان
- بیشبرازش
منظمسازی (Regularization)
- علت استفاده
- نقش λ
- تابع هزینهٔ منظمشده
اعتبارسنجی مدل (Model Validation)
- روش Holdout
- روش k-Fold
کتابخانه scikit-learn
- معرفی
- مثال تشخیص اسکناس جعلی
- آموزش و آزمون مدل
یادگیری تقویتی (Reinforcement Learning)
- عامل، حالت، عمل، پاداش
- مثال روبات و محیط
فرآیندهای تصمیمگیری مارکوف (MDP)
- مدل انتقال
- تابع پاداش
یادگیری Q (Q-Learning)
- تعریف Q
- الگوریتم بهروزرسانی
- ضریب یادگیری
- گاما و پاداش آینده
- سیاست ε-حریصانه
یادگیری مبتنی بر اپیزود
- مثال بازی Nim
- یادگیری از طریق اجرای هزاران بازی
تقریب تابع (Function Approximation)
- ضرورت در مسائل بزرگ
- کاربرد در بازیهای پیچیده
یادگیری بدون نظارت (Unsupervised Learning)
- تعریف و کاربردها
- مثالهای بیبرچسب
خوشهبندی (Clustering)
- کاربردها
خوشهبندی k-means
- انتخاب مراکز اولیه
- انتساب نقاط به مراکز
- جابهجایی مراکز و رسیدن به تعادل
مقدمه:
یادگیری ماشین یکی از ستونهای بنیادین هوش مصنوعی مدرن است؛ حوزهای که در آن رایانهها میآموزند چگونه بر اساس دادهها تصمیمگیری کنند، الگوها را تشخیص دهند و رفتارهای هوشمندانه از خود نشان دهند. در این جلسه، با مفاهیم اصلی یادگیری ماشین آشنا میشویم و بررسی میکنیم که چگونه میتوان مدلهایی ساخت که از تجربه آموخته و عملکرد خود را بهتدریج بهبود میبخشند.
موضوعات این فصل از یادگیری نظارتشده و روشهایی مانند نزدیکترین همسایه، پرسپترون، رگرسیون لجستیک و ماشین بردار پشتیبان آغاز میشود و سپس به مباحث مهمی چون توابع زیان، منظمسازی، و اعتبارسنجی مدل میرسد؛ مفاهیمی که برای ساخت مدلهای قابلاعتماد و پایدار ضروریاند.
در ادامه، وارد دنیای یادگیری تقویتی میشویم؛ جایی که عاملها از طریق آزمون و خطا راهبردهای بهینه را میآموزند و الگوریتمهایی مانند یادگیری Q نقش محوری دارند. سپس با یادگیری بدون نظارت و روشهایی همچون خوشهبندی آشنا میشویم که به کشف ساختارهای پنهان در دادهها کمک میکنند.
این فصل تلاش میکند تصویری جامع از اصول یادگیری ماشین ارائه دهد و ابزارهای مفهومی لازم برای درک عمیقتر الگوریتمها و کاربردهای آنها را فراهم سازد. نتیجهٔ این مسیر، شناختی روشنتر از چگونگی یادگیری ماشینها از دادهها و تصمیمگیری هوشمندانه آنهاست؛ دانشی که بنیان بسیاری از سامانههای هوشمند امروزی را تشکیل میدهد.
یادگیری ماشین
یادگیری ماشین به جای دستورالعملهای صریح، دادهها را در اختیار رایانه قرار میدهد. با استفاده از این دادهها، رایانه الگوها را تشخیص میدهد و قادر میشود وظایف را به صورت مستقل انجام دهد.
یادگیری نظارتشده
یادگیری نظارتشده وظیفهای است که در آن رایانه یک تابع را بر اساس مجموعهای از دادههای جفتهای ورودی-خروجی میآموزد که ورودیها را به خروجیها نگاشت میکند،.
وظایف متعددی زیرمجموعهی یادگیری نظارتشده هستند و یکی از آنها طبقهبندی است. در این وظیفه، تابع یک ورودی را به یک خروجی گسسته نگاشت میکند. برای مثال، با داشتن اطلاعاتی دربارهی رطوبت و فشار هوا در یک روز خاص (ورودی)، رایانه تصمیم میگیرد که آیا در آن روز باران خواهد بارید یا خیر (خروجی). رایانه این کار را پس از آموزش بر روی مجموعه دادهای انجام میدهد که شامل روزهای متعددی است که در آنها رطوبت و فشار هوا به بارش یا عدم بارش نگاشت شدهاند.
هوش مصنوعی CS50 s4
احتمالاً این تابع تحت تأثیر متغیرهای دیگری قرار دارد که ما به آنها دسترسی نداریم. هدف ما ایجاد تابعی به نام h(humidity, pressure) است که بتواند رفتار تابع f را تقریب بزند.
چنین وظیفهای را میتوان با ترسیم روزها در ابعاد رطوبت و باران (ورودی) تجسم کرد؛ به این صورت که هر نقطه دادهای که در آن روز باران باریده است به رنگ آبی و هر نقطهای که باران نباریده است به رنگ قرمز نمایش داده شود (خروجی). نقطهی سفید تنها ورودی را دارد و رایانه باید خروجی آن را مشخص کند.
فرض کن میخواهیم بفهمیم آیا در یک روز باران میبارد یا نه. در واقع یک تابع پنهان در طبیعت وجود دارد که بر اساس رطوبت و فشار هوا تصمیم میگیرد: «باران» یا «بدون باران». این تابع واقعی را نمیبینیم و حتی میدانیم که عوامل دیگری هم روی آن اثر دارند که ما به آنها دسترسی نداریم.
کاری که ما میکنیم این است که یک تابع تقریبی بسازیم. یعنی تابعی مثل h(humidity, pressure)
که بتواند رفتار آن تابع پنهان f را تقلید کند.
برای درک بهتر، تصور کن یک نمودار داریم:
- محور افقی: رطوبت
- محور عمودی: فشار یا وضعیت باران
هر روز را به صورت یک نقطه روی این نمودار میگذاریم:
- اگر آن روز باران باریده باشد، نقطه را آبی رنگ میکنیم.
- اگر باران نباریده باشد، نقطه را قرمز رنگ میکنیم.
حالا یک نقطهی سفید داریم که فقط اطلاعات ورودی (رطوبت و فشار) را دارد، ولی خروجیاش (باران یا بدون باران) مشخص نیست. وظیفهی رایانه این است که با یادگیری از نقاط قبلی، رنگ درست را برای این نقطهی سفید پیدا کند.
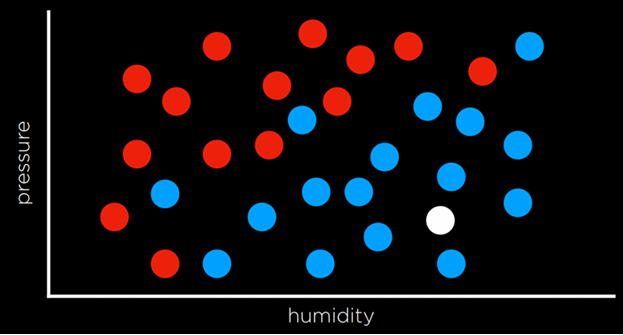
طبقهبندی نزدیکترین همسایه (Nearest-Neighbor Classification)
یک روش برای حل چنین وظیفهای این است که متغیر مورد نظر را برابر با مقدار نزدیکترین مشاهده قرار دهیم. برای مثال، نقطهی سفید روی نمودار بالا آبی رنگ میشود، چون نزدیکترین نقطهی مشاهدهشده به آن آبی است. این روش گاهی خوب عمل میکند، اما اگر به نمودار زیر نگاه کنیم، متوجه میشویم همیشه نتیجهی درستی نمیدهد.
این روش یکی از سادهترین الگوریتمهای یادگیری ماشین در حوزهی یادگیری نظارتشده است.
ایدهی اصلی آن بسیار شهودی است:
- هر دادهی جدید (مثل همان نقطهی سفید روی نمودار) بر اساس نزدیکترین دادههای موجود در مجموعهی آموزشی دستهبندی میشود.
- اگر نزدیکترین نقطهی مشاهدهشده آبی باشد (باران)، نقطهی جدید هم آبی در نظر گرفته میشود. اگر قرمز باشد (بدون باران)، نقطهی جدید قرمز خواهد شد.
- در حالت کلی، میتوان بیش از یک همسایه را در نظر گرفت (مثلاً 3 یا 5 همسایهی نزدیکتر) و سپس با رأیگیری اکثریت تصمیم گرفت که خروجی چه باشد.
- ویژگیها
- سادگی: نیاز به فرمول پیچیده ندارد، فقط فاصلهها محاسبه میشوند.
- انعطافپذیری: میتواند برای انواع دادهها استفاده شود.
- وابستگی به دادهها: کیفیت نتایج کاملاً به کیفیت و توزیع دادههای آموزشی بستگی دارد.
مثال ساده
فرض کن میخواهیم پیشبینی کنیم آیا یک روز بارانی خواهد بود یا نه. اگر نقطهی سفید (روز جدید) نزدیکترین همسایهاش روزی باشد که بارانی بوده، آن را هم بارانی در نظر میگیریم.
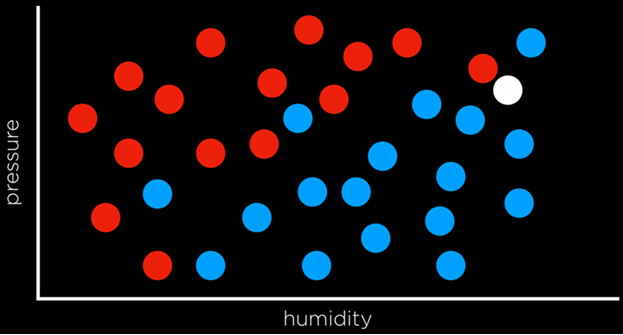
با دنبال کردن همان استراتژی، نقطهی سفید باید قرمز رنگ شود، زیرا نزدیکترین مشاهده به آن قرمز است. با این حال، اگر به تصویر کلی نگاه کنیم، به نظر میرسد بیشتر مشاهدات اطراف آن آبی هستند، که این شهود را به ما میدهد که آبی پیشبینی بهتری در این حالت است، حتی اگر نزدیکترین مشاهده قرمز باشد.
یک راه برای رفع محدودیتهای طبقهبندی نزدیکترین همسایه، استفاده از طبقهبندی k-نزدیکترین همسایهها است؛ جایی که نقطه بر اساس رایجترین رنگ در میان k همسایهی نزدیکتر رنگآمیزی میشود. انتخاب مقدار k بر عهدهی برنامهنویس است. برای مثال، با استفاده از طبقهبندی 3-نزدیکترین همسایه، نقطهی سفید بالا آبی رنگ خواهد شد، که به طور شهودی تصمیم بهتری به نظر میرسد.
هوش مصنوعی CS50 s4
یکی از معایب طبقهبندی k-نزدیکترین همسایه این است که در رویکرد ساده، الگوریتم باید فاصلهی هر نقطه را با نقطهی مورد نظر محاسبه کند، که از نظر محاسباتی هزینهبر است. این فرآیند را میتوان با استفاده از ساختارهای دادهای که امکان یافتن همسایهها را سریعتر فراهم میکنند یا با حذف مشاهدات غیرمرتبط، سرعت بخشید.
یادگیری پرسپترون راه دیگر برای حل مسئلهی طبقهبندی، در مقابل استراتژی نزدیکترین همسایه، این است که به دادهها به صورت کلی نگاه کنیم و سعی کنیم یک مرز تصمیمگیری ایجاد کنیم. در دادههای دوبعدی، میتوان خطی بین دو نوع مشاهده رسم کرد. هر نقطهی دادهای جدید بر اساس سمتی از خط که روی آن قرار میگیرد، طبقهبندی خواهد شد.
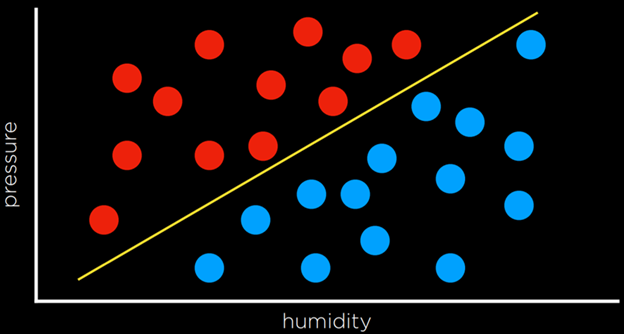
عیب این رویکرد آن است که دادهها آشفته هستند و به ندرت میتوان خطی کشید که کلاسها را بدون هیچ اشتباهی به دو دسته تقسیم کند. اغلب مجبور میشویم مصالحه کنیم و مرزی رسم کنیم که بیشتر مشاهدات را به درستی جدا کند، اما همچنان گاهی آنها را به اشتباه طبقهبندی خواهد کرد.
یک تابع فرضیه
ℎ(𝑥1,𝑥2)
در نظر گرفته میشود که خروجی آن پیشبینی میکند آیا در آن روز باران خواهد بارید یا خیر. این کار را با بررسی اینکه مشاهده در کدام سمت مرز تصمیم قرار میگیرد انجام میدهد.
بهصورت رسمی، این تابع هر یک از ورودیها را با وزنی ضرب کرده و یک ثابت به آن اضافه میکند، که در نهایت به یک معادلهی خطی به شکل زیر ختم میشود:
ℎ(𝑥1,𝑥2)=𝑤1𝑥1+𝑤2𝑥2+𝑏
در اینجا:
𝑥1 و 𝑥2
ورودیها هستند (مثلاً رطوبت و فشار هوا).
𝑤1 و 𝑤2
وزنهایی هستند که اهمیت هر ورودی را مشخص میکنند.
𝑏 یک ثابت (bias) است که به معادله اضافه میشود.
اغلب، متغیر خروجی به صورت ۱ و ۰ کدگذاری میشود؛ به این صورت که اگر مقدار معادله بیشتر از صفر باشد، خروجی برابر با ۱ (باران) خواهد بود، و در غیر این صورت برابر با ۰ (بدون باران).
وزنها و مقادیر به صورت بردارها نمایش داده میشوند؛ بردارها دنبالهای از اعداد هستند (که میتوان آنها را در لیست یا تاپل در پایتون ذخیره کرد). ما یک بردار وزن تولید میکنیم:
𝑤=(𝑤0,𝑤1,𝑤2)
و هدف الگوریتم یادگیری ماشین این است که به بهترین بردار وزن برسد. همچنین یک بردار ورودی تولید میکنیم:
x = (1, x1, x2)
سپس ضرب داخلی (dot product) این دو بردار را محاسبه میکنیم. یعنی هر مقدار در یک بردار را در مقدار متناظر در بردار دیگر ضرب کرده و جمع میکنیم،
که همان عبارت زیر به دست میآید:
w0 + w1x1 + w2x2
عدد اول در بردار ورودی برابر با ۱ است، زیرا وقتی در (w_{0}) ضرب میشود، میخواهیم آن را به صورت یک ثابت نگه داریم.
بنابراین میتوانیم تابع فرضیهی خود را به شکل زیر نمایش دهیم:
h(x) = w .x = w0 + w1x1 + w2x2
این همان تابع خطی پرسپترون است که تصمیم میگیرد نقطهی جدید (مثلاً یک روز با رطوبت و فشار مشخص) در کدام دسته قرار بگیرد: باران یا بدون باران.
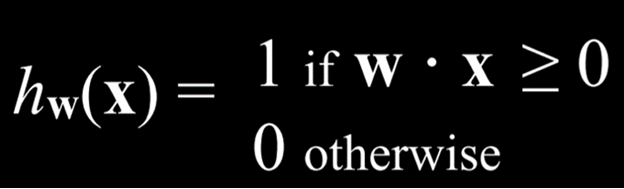
# تعریف بردار وزن
w = [0.5, 1.2, -0.8] # w0, w1, w2
# تعریف بردار ورودی
x = [1, 0.7, 0.3] # 1, x1, x2
# محاسبه ضرب داخلی (dot product)
h = sum(w[i] * x[i] for i in range(len(w)))
# تصمیمگیری بر اساس مقدار h
output = 1 if h > 0 else 0
print("Hypothesis value:", h)
print("Prediction (Rain=1, No Rain=0):", output
از آنجا که هدف الگوریتم یافتن بهترین بردار وزن است، زمانی که الگوریتم با دادههای جدید روبهرو میشود، وزنهای فعلی را بهروزرسانی میکند. این کار با استفاده از قاعدهی یادگیری پرسپترون (Perceptron Learning Rule) انجام میشود.
هوش مصنوعی CS50 s4
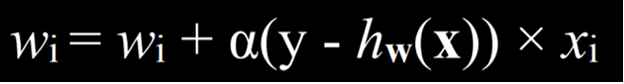
نکتهی مهم این قانون آن است که برای هر نقطهی داده، وزنها را تنظیم میکنیم تا تابع ما دقیقتر شود.
- جزئیات که به اندازهی اصل موضوع حیاتی نیستند، این است که هر وزن برابر با خودش به اضافهی مقداری در پرانتز قرار داده میشود. در اینجا y نشاندهندهی مقدار مشاهدهشده است، در حالی که تابع فرضیه نشاندهندهی مقدار تخمینی است. اگر این دو یکسان باشند، کل عبارت برابر با صفر خواهد شد و بنابراین وزن تغییر نمیکند.
- اگر کمبرآورد کرده باشیم (یعنی «بدون باران» پیشبینی کرده باشیم در حالی که «باران» مشاهده شده است)، مقدار داخل پرانتز برابر با ۱ خواهد بود و وزن به اندازهی xi ضربدر α (ضریب یادگیری) افزایش مییابد.
- اگر بیشبرآورد کرده باشیم (یعنی «باران» پیشبینی کرده باشیم در حالی که «بدون باران» مشاهده شده است)، مقدار داخل پرانتز برابر با ۱- خواهد بود و وزن به اندازهی xi ضربدر α کاهش مییابد. هرچهα بزرگتر باشد، تأثیر هر رویداد جدید بر وزنها بیشتر خواهد بود.
نتیجهی این فرآیند یک تابع آستانهای (Threshold Function) است که وقتی مقدار تخمینی از یک آستانه عبور کند، خروجی از ۰ به ۱ تغییر میکند.
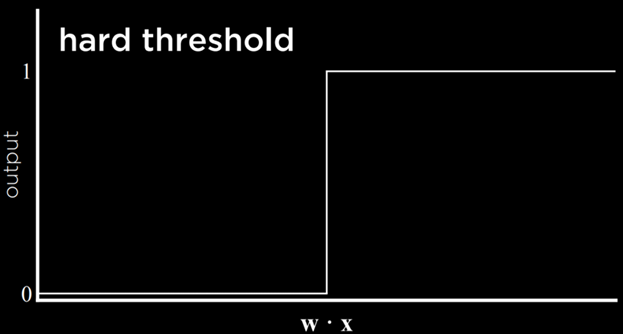
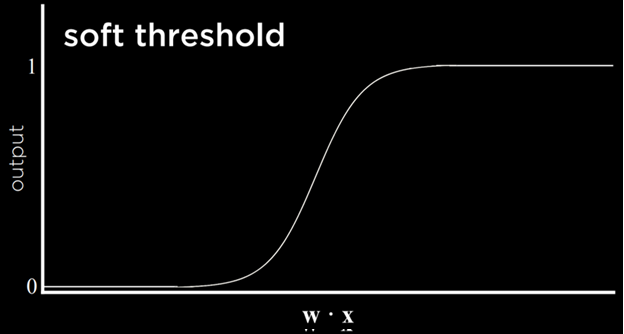
مشکل این نوع تابع آن است که نمیتواند عدم قطعیت را بیان کند، زیرا تنها میتواند برابر با ۰ یا ۱ باشد. این تابع از یک آستانهی سخت استفاده میکند. راهی برای دور زدن این مشکل استفاده از تابع لجستیک (Logistic Function) است که از یک آستانهی نرم بهره میبرد. تابع لجستیک میتواند عددی حقیقی بین ۰ و ۱ تولید کند که میزان اعتماد به تخمین را نشان میدهد. هرچه مقدار به ۱ نزدیکتر باشد، احتمال بارش باران بیشتر است.
این همان چیزی است که در رگرسیون لجستیک یا مدلهای احتمالی استفاده میشود؛ به جای یک تصمیم قطعی (۰ یا ۱)، خروجی به صورت یک احتمال بیان میشود. مثلاً اگر خروجی ۰.85 باشد، یعنی مدل با ۸۵٪ اطمینان پیشبینی میکند که باران خواهد بارید.
علاوه بر روشهای نزدیکترین همسایه و رگرسیون خطی، رویکرد دیگری برای طبقهبندی وجود دارد که ماشین بردار پشتیبان (Support Vector Machine) نام دارد. این روش از یک بردار اضافی (بردار پشتیبان) در نزدیکی مرز تصمیم استفاده میکند تا بهترین تصمیم را هنگام جداسازی دادهها بگیرد.

به مثال زیر توجه کنید:
تمام مرزهای تصمیمگیری دادهها را بدون خطا جدا میکنند. اما آیا همهی آنها به یک اندازه خوب هستند؟ دو مرز تصمیم سمت چپ بسیار نزدیک به برخی مشاهدات هستند. این بدان معناست که یک نقطهی دادهی جدید که فقط کمی با یک گروه تفاوت دارد، ممکن است به اشتباه در گروه دیگر طبقهبندی شود. در مقابل، مرز تصمیم سمت راست بیشترین فاصله را از هر دو گروه حفظ میکند و بنابراین بیشترین آزادی عمل را برای تغییرات درون دادهها فراهم میآورد. این نوع مرز، که تا حد امکان از دو گروهی که جدا میکند فاصله دارد، جداکنندهی با بیشترین حاشیه (Maximum Margin Separator) نامیده میشود.
Maximum Margin Separator
مزیت دیگر ماشینهای بردار پشتیبان این است که میتوانند مرزهای تصمیمگیری را در بیش از دو بُعد نمایش دهند، و همچنین مرزهای تصمیم غیرخطی را نیز مدلسازی کنند، مانند مثال زیر.
هوش مصنوعی CS50 s4
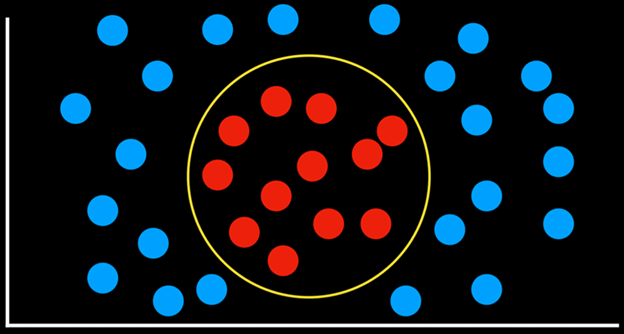
این بخش در واقع توضیح میدهد که چرا SVM یکی از قدرتمندترین الگوریتمهای طبقهبندی است: چون نهتنها بهترین خط جداکننده را پیدا میکند، بلکه میتواند در فضاهای چندبُعدی و حتی غیرخطی هم کار کند.
به طور خلاصه، راههای متعددی برای پرداختن به مسائل طبقهبندی وجود دارد و هیچکدام همیشه بهتر از دیگری نیستند. هرکدام معایب خاص خود را دارند و ممکن است در شرایط خاصی مفیدتر از بقیه باشند.
این جمله در واقع جمعبندی همهی روشهایی است که مرور کردیم:
- نزدیکترین همسایه: ساده و شهودی، اما در دادههای بزرگ محاسبات سنگین دارد.
- پرسپترون و مرز خطی: سریع و قابل فهم، اما در دادههای پیچیده و غیرخطی محدودیت دارد.
- تابع لجستیک: امکان بیان عدم قطعیت و احتمال را فراهم میکند.
- ماشین بردار پشتیبان (SVM): قدرتمند در جداسازی دادهها با بیشترین حاشیه و حتی در ابعاد بالا.
رگرسیون یک وظیفهی یادگیری نظارتشده است که در آن یک تابع، نقطهی ورودی را به یک مقدار پیوسته (یک عدد حقیقی) نگاشت میکند. این موضوع با طبقهبندی تفاوت دارد، زیرا در مسائل طبقهبندی، ورودی به مقادیر گسسته نگاشت میشود (مثلاً «باران» یا «بدون باران»)
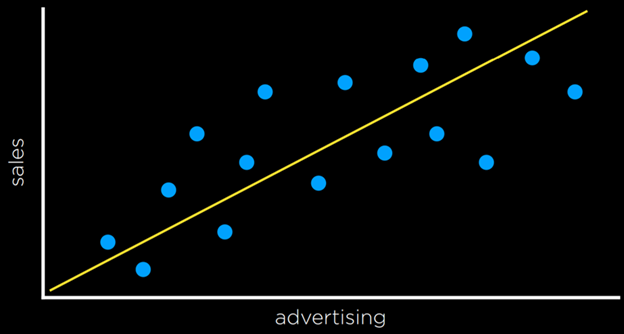
برای مثال، یک شرکت ممکن است از رگرسیون برای پاسخ به این پرسش استفاده کند که هزینهی صرفشده برای تبلیغات چگونه درآمد حاصل از فروش را پیشبینی میکند. در این حالت، یک تابع مشاهدهشده
f(advertising)
درآمد مشاهدهشده را پس از صرف مقداری پول در تبلیغات نشان میدهد (توجه داشته باشید که این تابع میتواند بیش از یک متغیر ورودی داشته باشد). این دادهها همان چیزی هستند که با آنها شروع میکنیم.
با استفاده از این دادهها، میخواهیم یک تابع فرضیه
ℎ(advertising)
بسازیم که سعی کند رفتار تابع 𝑓 را تقریب بزند. تابع ℎ
یک خط تولید میکند که هدف آن جدا کردن انواع مشاهدات نیست، بلکه پیشبینی مقدار خروجی بر اساس ورودی است.
این توضیح در واقع تفاوت اصلی رگرسیون و طبقهبندی را نشان میدهد:
طبقهبندی → خروجی گسسته (۰ یا ۱، باران یا بدون باران).
رگرسیون → خروجی پیوسته (اعداد حقیقی مثل درآمد، دما، وزن).
میخواهی من همین مفهوم را با یک نمودار ساده آموزشی (نقاط داده + خط رگرسیون) برایت توضیح بدهم تا دیداری شود؟
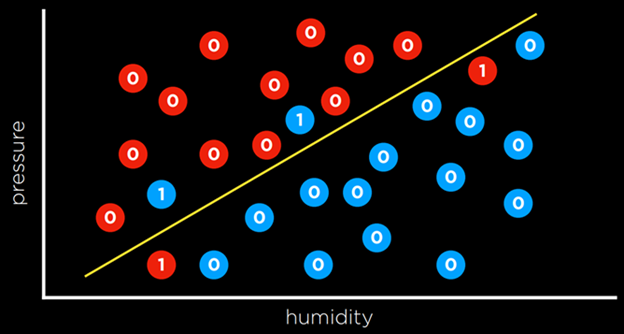
توابع زیان (Loss Functions) روشی برای کمّیسازی میزان «فایده از دسترفته» در هر یک از قواعد تصمیمگیری هستند. هرچه پیشبینی نادرستتر باشد، مقدار زیان بزرگتر میشود.
برای مسائل طبقهبندی، میتوانیم از تابع زیان صفر و یک)0–1 Loss Function (استفاده کنیم.

به بیان دیگر، این تابع زمانی مقدار میگیرد که پیشبینی نادرست باشد و زمانی مقدار نمیگیرد که پیشبینی درست باشد (یعنی وقتی مقدار مشاهدهشده و مقدار پیشبینیشده با هم تطابق دارند).
هوش مصنوعی CS50 s4
در مثال بالا، روزهایی که مقدار ۰ گرفتهاند روزهایی هستند که وضعیت آبوهوا را درست پیشبینی کردهایم (روزهای بارانی زیر خط قرار دارند و روزهای غیر بارانی بالای خط). اما روزهایی که باران نباریده ولی زیر خط قرار گرفتهاند، و روزهایی که باران باریده ولی بالای خط قرار گرفتهاند، همان مواردی هستند که پیشبینی ما اشتباه بوده است. به هر یک از این موارد مقدار ۱ میدهیم و آنها را با هم جمع میکنیم تا یک برآورد تجربی از میزان خطادار بودن مرز تصمیمگیری خود به دست آوریم.
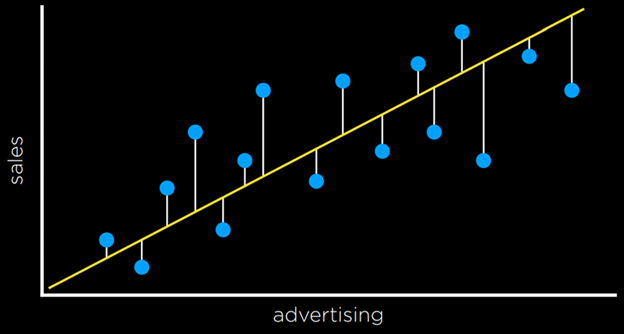
توابع زیان L₁ و L₂ زمانی کاربرد دارند که مقدار پیوستهای را پیشبینی میکنیم. در این حالت، هدف ما این است که برای هر پیشبینی اندازهگیری کنیم که پیشبینی تا چه حد با مقدار مشاهدهشده تفاوت داشته است. این کار را با گرفتن مقدار مطلق یا مقدار مربعیِ تفاضلِ مقدار مشاهدهشده و مقدار پیشبینیشده انجام میدهیم (یعنی اینکه پیشبینی چقدر با مقدار واقعی فاصله داشته است).

هر فرد میتواند تابع زیانی را انتخاب کند که بهترین خدمت را به هدف او میکند. تابع L₂ به دلیل مجذور کردن اختلاف، مقدارهای دورافتاده (outliers) را شدیدتر جریمه میکند. L₁ را میتوان با جمع کردن فاصلهی هر نقطهی مشاهدهشده تا نقطهی متناظر روی خط رگرسیون تجسم کرد.
هوش مصنوعی CS50 s4
بیشبرازش (Overfitting) زمانی رخ میدهد که یک مدل آنقدر خوب روی دادههای آموزش برازش میشود که دیگر نمیتواند روی مجموعهدادههای جدید تعمیم پیدا کند. از این لحاظ، توابع زیان یک شمشیر دولبه هستند. در دو مثال زیر، تابع زیان بهگونهای کمینه شده است که مقدار زیان برابر با صفر است. با این حال، بعید است که مدل بتواند دادههای جدید را بهخوبی برازش کند.
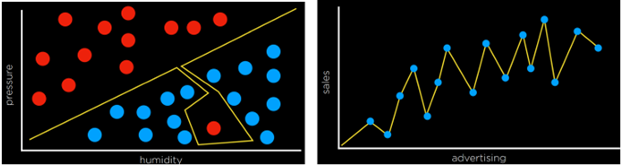
برای مثال، در نمودار سمت چپ، نقطهای که در کنار نقطهٔ قرمز در پایین تصویر قرار دارد، به احتمال زیاد بارانی (آبی) است. اما با مدل بیشبرازششده، این نقطه بهعنوان بدون باران (قرمز) طبقهبندی خواهد شد.
منظمسازی (Regularization)
منظمسازی فرایندی است که در آن فرضیههای پیچیدهتر را جریمه میکنیم تا فرضیههای سادهتر و کلیتر ترجیح داده شوند. ما از منظمسازی برای جلوگیری از بیشبرازش استفاده میکنیم.
در منظمسازی، هزینهٔ تابع فرضیه h را با جمع کردن زیان (Loss) آن و معیاری از میزان پیچیدگی آن تخمین میزنیم
λ (لامبدا) یک ثابت است که میتوانیم از آن برای تنظیم شدت جریمهٔ پیچیدگی در تابع هزینه استفاده کنیم. هرچه مقدار λ بیشتر باشد، پیچیدگی پرهزینهتر خواهد بود.
یکی از روشها برای بررسی اینکه آیا مدل بیشبرازش شده است، استفاده از اعتبارسنجی متقاطع Holdout است. در این روش، تمام دادهها را به دو بخش تقسیم میکنیم: یک مجموعه آموزشی و یک مجموعه آزمون. الگوریتم یادگیری را روی مجموعه آموزشی اجرا میکنیم و سپس میبینیم چقدر دادههای مجموعه آزمون را درست پیشبینی میکند. ایده این است که با آزمایش روی دادههایی که در آموزش استفاده نشدهاند، میتوانیم میزان تعمیمپذیری مدل را بسنجیم.
عیب اعتبارسنجی Holdout این است که مدل تنها روی نیمی از دادهها آموزش میبیند، زیرا نیم دیگر برای ارزیابی نگه داشته میشود. یک راه حل برای این مشکل استفاده از اعتبارسنجی متقاطع k-Fold است. در این روش، دادهها به k بخش تقسیم میشوند. آموزش را k بار اجرا میکنیم، هر بار یکی از بخشها را کنار گذاشته و بهعنوان مجموعه آزمون استفاده میکنیم. در نهایت k ارزیابی متفاوت از مدل به دست میآوریم که میتوانیم میانگین آنها را بگیریم و بدون از دست دادن دادهها، برآوردی از میزان تعمیمپذیری مدل به دست آوریم.
scikit-learn( کتابخانه ای در پایتون):
همانطور که اغلب در پایتون مشاهده میشود، کتابخانههای متعددی وجود دارند که به ما امکان میدهند الگوریتمهای یادگیری ماشین را بهراحتی استفاده کنیم. یکی از این کتابخانهها scikit-learn است.
بهعنوان مثال، ما قصد داریم از یک مجموعه داده اسکناسهای جعلی (counterfeit banknotes) استفاده کنیم.
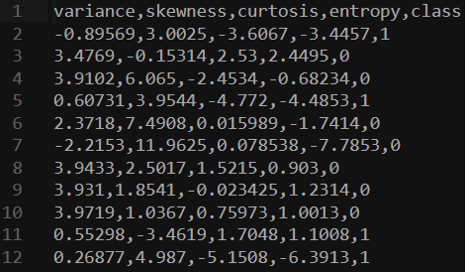
چهار ستون اول دادههایی هستند که میتوانیم از آنها برای پیشبینی اینکه آیا یک اسکناس اصلی است یا جعلی استفاده کنیم. این دادهها توسط انسان فراهم شده و بهصورت ۰ و ۱ کدگذاری شدهاند. اکنون میتوانیم مدل خود را روی این مجموعه داده آموزش دهیم و ببینیم آیا میتوانیم پیشبینی کنیم که اسکناسهای جدید اصلی هستند یا خیر.
import csv
import random
from sklearn import svm
from sklearn.linear_model import Perceptron
from sklearn.naive_bayes import GaussianNB
from sklearn.neighbors import KNeighborsClassifier
# model = KNeighborsClassifier(n_neighbors=1)
# model = svm.SVC()
model = Perceptron()
دوره هوش مصنوعی
توجه داشته باشید که پس از وارد کردن کتابخانهها، میتوانیم انتخاب کنیم کدام مدل را استفاده کنیم. بقیهٔ کد بدون تغییر باقی میماند.
SVC مخفف(Support Vector Classifier) است که بهعنوان ماشین بردار پشتیبان یا SVM شناخته میشود.
KNeighborsClassifier از استراتژی k-neighbors استفاده میکند و بهعنوان ورودی نیاز دارد تا مشخص کنیم که تعداد همسایههایی که باید در نظر گرفته شوند چقدر باشد.
این نسخهٔ دستی اجرای الگوریتم را میتوان در کد منبع این درس تحت نام banknotes0.py یافت. از آنجا که این الگوریتم اغلب به همین شکل استفاده میشود، scikit-learn توابع اضافیای دارد که کد را، حتی کوتاهتر و آسانتر برای استفاده میکند و این نسخه را میتوان تحت نام banknotes1.py یافت.
یادگیری تقویتی (Reinforcement Learning)
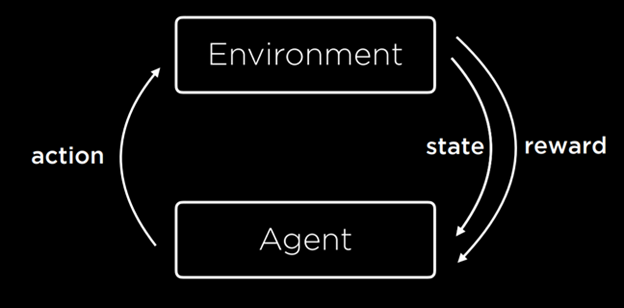
یادگیری تقویتی رویکرد دیگری در یادگیری ماشین است، که در آن پس از هر عمل، عامل (agent) بازخورد دریافت میکند به صورت پاداش یا تنبیه (یک مقدار عددی مثبت یا منفی).
دوره هوش مصنوعی CS50 s4
فرآیند یادگیری با این شروع میشود که محیط یک حالت (state) به عامل (agent) ارائه میدهد. سپس، عامل یک عمل (action) روی آن حالت انجام میدهد. بر اساس این عمل، محیط یک حالت جدید و یک پاداش (reward) به عامل بازمیگرداند. این پاداش میتواند مثبت باشد و احتمال تکرار آن رفتار در آینده را افزایش دهد، یا منفی باشد (یعنی تنبیه) و احتمال تکرار آن رفتار در آینده را کاهش دهد.
این نوع الگوریتم میتواند برای آموزش رباتهای راهرونده استفاده شود، برای مثال، هر قدم درست یک عدد مثبت (پاداش) و هر سقوط یک عدد منفی (تنبیه) بازمیگرداند.
فرآیندهای تصمیمگیری مارکوف (Markov Decision Processes)
یادگیری تقویتی را میتوان بهعنوان یک فرآیند تصمیمگیری مارکوف (Markov Decision Process) در نظر گرفت که دارای ویژگیهای زیر است:
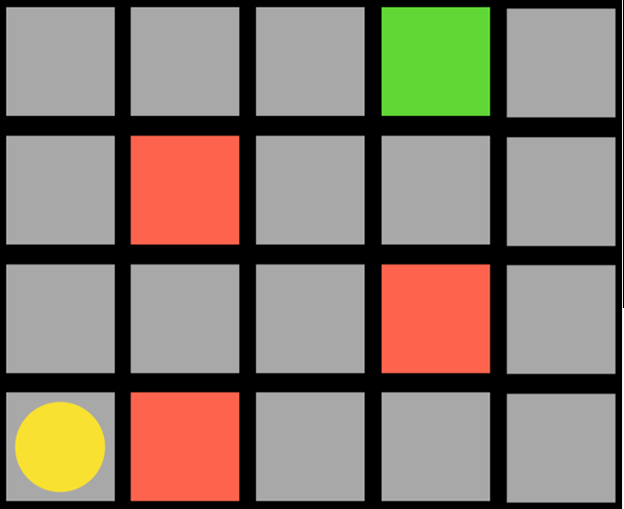
عامل (agent) همان دایرهٔ زرد است و باید به مربع سبز برسد در حالی که از مربعهای قرمز اجتناب کند. هر مربع در این وظیفه یک حالت (state) محسوب میشود. حرکت به بالا، پایین یا کنارها یک عمل (action) است.
دوره هوش مصنوعی CS50 s4
مدل انتقال (transition model) حالت جدید را پس از انجام یک عمل به ما میدهد و تابع پاداش (reward function) نوع بازخوردی که عامل دریافت میکند را مشخص میکند. برای مثال، اگر عامل تصمیم بگیرد به سمت راست برود، روی یک مربع قرمز میافتد و بازخورد منفی دریافت میکند. این بدان معناست که عامل یاد میگیرد که وقتی در حالت مربع پایین-چپ است، باید از رفتن به راست اجتناب کند.
به این ترتیب، عامل شروع به کاوش فضا میکند و میآموزد کدام جفتهای حالت-عمل را باید اجتناب کند. الگوریتم میتواند احتمالی (probabilistic) باشد و بسته به احتمالهایی که بر اساس پاداش افزایش یا کاهش مییابند، اقدامهای متفاوتی را در حالتهای مختلف انتخاب کند. زمانی که عامل به مربع سبز برسد، پاداش مثبت دریافت میکند و یاد میگیرد که عمل انجامشده در حالت قبلی مطلوب بوده است.
یادگیری Q (Q-Learning)
Q-Learning یکی از مدلهای یادگیری تقویتی است که در آن تابع Q(s,a) تخمینی از ارزش انجام عمل a در حالت s ارائه میدهد.
مدل با این فرض شروع میشود که تمام مقادیر تخمینی برابر با صفر هستند ( Q(s,a)=0 برای همه s و a ) وقتی عملی انجام میشود و پاداش دریافت میشود، تابع دو کار انجام میدهد:
- مقدار Q(s,a) را بر اساس پاداش فعلی و پاداشهای مورد انتظار آینده تخمین میزند.
- Q(s,a) را بهروزرسانی میکند تا هم تخمین قدیمی و هم تخمین جدید را در نظر بگیرد.
این فرآیند الگوریتمی ایجاد میکند که میتواند دانش گذشته خود را بهبود دهد بدون اینکه از صفر شروع کند.
مقدار بهروزشدهٔ Q(s,a) برابر است با مقدار قبلی Q(s,a) به اضافهٔ یک مقدار بهروزرسانی. این مقدار بهروزرسانی بهصورت اختلاف بین مقدار جدید و مقدار قدیمی تعیین میشود و در α، ضریب یادگیری (learning coefficient)، ضرب میشود.
- وقتی α = 1 باشد، تخمین جدید به سادگی مقدار قدیمی را جایگزین میکند.
- وقتی α = 0 باشد، مقدار تخمینی هرگز بهروزرسانی نمیشود.
با افزایش یا کاهش α، میتوان تعیین کرد که چقدر سریع دانش قبلی توسط تخمینهای جدید بهروزرسانی میشود.
تخمین مقدار جدید را میتوان به صورت مجموع پاداش فعلی (r) و تخمین پاداشهای آینده بیان کرد. برای بهدست آوردن تخمین پاداش آینده، حالت جدیدی که پس از آخرین عمل به دست آمده در نظر گرفته میشود و تخمین عملی که در این حالت جدید بیشترین پاداش را خواهد داشت، به آن اضافه میشود.
به این ترتیب، ما مقدار سودمندی انجام عمل a در حالت s را نه تنها بر اساس پاداش دریافتی، بلکه بر اساس سودمندی مورد انتظار گام بعدی نیز تخمین میزنیم.
مقدار تخمین پاداش آینده گاهی با ضریب γ (گاما) ظاهر میشود که تعیین میکند پاداشهای آینده چقدر اهمیت دارند.
در نهایت، به معادلهٔ زیر میرسیم:
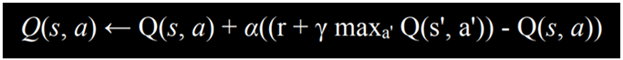
دوره هوش مصنوعی CS50 s4
یک الگوریتم تصمیمگیری حریصانه (Greedy Decision-Making) کاملاً پاداشهای تخمینی آینده را نادیده میگیرد و همیشه عمل a در حالت فعلی s را انتخاب میکند که بیشترین مقدار Q(s,a) را دارد.
این ما را به بحث موازنهٔ کاوش (Explore) و بهرهبرداری (Exploit) میرساند. یک الگوریتم حریصانه همیشه بهرهبرداری میکند و اقداماتی را انجام میدهد که قبلاً مشخص شدهاند تا نتایج خوبی بهدست آید. با این حال، همیشه همان مسیر را تا حل مسئله دنبال میکند و هیچگاه مسیر بهتری پیدا نمیکند. کاوش (Exploration) به معنای آن است که الگوریتم ممکن است مسیر قبلاً کشفنشدهای را به سمت هدف استفاده کند و در طول مسیر، راهحلهای کارآمدتری را کشف کند. برای مثال، اگر همیشه همان آهنگها را گوش دهید، میدانید از آنها لذت خواهید برد، اما هیچگاه آهنگهای جدیدی که ممکن است حتی بیشتر دوست داشته باشید را نخواهید شناخت!
برای پیادهسازی مفهوم کاوش و بهرهبرداری میتوان از الگوریتم ε (اپسیلون) حریصانه استفاده کرد. در این نوع الگوریتم، ε را برابر با فرکانس حرکت تصادفی قرار میدهیم. با احتمال 1 – ε ، الگوریتم بهترین حرکت را انتخاب میکند (بهرهبرداری) و با احتمال ε، الگوریتم یک حرکت تصادفی انجام میدهد (کاوش).
دوره هوش مصنوعی CS50 s4
روش دیگری برای آموزش یک مدل یادگیری تقویتی این است که بازخورد را نه بعد از هر حرکت، بلکه در پایان کل فرآیند ارائه دهیم. برای مثال، بازی Nim را در نظر بگیرید. در این بازی، تعداد متفاوتی اشیاء بین چند پشته تقسیم میشوند. هر بازیکن میتواند هر تعداد شیء را از یک پشته بردارد و بازیکنی که آخرین شیء را بردارد، میبازد. در چنین بازیای، یک هوش مصنوعی آموزشندیده بهصورت تصادفی بازی میکند و شکست دادن آن آسان است. برای آموزش AI، ابتدا بازی بهصورت تصادفی انجام میشود و در پایان، برای برد پاداش 1 و برای باخت پاداش -1 دریافت میکند. وقتی AI بر روی ۱۰,۰۰۰ بازی آموزش داده شود، بهقدری هوشمند میشود که شکست دادن آن دشوار است.
این روش وقتی بازی دارای چندین حالت و اقدام ممکن باشد، مانند شطرنج، بیشتر محاسباتی و دشوار میشود. محاسبهٔ ارزش تخمینی برای هر حرکت ممکن در هر حالت ممکن غیرعملی است. در این حالت، میتوان از تقریب تابع (Function Approximation) استفاده کرد که به ما امکان میدهد Q(s,a) را با استفاده از ویژگیهای دیگر تقریب بزنیم، به جای اینکه یک مقدار برای هر جفت حالت-عمل ذخیره کنیم. بنابراین، الگوریتم قادر میشود تشخیص دهد که کدام حرکتها به اندازه کافی مشابه هستند و ارزش تخمینی آنها باید مشابه باشد و از این هیوریستیک در تصمیمگیری خود استفاده کند.
یادگیری بدون نظارت (Unsupervised Learning)
در تمام مثالهایی که قبل دیدیم، مانند یادگیری نظارتشده، دادهها دارای برچسب بودند که الگوریتم میتوانست از آنها یاد بگیرد. برای مثال، وقتی الگوریتمی را آموزش دادیم تا اسکناسهای جعلی را تشخیص دهد، هر اسکناس دارای چهار متغیر با مقادیر مختلف (داده ورودی) و برچسب جعلی یا اصلی بودن (label) بود.
در یادگیری بدون نظارت، تنها دادههای ورودی موجود است و AI الگوها را در این دادهها یاد میگیرد.
خوشهبندی (Clustering)
خوشهبندی یک وظیفهٔ یادگیری بدون نظارت است که دادههای ورودی را گرفته و آنها را به گروههایی سازماندهی میکند به طوری که اشیاء مشابه در یک گروه قرار بگیرند. این روش میتواند، برای مثال، در تحقیقات ژنتیکی هنگام یافتن ژنهای مشابه، یا در بخشبندی تصویر (image segmentation) هنگام تعریف بخشهای مختلف تصویر بر اساس شباهت بین پیکسلها، استفاده شود.
خوشهبندی k-means
خوشهبندی k-means الگوریتمی است برای انجام وظیفهٔ خوشهبندی. این الگوریتم ابتدا همهٔ نقاط داده را در یک فضا نقشهبرداری میکند و سپس k مرکز خوشه را بهصورت تصادفی در فضا قرار میدهد (تعداد k را برنامهنویس مشخص میکند؛ این همان حالت اولیه است که در تصویر سمت چپ دیده میشود). هر مرکز خوشه صرفاً یک نقطه در فضا است.
سپس، هر خوشه تمام نقاطی که به مرکز آن نزدیکتر هستند تا به هر مرکز دیگر را به خود اختصاص میدهد (این حالت در تصویر وسط نشان داده شده است).
در یک فرآیند تکراری، مرکز خوشه به میانگین تمام این نقاط منتقل میشود (حالت سمت راست)، و سپس نقاط دوباره به خوشههایی اختصاص مییابند که مراکز آنها اکنون به آنها نزدیکتر هستند.
وقتی پس از تکرار این فرآیند، هر نقطه در همان خوشهای باقی بماند که قبلاً در آن بوده است، به تعادل (equilibrium) رسیدهایم و الگوریتم پایان مییابد، در نتیجه نقاط بین خوشهها تقسیم شدهاند.

دوره هوش مصنوعی CS50 s4
خلاصه مباحث:
یادگیری ماشین شاخهای از هوش مصنوعی است که در آن، بهجای ارائهٔ دستورالعملهای مستقیم، دادهها در اختیار رایانه قرار میگیرد تا با تحلیل آنها الگوها را کشف کرده و توانایی پیشبینی یا تصمیمگیری را به دست آورد. این رویکرد به مدل اجازه میدهد عملکردی فراتر از قوانین صریح برنامهنویس داشته باشد و در مواجهه با دادههای جدید نیز رفتاری هوشمندانه از خود نشان دهد.
یادگیری نظارتشده
در یادگیری نظارتشده، هدف آن است که میان ورودیها و خروجیها تابعی آموخته شود؛ تابعی که بتواند برای ورودیهای جدید نیز پیشبینیای معتبر ارائه کند. از جمله مسائل مهم در این حوزه، طبقهبندی است که در آن مدل باید خروجی گسستهای را انتخاب کند. نمونهای رایج، پیشبینی بارش با استفاده از ویژگیهایی چون رطوبت و فشار هواست. در چنین مسئلهای، تابعی واقعی در طبیعت وجود دارد که خروجی را تعیین میکند، اما ما تنها دادههای مشاهدهشده را در اختیار داریم و باید تابعی مشابه بسازیم.
روشهای اصلی در یادگیری نظارتشده
یکی از سادهترین روشها، نزدیکترین همسایه است که خروجی یک دادهٔ جدید را براساس نزدیکترین مشاهدهٔ موجود تعیین میکند. این روش اگرچه ساده و قابل فهم است، اما با دادههای پراکنده یا مرزی پیچیده بهسرعت دچار خطا میشود.
روش دیگر، پرسپترون است که با ترسیم مرزی خطی میان دو دسته داده عمل میکند. در این روش، ورودیها با وزنهایی ترکیب میشوند و با توجه به نتیجهٔ حاصل، هر داده در یک کلاس قرار میگیرد. پرسپترون پایهای برای بسیاری از مدلهای پیشرفتهتر است، هرچند محدود به مسائل خطی میباشد.
توابع زیان
برای ارزیابی کیفیت پیشبینیها از توابع زیان استفاده میشود. در مسائل طبقهبندی، زیان صفر و یک دقیقاً مشخص میکند که پیشبینی درست یا غلط بوده است. در مسائل پیوسته، از توابع L₁ (اختلاف مطلق) و L₂ (اختلاف مربعی) استفاده میشود. انتخاب تابع مناسب بر نحوهٔ رفتار مدل در برابر خطاهای کوچک و بزرگ اثر میگذارد و نقش مهمی در پایداری مدل دارد.
بیشبرازش
بیشبرازش زمانی رخ میدهد که مدل بیش از حد با دادههای آموزش سازگار شود؛ بهگونهای که کوچکترین نوسانات و نویزها را نیز تقلید کند. نتیجه، مدلی است که اگرچه روی دادههای آموزش عملکردی عالی دارد، اما در مواجهه با دادههای واقعی و جدید بهشدت ناکارآمد میشود.
منظمسازی و اعتبارسنجی
برای مقابله با بیشبرازش، از منظمسازی استفاده میشود. در این روش، علاوه بر زیان، معیار پیچیدگی مدل نیز وارد تابع هزینه میشود تا مدلهای بیشپیچیده جریمه شوند. ضریب λ شدت این جریمه را تعیین میکند.
ارزیابی میزان توانایی تعمیم مدل با روشهایی مانند اعتبارسنجی Holdout انجام میشود که در آن دادهها به دو بخش آموزش و آزمون تقسیم میشوند. روش دقیقتر k-Fold Cross Validation است که از تمام دادهها برای آموزش و ارزیابی استفاده میکند و نتیجهای پایدارتر ارائه میدهد.
کتابخانهٔ scikit-learn
scikit-learn یکی از کتابخانههای کلیدی پایتون برای پیادهسازی الگوریتمهای یادگیری ماشین است. این کتابخانه ابزارهای آمادهای برای آموزش مدلها، تقسیم داده، انتخاب ویژگی و ارزیابی ارائه میدهد. در این درس، یک مجموعهدادهٔ واقعی شامل ویژگیهای اسکناسها برای تشخیص نمونههای تقلبی مورد استفاده قرار گرفت.
یادگیری تقویتی
یادگیری تقویتی رویکردی است که در آن یک عامل با محیط تعامل میکند و براساس پاداش یا تنبیه، راهبردهای بهینه را میآموزد. این چارچوب شامل مفاهیمی چون «حالت»، «عمل» و «پاداش» است و به کمک مدلهای تصمیمگیری مانند فرایندهای تصمیمگیری مارکوف (MDP) توصیف میشود.
یکی از الگوریتمهای اصلی در این بخش، یادگیری Q است که در آن برای هر حالت و عمل، مقداری ذخیره میشود که نشان میدهد انجام آن عمل در آن حالت تا چه اندازه سودمند است. این مقادیر بهتدریج با تجربهٔ عامل و بر اساس ضرایب یادگیری و تخفیف بهروزرسانی میشوند. سیاستهایی مانند ε-حریصانه امکان ترکیب اکتشاف و بهرهبرداری را فراهم میکنند.
یادگیری بدون نظارت
در یادگیری بدون نظارت، دادهها برچسب ندارند و هدف یافتن ساختار پنهان در آنهاست. یکی از روشهای رایج در این حوزه خوشهبندی است که تلاش میکند دادههای مشابه را در یک گروه قرار دهد.
روش k-means از شناختهشدهترین الگوریتمهای خوشهبندی است. در این روش، ابتدا چند مرکز اولیه انتخاب میشود، سپس دادهها به نزدیکترین مرکز اختصاص مییابند و مراکز بر اساس میانگین نقاط بهروزرسانی میشوند. این روند تکرار میشود تا به حالتی پایدار برسد.
جمعبندی:
Lecture 4 تصویری جامع از یادگیری ماشین ارائه میکند؛ از روشهای نظارتشده و ابزارهای ارزیابی گرفته تا یادگیری تقویتی و بدون نظارت. در این درس، مهمترین مفاهیم نظری همراه با مثالهای عملی و ابزارهای اجرایی مانند scikit-learn معرفی شدهاند و مسیر روشنی برای درک عمیقتر الگوریتمها و کاربردهای آنها فراهم شده است.
