

هوش مصنوعی CS50 s3
آموزش هوش مصنوعی
دوره کامل آموزش هوش مصنوعی بر مبنای دوره CS5 دانشگاه هاروارد به عنوان معتبرترین و جامع ترین دوره آموزش مقدماتی و مفهومی هوش مصنوعی شناخته می شود.
این دوره به بررسی دقیق و عمیق مباحث هوش مصنوعی به صورت پایه ای می پردازد و شامل 7 بخش میباشد .جهت دسترسی به سایر دوره ها می توانید از لینک های زیر استفاده نمایید.
- مقالات هوش مصنوعی CS50 s0
- مقالات هوش مصنوعی CS50 s1
- مقالات هوش مصنوعی CS50 s2
- مقالات هوش مصنوعی CS50 s3
- مقالات هوش مصنوعی CS50 s4
- مقالات هوش مصنوعی CS50 s5
- آموزش هوش مصنوعی بخش آخر CS506
و برای مشاهده لیست تمام دوره ها به بخش مقالات مراجه نمایید.
CS50’s Introduction to Artificial Intelligence with Python
Danix Ai
فهرست :
مقدمهای بر بهینهسازی (Optimization)
- تعریف بهینهسازی
- کاربردهای گستردهٔ بهینهسازی در مسائل هوش مصنوعی
جستوجوی محلی (Local Search)
- مفهوم جستوجوی محلی
- مثال خانهها و بیمارستانها
- تعریف حالتها و مفهوم چیدمان
اجزای اصلی در جستوجوی محلی:
- تابع هدف (Objective Function)
- تابع هزینه (Cost Function)
- حالت فعلی (Current State)
- حالت همسایه (Neighbor State)
بالا رفتن از تپه (Hill Climbing)
- سازوکار کلی الگوریتم
- مشکلات Hill Climbing:
- بهینهٔ محلی (Local Optimum)
- دشت (Plateau)
- خطالرأس (Ridge)
انواع Hill Climbing:
- Steepest-Ascent
- Climbing با چند نقطهٔ شروع
بازپخت شبیهسازیشده (Simulated Annealing)
- ایدهٔ اصلی الگوریتم
- مفاهیم دما و احتمال پذیرش
- تفاوت با Hill Climbing
- کاربردها
مسئلهٔ فروشندهٔ دورهگرد (Traveling Salesman Problem – TSP)
- تعریف مسئله
- حالتها و حالتهای همسایه
- استفاده از جستوجوی محلی در TSP
- چالشها و راهحلهای تقریبی
برنامهریزی خطی (Linear Programming)
- تعریف معادلهٔ خطی
- اجزای برنامهریزی خطی:
- متغیرها
- تابع هزینه (Cost Function)
- محدودیتها (Constraints)
- محدودیتهای فردی متغیرها
- مثالهایی از فرم عمومی برنامهریزی خطی
هوش مصنوعی CS50 s3 مقدمه:
بهینهسازی یکی از مفاهیم بنیادین در هوش مصنوعی و علوم رایانه است. هدف اصلی در مسائل بهینهسازی، یافتن بهترین پاسخ از میان مجموعهای از پاسخهای ممکن است؛ پاسخی که بیشترین سود، کمترین هزینه یا بهترین عملکرد را فراهم کند. بسیاری از مسئلههای مهم در دنیای واقعی—from طراحی شبکهها و زمانبندی گرفته تا تخصیص منابع و تصمیمگیریهای پیچیده—در قالب یک مسئلهٔ بهینهسازی قابل تبیین هستند.
جستوجوی محلی بهعنوان یکی از رویکردهای کاربردی در حل مسائل بهینهسازی شناخته میشود. این روش با تمرکز بر یک پاسخ اولیه و بررسی تدریجی پاسخهای نزدیک به آن، تلاش میکند پاسخی بهتر بیابد. گرچه این روش تضمین نمیکند که همیشه به بهترین پاسخ جهانی برسد، اما در بسیاری از مسائل پیچیده، راهحلهای بسیار خوبی ارائه میدهد و از نظر محاسباتی نیز مقرونبهصرفه است.
در این جلسه، ابتدا با مبانی جستوجوی محلی و مفاهیمی همچون تابع هدف، تابع هزینه، حالت فعلی و حالتهای همسایه آشنا میشویم. سپس الگوریتم بالا رفتن از تپه، چالشهای آن و اصلاحات ممکن بررسی میشود. در ادامه، روش بازپخت شبیهسازیشده بهعنوان یکی از الگوریتمهای مؤثر برای فرار از بهینههای محلی معرفی میشود. همچنین با مسئلهٔ کلاسیک فروشندهٔ دورهگرد و نحوهٔ استفاده از روشهای محلی برای حل تقریبی آن آشنا میگردیم. در پایان نیز، برنامهریزی خطی و ساختار کلی آن بهعنوان یکی از ابزارهای شناختهشدهٔ بهینهسازی مطرح میشود.
هدف این درس، ایجاد درکی روشن و کاربردی از روشهای بهینهسازی است تا بتوان از آنها در حل مسائل پیچیدهٔ هوش مصنوعی بهره گرفت.
بهینهسازی:
بهینهسازی یعنی انتخاب بهترین گزینه از میان مجموعهای از گزینههای ممکن. ما پیشتر با مسائلی روبهرو شدهایم که در آنها سعی میکردیم بهترین گزینه را پیدا کنیم، مانند الگوریتم مینیمکس(Minimax). امروز قرار است با ابزارهایی آشنا شویم که میتوانند برای حل دامنهی گستردهتری از مسائل به کار گرفته شوند.
جستوجوی محلی (Local Search) نوعی الگوریتم جستوجو است که فقط یک وضعیت (یا گره) را نگه میدارد و با حرکت کردن به وضعیتهای همسایه، فرایند جستوجو را پیش میبرد. این نوع الگوریتم با روشهایی که قبلاً دیدیم متفاوت است. مثلاً در حل یک ماز (هزارتو)، هدف پیدا کردن سریعترین مسیر تا نقطهٔ پایان بود؛ اما در جستوجوی محلی، هدف یافتن بهترین پاسخ برای یک مسئله است.
در بسیاری از مواقع، جستوجوی محلی پاسخی ارائه میدهد که شاید کاملاً بهینه نباشد، اما «بهقدر کافی خوب» است و در عین حال توان محاسباتیِ کمتری مصرف میکند.
بهعنوان مثال، یک مسئلهٔ جستوجوی محلی را در نظر بگیرید: چهار خانه در مکانهای مشخص داریم. میخواهیم دو بیمارستان بسازیم طوری که مجموع فاصلهٔ هر خانه تا یک بیمارستان، حداقل شود. میتوان این مسئله را به شکل زیر تجسم کرد:
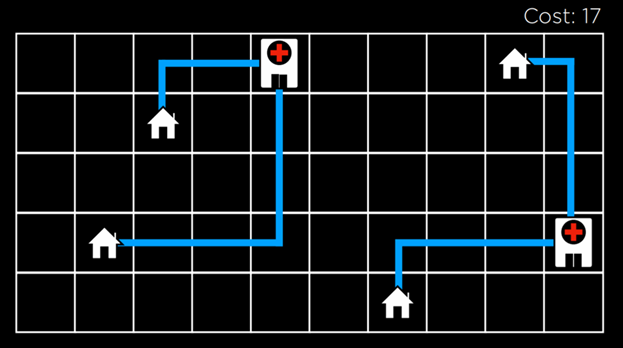
هوش مصنوعی CS50 s3
در این تصویر، یک چیدمانِ ممکن از خانهها و بیمارستانها را میبینیم. فاصلهٔ بین آنها با استفاده از فاصلهٔ منهتن اندازهگیری میشود (یعنی تعداد حرکتهای بالا، پایین، چپ و راست؛ که در جلسهٔ صفر با جزئیات توضیح داده شد). مجموع فاصلهٔ هر خانه تا نزدیکترین بیمارستان برابر با <strong>۱۷ است. ما این مقدار را «هزینه» مینامیم، چون هدفمان کمینه کردن این فاصله است. در این مسئله، هر حالت یک چیدمان مشخص از خانهها و بیمارستانها خواهد بود.
اگر این مفهوم را انتزاعیتر کنیم، میتوانیم هر چیدمانِ خانهها و بیمارستانها را بهصورت یک نقطه در «چشمانداز فضای حالت» (state-space landscape) نمایش دهیم. هر کدام از میلهها در این تصویر، مقدار یک حالت را نشان میدهد؛ که در مثال ما این مقدار همان هزینهٔ یک چیدمان خاص از خانهها و بیمارستانها است.
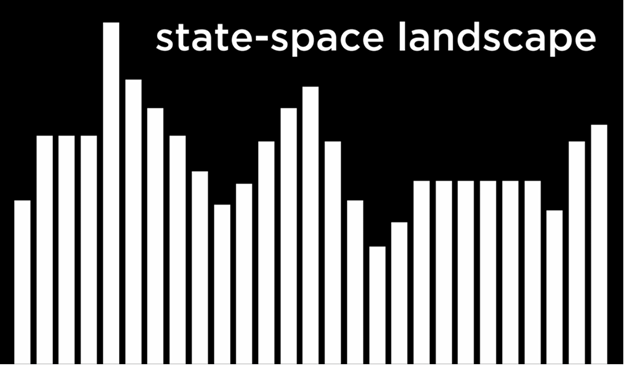
با توجه به این تصویر ذهنی، میتوانیم چند اصطلاح مهم را که در ادامهٔ بحث استفاده میشوند، تعریف کنیم:
- تابع هدف (Objective Function): تابعی است که میخواهیم مقدار آن را بیشینه کنیم.
- تابع هزینه (Cost Function): تابعی است که میخواهیم مقدار آن را کمینه کنیم. در مثال خانهها و بیمارستانها، این همان مجموع فاصلههاست که میخواهیم کمترین مقدار ممکن باشد.
- حالت فعلی (Current State): حالتی است که الگوریتم در همین لحظه در حال بررسی آن است.
- حالت همسایه (Neighbor State): حالتی است که از حالت فعلی با یک تغییر کوچک قابل دستیابی است. در چشمانداز یکبعدی فضای حالت، حالت همسایه همان حالتی است که در سمت چپ یا راست حالت فعلی قرار دارد. در مثال ما، یک حالت همسایه میتواند حالتی باشد که در آن یکی از بیمارستانها را یک خانه در هر جهت جابهجا کرده باشیم.
حالتهای همسایه معمولاً شبیه حالت فعلی هستند و بنابراین مقدارشان نیز نزدیک به مقدار حالت فعلی است.
توجه داشته باشید که الگوریتمهای جستوجوی محلی اینگونه عمل میکنند که یک حالت را در نظر میگیرند و سپس آن را به یکی از حالتهای همسایهاش منتقل میکنند. این روش متفاوت از الگوریتمی مانند مینیمکس است که در آن همهٔ حالتهای ممکن بهصورت بازگشتی بررسی میشدند.
-
بالا رفتن از تپه (Hill Climbing)
بالا رفتن از تپه یکی از انواع الگوریتمهای جستوجوی محلی است. در این الگوریتم، حالتهای همسایه با حالت فعلی مقایسه میشوند و اگر یکی از آنها وضعیت بهتری داشته باشد، حالت فعلی با آن حالت همسایه جایگزین میشود.
اینکه «بهتر» دقیقاً به چه معناست، بستگی به تابعی دارد که استفاده میکنیم:
اگر تابع هدف داشته باشیم، مقدارهای بالاتر بهتر هستند،
و اگر تابع هزینه داشته باشیم، مقدارهای کمتر بهتر محسوب میشوند.
یک الگوریتم بالا رفتن از تپه (Hill Climbing) در شبهکد به شکل زیر است:
function Hill-Climb(problem):
current = initial state of problem
repeat:
neighbor = best valued neighbor of current
if neighbor not better than current:
return current
current = neighbor
آموزش های هوش مصنوعی بخش هوش مصنوعی CS50 s3
در این الگوریتم، ما با یک حالت فعلی شروع میکنیم. در برخی مسئلهها، حالت اولیه مشخص است و میدانیم از کجا باید آغاز کنیم؛ اما در برخی دیگر باید یک حالت اولیه را بهصورت تصادفی انتخاب کنیم.
سپس این مراحل را تکرار میکنیم:
- <li>حالتهای همسایه را بررسی میکنیم و بهترینِ آنها را انتخاب میکنیم.
- مقدار آن حالت همسایه را با مقدار حالت فعلی مقایسه میکنیم.
- اگر حالت همسایه بهتر بود، حالت فعلی را با آن جایگزین میکنیم و روند را دوباره ادامه میدهیم.
این فرایند تا جایی ادامه پیدا میکند که بهترین همسایهای که پیدا میکنیم از حالت فعلی بهتر نباشد؛ در این صورت، الگوریتم متوقف شده و حالت فعلی را بهعنوان نتیجه برمیگرداند.
با استفاده از الگوریتم بالا رفتن از تپه، میتوانیم محلهای انتخابشده برای بیمارستانها را در مثال خودمان بهبود دهیم. پس از چند بار انتقال، به حالت زیر میرسیم:
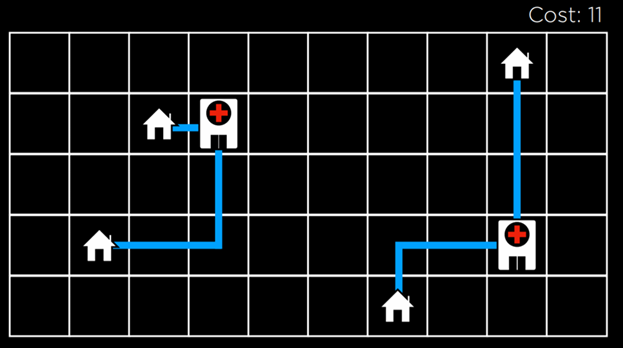
در این حالت، هزینه برابر با ۱۱ است که نسبت به هزینهٔ اولیه یعنی ۱۷ بهبود یافته است. با این حال، این حالت هنوز بهینهترین حالت ممکن نیست. برای مثال، اگر بیمارستان سمت چپ را طوری جابهجا کنیم که درست زیرِ خانهٔ بالا-سمت چپ قرار بگیرد، هزینه به ۹ میرسد که از ۱۱ بهتر است.&amp;amp;amp;amp;amp;amp;amp;lt;/p></p>
<p>اما نسخهٔ ساد</p></p>
<p><p>هٔ
الگوریتم Hill Climbing قادر نیست به این حالت برسد، چون تمام حالتهای همسایهٔ حالت فعلی هزینهای برابر یا بیشتر دارند. به همین دلیل میگوییم Hill Climbing یک الگوریتم کوتاهبین است؛ یعنی ممکن است روی پاسخی متوقف شود که از حالتهای اطراف خود بهتر است، اما لزوماً بهترین پاسخ ممکن در کل فضای حالت نیست.
کمینه و بیشینهٔ محلی و سراسری
همانطور که اشاره شد، الگوریتم بالا رفتن از تپه ممکن است در یک بیشینهٔ محلی یا کمینهٔ محلی گیر کند.
- بیشینهٔ محلی (Local Maximum): حالتی است که مقدارش از همهٔ حالتهای همسایه بیشتر است، اما ممکن است در کل فضای حالت بهترین نباشد.
- در مقابل، بیشینهٔ سراسری (Global Maximum): حالتی است که مقدارش از تمام حالتهای موجود در فضای حالت بیشترین مقدار است.
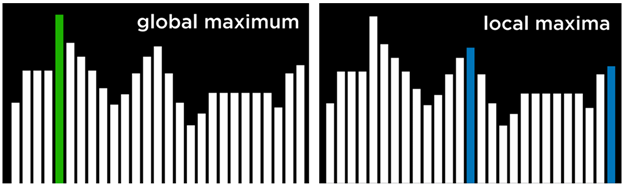
حالتی است که مقدار آن از مقدار همهٔ حالتهای همسایه کمتر است؛ اما ممکن است کمترین مقدار در کل فضای حالت نباشد.
در طرف دیگر، کمینهٔ سراسری (Global Minimum) حالتی است که مقدار آن از تمام حالتهای موجود در فضای حالت کمترین مقدار ممکن است
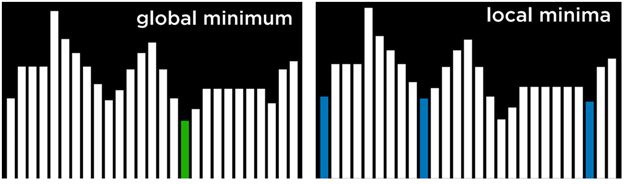
مشکل الگوریتمهای بالا رفتن از تپه این است که ممکن است در کمینهها یا بیشینههای محلی گیر کنند. وقتی الگوریتم به حالتی برسد که مقدارِ همهٔ حالتهای همسایه — از نظر تابع مورد استفاده — بدتر از حالت فعلی باشد، الگوریتم متوقف میشود.
برخی انواع خاصِ کمینه و بیشینهٔ محلی عبارتاند از:
- <h4>”color: #008000;”>بیشینه/کمینهٔ محلیِ صاف</strong><strong> (Flat Local Maximum/Minimum):
در این حالت، چندین وضعیت با مقدار یکسان کنار هم قرار گرفتهاند و یک سکوی مسطح (plateau) تشکیل میدهند؛ بهطوریکه تمام همسایههای این سکو مقدار بدتری دارند. - شانه (Shoulder):
در این حالت نیز چند وضعیت با مقدار برابر کنار هم قرار گرفتهاند، اما همسایههای این سکو ممکن است هم بهتر و هم بدتر باشند.
اگر الگوریتم از وسط این سکو (plateau) شروع کند، چون هیچکدام از همسایهها بهتر از وضعیت فعلی نیستند، در هیچ جهتی نمیتواند پیشرفت کند.
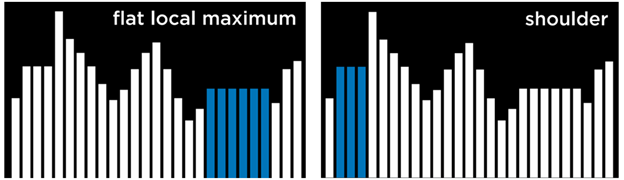
گونههای الگوریتم Hill Climbing:
بهدلیل محدودیتهای الگوریتم بالا رفتن از تپه، چندین نسخهٔ اصلاحشده از آن طراحی شدهاند تا مشکل گیرکردن در کمینهها و بیشینههای محلی کاهش یابد.
اما نکتهٔ مشترک میان همهٔ این نسخهها این است که هیچکدام تضمین نمیکنند که الگوریتم از یک نقطهٔ محلی فراتر برود و همچنان ممکن است در آن گیر کند و نتواند بهینهسازی را ادامه دهد.
در توضیح زیر فرض شده که مقدارهای بزرگتر بهتر هستند، اما همین ایده برای تابعهای هزینه (که در آن هر مقدار کمتر بهتر است) نیز قابل اعمال است.
-
Steepest-ascent بیشترین شیب:
بهترین و بالاترین مقدارِ میان حالتهای همسایه انتخاب میشود. این همان نسخهٔ استاندارد است که قبلاً توضیح داده شد.
-
Stochastic جست و جوی تصادفی:
از میان همسایههایی که مقدارشان بهتر از حالت فعلی است، یکی را بهطور تصادفی انتخاب میکنیم.
این روش زمانی مفید است که مثلاً بهترین همسایه به یک بیشینهٔ محلی ختم میشود، اما یکی دیگر از همسایهها در نهایت ما را به بیشینهٔ سراسری برساند. -
First-choice اولین انتخاب:
اولین همسایهای که مقدارش از حالت فعلی بهتر است انتخاب میشود، بدون مقایسهٔ همهٔ همسایهها.
-
Random-restart شروع تصادفی:
چندین بار الگوریتم بالا رفتن از تپه را اجرا میکنیم. هر بار الگوریتم از یک حالت تصادفی شروع میشود.
در پایان، مقدارهای بهدستآمده در همهٔ اجراها مقایسه شده و بهترین آنها انتخاب میشود. -
Local Beam Search جستوجوی پرتو محلی:
در هر مرحله، بهجای یک حالت، k حالت با بیشترین مقدار انتخاب میشوند.
این روش برخلاف اغلب الگوریتمهای جستوجوی محلی، از چندین حالت بهطور همزمان استفاده میکند، نه فقط یکی.
حتی اگر الگوریتمهای جستوجوی محلی همیشه بهترین پاسخ ممکن را پیدا نکنند، معمولاً میتوانند یک جواب «بهقدر کافی خوب» ارائه دهند؛ مخصوصاً زمانی که بررسی تمام حالتهای ممکن از نظر محاسباتی غیرممکن یا بسیار سنگین باشد.
Simulated Annealing بازپخت شبیهسازیشده:
هرچند نسخههای مختلف Hill Climbing میتوانند عملکرد را بهبود دهند، اما همهٔ آنها یک مشکل مشترک دارند:
بهمحض رسیدن به یک بیشینهٔ محلی، الگوریتم متوقف میشود.
الگوریتم Simulated Annealing این امکان را میدهد که الگوریتم در صورت گیر کردن در یک بیشینهٔ محلی، بتواند خود را از آن نقطه جدا کند و به جستوجو ادامه دهد.
بازپخت (Annealing) فرایندی در فلزکاری است که طی آن فلز را حرارت میدهند و سپس بهآرامی سرد میکنند تا سختتر و مقاومتر شود. این مفهوم، الهامبخش الگوریتم Simulated Annealing است.
در این الگوریتم، «دما» ابتدا بالا است—یعنی احتمال انتخابهای تصادفی زیاد است—و هرچه دما کاهش مییابد، الگوریتم کمتر تصمیمهای تصادفی میگیرد و پایدارتر میشود.
این سازوکار باعث میشود که الگوریتم بتواند گاهی به حالتی برود که بدتر از حالت فعلی است؛ همین ویژگی است که کمک میکند از بیشینههای محلی فرار کند.
شبهکد Simulated Annealing:</span></h4>
tyle=”color: #999999;”>هوش مصنوعی CS50 s3
<p><p>
function Simulated-Annealing(problem, max):
current = initial state of problem
for t = 1 to max:
T = Temperature(t)
neighbor = random neighbor of current
ΔE = how much better neighbor is than current
if ΔE > 0:
current = neighbor
with probability e^(ΔE/T) set current = neighbor
return current
این الگوریتم ورودیهایی شامل مسئله و max (تعداد تکرارها) میگیرد.
در هر تکرار:
- مقدار T با استفاده از تابع Temperature تعیین میشود. این تابع در ابتدای کار )وقتی t کم است(مقدار زیادی میدهد و در مراحل پایانی مقدار کمتری.
- یک حالتِ همسایه بهطور تصادفی انتخاب میشود.
- &amp;amp;amp;amp;amp;amp;amp;lt;strong>ΔE محاسبه میشود؛ یعنی این همسایه چقدر بهتر از حالت فعلی است.
اگر ΔE مثبت بود، یعنی حالت همسایه بهتر است، آن را جایگزین حالت فعلی میکنیم.
اما اگر ΔE منفی بود—یعنی همسایه بدتر است—هنوز ممکن است آن را انتخاب کنیم، با احتمالی برابر:
e^(ΔE / T)
منطق این کار:
- هرچه ΔE منفیتر باشد → احتمال انتخاب کمتر است.
- هرچه دما(T) بیشتر باشد → احتمال انتخاب بیشتر است.
زیرا ΔE / T به صفر نزدیکتر میشود و e به توان عدد نزدیک به صفر، مقداری نزدیک به ۱ میدهد.
پس در مراحل اولیه، الگوریتم آمادگی بیشتری دارد که به حالتهای بدتر برود تا بتواند از دام حالتهای محلی خارج شود.
عدد e تقریباً ۲.۷۲ است، و چون ΔE در این حالت منفی است، e به توان ΔE/T مقداری میان ۰ و ۱ خواهد داد.
مسئلهٔ فروشندهٔ دورهگرد (Traveling Salesman Problem)
در مسئلهٔ فروشندهٔ دورهگرد، هدف این است که همهٔ نقاط (مثلاً شهرها یا خانهها) را طوری به هم وصل کنیم که کوتاهترین مسیر ممکن طی شود.
برای نمونه، شرکتهای ارسال بسته باید کوتاهترین مسیری را پیدا کنند که از فروشگاه شروع شود، به همهٔ مشتریها سر بزند و دوباره به فروشگاه بازگردد.
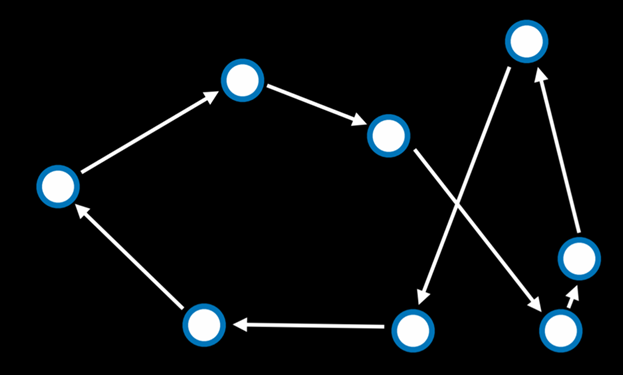
در مسئلهٔ فروشندهٔ دورهگرد، یک حالت همسایه میتواند حالتی باشد که در آن دو مسیر (یا دو پیکان) جای خود را با هم عوض کردهاند.
محاسبهٔ تمام ترکیبهای ممکن این مسئله، از نظر محاسباتی بسیار سنگین است؛ بهطور مثال، برای تنها ۱۰ نقطه، تعداد مسیرهای ممکن برابر است با 10!= 3,628,800.
با استفاده از الگوریتم Simulated Annealing میتوان با هزینهٔ محاسباتی بسیار کمتر یک جواب خوب پیدا کرد.
برنامهریزی خطی (Linear Programming)
برنامهریزی خطی خانوادهای از مسائل است که هدفشان بهینهسازی یک معادلهٔ خطی است، یعنی معادلهای از شکل:
در برنامهریزی خطی، اجزای زیر وجود دارند:
y=ax1+bx2+…
- تابع هزینه که میخواهیم کمینه شود:
c1x1+c2x2+⋯+cnxn
در اینجا هر xi یک متغیر است و هر متغیر با هزینهای ci مرتبط است.
- محدودیتها (Constraints) که به شکل مجموعی از متغیرها تعریف میشوند:
a1x1+a2x2+⋯+anxn≤b
یا
a1x1+a2x2+⋯+anxn=b
در اینجا ai منابع مرتبط با هر متغیر هستند و b مقدار کل منابع موجود است.
- محدودیتهای فردی روی متغیرها، مثلاً اینکه متغیر نمیتواند منفی باشد:
li≤xi≤ui
مثال عملی:
- دو ماشین X1 و X2 داریم:
- X1 هزینهٔ ۵۰ دلار در ساعت
- X2 هزینهٔ ۸۰ دلار در ساعت
هدف: کمینه کردن هزینه
تابع هزینه :
50x1+80x2
محدودیت منابع نیروی کار:
- X1 در هر ساعت ۵ واحد نیروی کار نیاز دارد
- X2 در هر ساعت ۲ واحد نیروی کار نیاز دارد
- مجموع نیروی کار قابل استفاده: ۲۰ واحد
محدودیت 5x1+2x2 ≤20 :
تولید مورد نیاز:
- X1 در هر ساعت ۱۰ واحد تولید
- X2 در هر ساعت ۱۲ واحد تولید
- کل تولید مورد نیاز: ۹۰ واحد
محدودیت: 10x1+12x2≥90
برای تبدیل به فرم استاندارد a1x1+a2x2≤b ضرب در -۱ میکنیم:
−10x1−12x2≤−90
حل بهینهٔ برنامهریزی خطی نیازمند دانش هندسه و جبر خطی است، اما میتوان از الگوریتمهای آماده مانند Simplex و Interior-Point استفاده کرد.
نمونهٔ زیر یک مثال برنامهریزی خطی است که از کتابخانهٔ SciPy در پایتون استفاده میکند.
import scipy.optimize
# Objective Function: 50x_1 + 80x_2
# Constraint 1: 5x_1 + 2x_2 <= 20
# Constraint 2: -10x_1 + -12x_2 <= -90
result = scipy.optimize.linprog(
[50, 80], # Cost function: 50x_1 + 80x_2
A_ub=[[5, 2], [-10, -12]], # Coefficients for inequalities
b_ub=[20, -90], # Constraints for inequalities: 20 and -90
)
if result.success:
print(f"X1: {round(result.x[0], 2)} hours")
print(f"X2: {round(result.x[1], 2)} hours")
else:
print("No solution")
مسائل رضایت محدودیت (Constraint Satisfaction Problems) دستهای از مسائل هستند که در آن باید برای متغیرها مقادیری تعیین شود، بهگونهای که مجموعهای از شرایط یا محدودیتها برآورده شوند.
مسائل رضایت محدودیت دارای ویژگیهای زیر هستند:
- مجموعهای از متغیرها xn،…،x2، x1&amp;amp;amp;amp;amp;amp;amp;lt;/li>
- <strong>مجموعهای از دامنهها برای هر متغیر</strong> {D1</sub>,D2,…,Dn}
- مجموعهای از محدودیتها C
سودوکو را میتوان بهعنوان یک مسئلهٔ رضایت محدودیت مدلسازی کرد؛ جایی که هر خانهٔ خالی یک متغیر است، دامنهٔ هر متغیر اعداد ۱ تا ۹ هستند، و محدودیتها این هستند که برخی خانهها (در یک سطر، ستون یا بلوک) نباید با یکدیگر مقدار برابر داشته باشند.
آموزش های هوش مصنوعی بخش هوش مصنوعی CS50 s3
مثال دیگری را در نظر بگیرید:
هر یک از دانشجویان ۱ تا ۴ سه درس از میان A, B, …, G. را میگذرانند. هر درس باید یک امتحان داشته باشد، و روزهای ممکن برای امتحانها دوشنبه، سهشنبه و چهارشنبه هستند. با این حال، یک دانشجو نمیتواند دو امتحان در یک روز داشته باشد.
در این مسئله:
- متغیرها: درسها
- دامنهها: روزهای امتحان
- محدودیتها: درسهایی که نباید در یک روز امتحان داشته باشند، زیرا دانشجوهای مشترک در آنها وجود دارند
این مسئله را میتوان به صورت زیر تجسم کرد: (در متن اصلی احتمالاً یک تصویر یا نمودار قرار دارد.)

این مسئله را میتوان با استفاده از محدودیتهایی حل کرد که بهصورت یک گراف نمایش داده میشوند.
در این گراف، هر گره نمایانگر یک درس است و بین دو درسی که نباید در یک روز امتحان داشته باشند، یک یال رسم میشود. در این حالت، گراف به شکل زیر خواهد بود: (در متن اصلی احتمالاً تصویر یا نموداری قرار داشته است.)
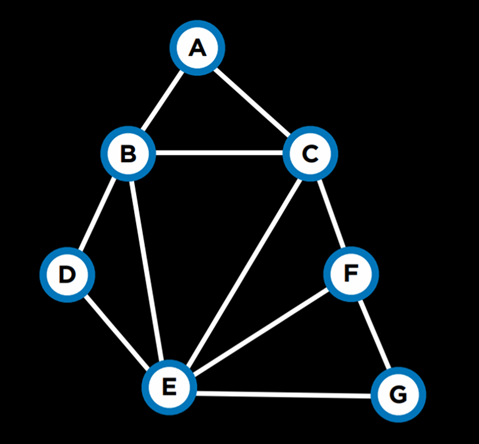
چند مفهوم دیگر که دانستن آنها دربارهٔ مسائل ارضای محدودیت (CSP) مفید است:
- محدودیت سخت: (Hard Constraint) محدودیتی است که در یک جواب درست حتماً باید رعایت شود.
- محدودیت نرم :(Soft Constraint) محدودیتی است که بیان میکند کدام جوابها نسبت به بقیه <strong>مطلوبتر هستند.
- محدودیت یگانی<strong>: (Unary Constraint) محدودیتی که فقط یک متغیر را درگیر میکند.
در مثال ما، یک محدودیت یگانی میتواند این باشد که درس A نمیتواند در روز دوشنبه امتحان داشته باشد:
{A ≠ Monday} - محدودیت دوتایی :(Binary Constraint) محدودیتی که دو متغیر را شامل میشود.
مثل محدودیتی که در مثال بالا داشتیم، یعنی اینکه دو درس نمیتوانند یک مقدار (روز) یکسان داشته باشند:
{A ≠ B}
سازگاری گره (Node Consistency)
سازگاری گره (Node Consistency) جمله بعدی احتمالاً توضیح مفهوم Node Consistency است که در ادامهٔ متن اصلی قرار داشته است .
زمانی برقرار است که تمام مقادیر موجود در دامنهٔ یک متغیر، محدودیتهای یگانی آن متغیر را ارضا کنند.
برای مثال، دو درس A و B را در نظر بگیرید. دامنهٔ هر درس {دوشنبه، سهشنبه، چهارشنبه} است و محدودیتها عبارتاند از:
{A ≠ دوشنبه، B ≠ سهشنبه، B ≠ دوشنبه، A ≠ B}
آموزش های هوش مصنوعی بخش هوش مصنوعی CS50 s3
در این وضعیت، هیچیک از A یا B سازگار نیستند، زیرا محدودیتهای موجود باعث میشوند برخی از مقادیر موجود در دامنهٔ آنها امکانپذیر نباشند.
برای سازگار کردن A باید دوشنبه را از دامنهٔ آن حذف کنیم تا دیگر هیچ مقدار ممنوعی در دامنهاش وجود نداشته باشد.
برای سازگار کردن B باید هر دو مقدار دوشنبه و سهشنبه را از دامنهٔ آن حذف کنیم تا دامنه فقط شامل مقادیر مجاز باشد.
سازگاری قوسی (Arc Consistency) زمانی برقرار است که تمام مقادیر موجود در دامنهٔ یک متغیر، محدودیتهای دودویی بین آن متغیر و متغیر دیگر را ارضا کنند.
توجه کنید که اکنون از واژهٔ arc برای اشاره به همان «یال» در گراف محدودیتها استفاده میکنیم.
به عبارت دیگر، برای سازگار کردن X نسبت به Y باید از دامنهٔ X مقادیری حذف شود تا برای هر مقدار ممکن X، حداقل یک مقدار ممکن برای Y وجود داشته باشد.
به مثال قبلی با دامنههای اصلاحشده برگردیم:
A : {سهشنبه، چهارشنبه}
B : {چهارشنبه}
برای اینکه A نسبت به B سازگاری قوسی داشته باشد، باید بدون توجه به اینکه امتحان درس A در چه روزی (از دامنهاش) برنامهریزی شود، هنوز B بتواند روزی برای امتحان انتخاب کند.
آیا A نسبت به B سازگار قوسی است؟
- اگر A مقدار سهشنبه بگیرد، آنگاه B میتواند مقدار چهارشنبه را بگیرد.
- اما اگر A مقدار چهارشنبه بگیرد، آنگاه B نمیتواند هیچ مقداری بگیرد (زیرا یکی از محدودیتها A ≠ B است)
پس A سازگار قوسی با B نیست.
برای اصلاح این وضعیت، میتوانیم مقدار چهارشنبه را از دامنهٔ A حذف کنیم.
در این صورت، تنها مقدار A برابر سهشنبه است، و این مقدار به B اجازه میدهد مقدار چهارشنبه را انتخاب کند.
اکنون A سازگار قوسی با B است.
در ادامه، شبهکدی آورده شده است که یک متغیر را نسبت به متغیر دیگر سازگار قوسی میکند (توجه کنید که csp مخفف «مسئلهٔ رضایت محدودیتها» است).
revised = false
for x in X.domain:
if no y in Y.domain satisfies constraint for (X, Y):
delete x from X.domain
revised = true
return revised
ترجمهٔ توضیحی:
- مقدار revised ابتدا برابر false قرار داده میشود.
- برای هر مقدار x در دامنهٔ X بررسی میشود:
- اگر هیچ مقدار y در دامنهٔ Y وجود نداشته باشد که محدودیت بین (X, Y) را ارضا کند،
آنگاه مقدار x از دامنهٔ X حذف میشود و revised = true میشود.
&amp;amp;amp;amp;amp;amp;amp;lt;/ul></ul> </li>
- اگر هیچ مقدار y در دامنهٔ Y وجود نداشته باشد که محدودیت بین (X, Y) را ارضا کند،
- در پایان، مقدار revised برگردانده میشود.
این الگوریتم مشخص میکند آیا دامنهٔ X در فرایند سازگار کردن قوسی تغییر کرده است یا نه.
الگوریتم با پیگیری اینکه آیا هیچ تغییری در دامنهٔ X ایجاد شده است یا نه، با استفاده از متغیر revised شروع میکند. این در الگوریتم بعدی که بررسی خواهیم کرد مفید خواهد بود. سپس، کد برای هر مقدار موجود در دامنهٔ X تکرار میشود و بررسی میکند که آیا Y مقداری دارد که محدودیتها را ارضا کند یا نه. اگر بله، هیچ کاری انجام نمیدهد؛ و اگر نه، آن مقدار را از دامنهٔ X حذف میکند.
اغلب ما به دنبال این هستیم که کل مسئله را قوسسازگار (arc-consistent) کنیم، نه فقط یک متغیر را نسبت به متغیر دیگر. در این حالت، از الگوریتمی به نام AC-3 استفاده میکنیم که از تابع Revise بهره میگیرد:
function AC-3(csp):
queue = all arcs in csp
while queue non-empty:
(X, Y) = Dequeue(queue)
if Revise(csp, X, Y):
return true
if size of X.domain == 0:
return false
for each Z in X.neighbors - {Y}:
Enqueue(queue, (Z,X))
آموزش های هوش مصنوعی بخش هوش مصنوعی CS50 s3
این الگوریتم تمام قوسهای مسئله را به یک صف اضافه میکند. هر بار که یک قوس را بررسی میکند، آن را از صف خارج میسازد. سپس الگوریتم Revise را اجرا میکند تا ببیند آیا این قوس سازگار هست یا نه.
اگر برای سازگار کردن آن تغییراتی انجام شده باشد، اقدامات بیشتری لازم است. اگر دامنهٔ بهدستآمده برای X خالی شود، یعنی این مسئلهٔ ارضای محدودیتها غیرقابلحل است (چون هیچ مقداری وجود ندارد که X بتواند بگیرد و اجازه دهد Y نیز تحت محدودیتها مقداری بگیرد).
در صورت که در مرحلهٔ قبل مسئله غیرقابلحل تشخیص داده نشود، آنگاه چون دامنهٔ X تغییر کرده است، باید بررسی کنیم که آیا تمام قوسهای مرتبط با X همچنان سازگار هستند یا نه. به این صورت که تمام همسایههای X بهجز Y را برمیداریم و قوسهای بین آنها و X را به صف اضافه میکنیم. اما اگر الگوریتم Revise مقدار false برگرداند، یعنی دامنه تغییری نکرده است، پس فقط به بررسی سایر قوسها ادامه میدهیم.
در حالی که الگوریتم سازگاری قوسی (Arc Consistency) میتواند مسئله را سادهتر کند، ولی لزوماً آن را حل نخواهد کرد، چون فقط محدودیتهای دوتایی را در نظر میگیرد و نه نحوهٔ ارتباط چندین گره با یکدیگر.
مثال قبلی ما، که در آن هر یک از ۴ دانشجو ۳ درس برمیدارند، پس از اجرای AC-3 بدون تغییر باقی میماند.
ما در اولین جلسه با مسائل جستجو مواجه شدیم. یک مسئلهٔ ارضای محدودیتها را میتوان یک مسئلهٔ جستجو در نظر گرفت:
- حالت اولیه: تخصیص خالی (هیچ متغیری مقداری به آن اختصاص داده نشده است).
- کنشها: افزودن یک {variable = value} به تخصیص؛ یعنی دادن یک مقدار به یک متغیر.
- مدل انتقال: نشان میدهد افزودن این تخصیص چگونه وضعیت را تغییر میدهد. عمق زیادی ندارد؛ مدل انتقال حالتی را بازمیگرداند که شامل همان تخصیصِ پس از آخرین کنش است.
- آزمون هدف: بررسی اینکه آیا تمام متغیرها مقداری دریافت کردهاند و همهٔ محدودیتها ارضا شدهاند یا خیر.
- تابع هزینهٔ مسیر: تمام مسیرها هزینهٔ یکسانی دارند. همانطور که پیشتر گفتیم، برخلاف مسائل جستجوی معمولی، در مسائل بهینهسازی، آنچه اهمیت دارد خودِ راهحل است نه مسیر رسیدن به آن.
با این حال، اگر بخواهیم یک مسئلهٔ ارضای محدودیتها را بهصورت ساده و مانند یک مسئلهٔ جستجوی معمولی حل کنیم، این کار بسیار ناکارآمد خواهد بود. در عوض، میتوانیم از ساختار یک مسئلهٔ ارضای محدودیتها بهره ببریم و آن را کارآمدتر حل کنیم.
جستجوی پسگرد (Backtracking Search)
جستجوی پسگرد نوعی الگوریتم جستجو است که ساختار مسئلهٔ ارضای محدودیتها (CSP) را در نظر میگیرد. در حالت کلی، این یک تابع بازگشتی است که تلاش میکند تا زمانی که محدودیتها رعایت میشوند، به مقداردهی متغیرها ادامه دهد. اگر محدودیتی نقض شود، الگوریتم یک مقداردهی دیگر را امتحان میکند.
بیایید شبهکد مربوط به آن را بررسی کنیم:
function Backtrack(assignment, csp):
if assignment complete:
return assignment
var = Select-Unassigned-Var(assignment, csp)
for value in Domain-Values(var, assignment, csp):
if value consistent with assignment:
add {var = value} to assignment
result = Backtrack(assignment, csp)
if result ≠ failure:
return result
remove {var = value} from assignment
return failure
آموزش های هوش مصنوعی بخش هوش مصنوعی CS50 s3
بهطور ساده، این الگوریتم اگر تخصیص فعلی کامل باشد، همان را بازمیگرداند. این یعنی اگر الگوریتم کار خود را تمام کرده باشد، هیچ اقدام اضافی انجام نمیدهد و صرفاً همان تخصیص کاملشده را برمیگرداند. اگر تخصیص کامل نباشد، الگوریتم یکی از متغیرهایی را که هنوز مقداری برای آنها تعیین نشده انتخاب میکند. سپس تلاش میکند مقداری از دامنه را به آن متغیر اختصاص دهد و الگوریتم Backtrack را روی تخصیص جدید دوباره اجرا میکند (بازگشت/recursion).
سپس نتیجهٔ این اجرا بررسی میشود. اگر نتیجه شکست (failure) نباشد، یعنی این تخصیص موفق بوده است و باید همین تخصیص را بازگرداند. اما اگر نتیجه failure باشد، یعنی این مقداردهی جواب نداده و باید آخرین تخصیص را حذف کرده و مقدار دیگری را امتحان کند. این فرایند برای تمام مقادیر ممکن در دامنه تکرار میشود. اگر همهٔ مقادیر ممکن به failure منجر شوند، یعنی باید پسگرد (backtrack) کرد. به این معنا که مسئله در وضعیت فعلی قابلحل نیست و باید به مرحلهٔ با یک تخصیص قبلی بازگردیم. اگر این وضعیت برای همان متغیری رخ دهد که از ابتدا با آن شروع کردهایم، در این صورت یعنی هیچ راهحلی وجود ندارد که بتواند محدودیتها را ارضا کند.
اکنون، روند زیر را در نظر بگیرید:
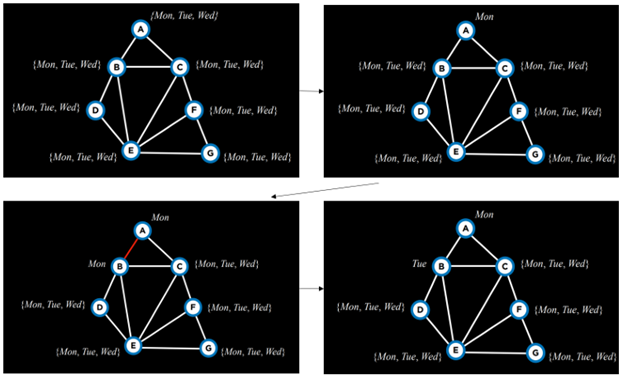
هوش مصنوعی CS50 s3
ما با یک تخصیص خالی شروع میکنیم (بالا-چپ). سپس متغیر A را انتخاب کرده و مقداری مانند دوشنبه را به آن اختصاص میدهیم (بالا-راست). سپس با استفاده از این تخصیص، الگوریتم دوباره اجرا میشود. حال که A یک مقدار دارد، الگوریتم سراغ B میرود و مقدار دوشنبه</strong> را به آن اختصاص میدهد (پایین-چپ). این تخصیص نامعتبر (false) برمیگردد، بنابراین بهجای اینکه بر اساس این تخصیص به سراغ مقداردهی متغیر C برویم، الگوریتم تلاش میکند مقدار دیگری را به B بدهد؛ برای مثال سهشنبه (پایین-راست). این تخصیص جدید محدودیتها را ارضا میکند، و با این تخصیص، متغیر جدیدی در مرحلهٔ بعد در نظر گرفته خواهد شد.
اگر، برای مثال، دادن مقدار سهشنبه یا چهارشنبه به B همگی به شکست منجر شوند، آنگاه الگوریتم پسگرد (backtrack) میکند و دوباره به A برمیگردد و مقدار دیگری مانند سهشنبه را به آن اختصاص میدهد. اگر اختصاص سهشنبه و چهارشنبه به A نیز ناموفق باشد، یعنی تمام تخصیصهای ممکن امتحان شدهاند و مسئله غیرقابلحل است.
در بخش کد منبع، میتوانید یک پیادهسازی از ابتدا برای الگوریتم backtrack پیدا کنید. با این حال، این الگوریتم به شدت رایج است و در نتیجه بسیاری از کتابخانهها پیادهسازی آمادهٔ آن را در اختیار دارند.
استنتاج (Inference)
با اینکه جستجوی پسگرد بسیار کارآمدتر از جستجوی ساده است، ولی همچنان به توان محاسباتی زیادی نیاز دارد. از طرف دیگر، اعمال سازگاری قوسی (Arc Consistency) هزینهٔ محاسباتی کمتری دارد. با ترکیب جستجوی پسگرد با استنتاج (یعنی اعمال سازگاری قوسی در حین جستجو)، میتوانیم به الگوریتمی بسیار کارآمدتر برسیم. این الگوریتم همان الگوریتم حفظ سازگاری قوسی یا MAC – Maintaining Arc Consistency است.
در این الگوریتم، پس از هر مقداردهی جدید در جستجوی پسگرد، سازگاری قوسی اعمال میشود. بهطور دقیق، پس از اینکه مقدار تازهای به X اختصاص داده شد، الگوریتم AC-3 فراخوانی میشود؛ اما نه با صفی شامل تمام قوسهای مسئله، بلکه با صفی شامل تمام قوسهای (Y, X) که در آن Y همسایۀ X است.
در ادامه نسخهٔ اصلاحشدهای از الگوریتم Backtrack آمده است که سازگاری قوسی را حفظ میکند و بخشهای افزودهشده با پررنگ مشخص شدهاند.
function Backtrack(assignment, csp):
if assignment complete:
return assignment
var = Select-Unassigned-Var(assignment, csp)
for value in Domain-Values (var, assignment, csp):
if value consistent with assignment:
add {var = value} to
assignment
inferences = Inference (assignment, csp)
if inferences ≠ failure:
add inferences to assignment
result = Backtrack (assignment, csp)
if result ≠ failure:
return result
remove {var = value} and inferences from assignment
return failure

هوش مصنوعی CS50 s3
تابع Inference الگوریتم AC-3 را همانطور که توضیح داده شد اجرا میکند. خروجی این تابع تمام استنتاجهایی است که از طریق اعمال سازگاری قوسی به دست میآیند. بهطور literal، اینها همان مقداردهیهای جدیدی هستند که میتوان از روی مقداردهیهای قبلی و ساختار مسئلهٔ ارضای محدودیتها نتیجه گرفت.&amp;amp;amp;amp;amp;amp;amp;lt;/p></p>
روشهای دیگ
ری نیز برای کارآمدتر کردن الگوریتم وجود دارد. تا اینجا ما یک متغیر تخصیصنیافته را بهصورت تصادفی انتخاب میکردیم. اما برخی انتخابها احتمال بیشتری دارند که سریعتر ما را به پاسخ برسانند. برای این منظور به هیوریستیکها نیاز داریم. هیوریستیک یک «قانون سرانگشتی» است؛ یعنی در بسیاری از موارد نتیجهٔ بهتری نسبت به روش ساده میدهد، اما هیچ تضمینی وجود ندارد که همیشه بهترین کار را انجام دهد.
یکی از این هیوریستیکها کمترین مقادیر باقیمانده Minimum Remaining Values یا MRV است.
ایدهٔ آن این است که اگر دامنهٔ یک متغیر بر اثر استنتاج محدود شده و اکنون فقط یک ارزش (یا حتی دو ارزش) برای آن باقی مانده است، تخصیص این مقدار به آن متغیر میتواند تعداد پسگردهایی که بعدها لازم میشود را کاهش دهد. به عبارتی، دیر یا زود باید این مقداردهی را انجام دهیم، چون از اعمال سازگاری قوسی استنتاج شده است. اگر این مقداردهی به شکست منجر شود، بهتر است هرچه زودتر متوجه این شکست شویم و نه در مراحل بعد که هزینهٔ بیشتری دارد.
برای مثال،
پس از محدود شدن دامنهٔ متغیرها با توجه به تخصیص فعلی، با استفاده از هیوریستیک MRV متغیر C را انتخاب میکنیم و مقدار چهارشنبه را به آن اختصاص میدهیم.
هیوریستیک درجه (Degree heuristic) بر اساس درجهٔ متغیرها عمل میکند؛ درجه یعنی تعداد قوسهایی که یک متغیر را به سایر متغیرها متصل میکنند. با انتخاب متغیری که بیشترین درجه را دارد، میتوانیم با تنها یک تخصیص، تعداد زیادی از متغیرهای دیگر را محدود کنیم؛ و این کار باعث میشود روند اجرای الگوریتم سریعتر شود.
برای مثال،
تمام متغیرهای بالا دامنههایی با اندازهٔ یکسان دارند. بنابراین باید متغیری را انتخاب کنیم که بیشترین درجه را دارد، که در این حالت متغیر E خواهد بود.
هر دو هیوریستیک همیشه قابلاستفاده نیستند. برای مثال، زمانی که چندین متغیر تعداد مساوی کمترین مقدارها را در دامنهٔ خود دارند، یا چندین متغیر بالاترین درجهٔ یکسانی دارند.
روش دیگری برای کارآمدتر کردن الگوریتم، استفاده از یک هیوریستیک دیگر در هنگام انتخاب یک مقدار از دامنهٔ یک متغیر است. اینجا میخواهیم از هیوریستیک کمترین محدودکنندگی مقدار (Least Constraining Value) استفاده کنیم؛ یعنی مقداری را انتخاب کنیم که کمترین محدودیت را روی سایر متغیرها اعمال کند. ایدهٔ این روش این است که:
در حالی که در هیوریستیک درجه میخواستیم متغیری را انتخاب کنیم که بیشتر از همه متغیرهای دیگر را محدود میکند، در اینجا میخواهیم مقداری را انتخاب کنیم که کمترین محدودیت را ایجاد کند. به عبارتی، ابتدا متغیری را پیدا میکنیم که میتواند بزرگترین منبع مشکل باشد (متغیری با بالاترین درجه)، و سپس آن را تا حد ممکن کم ترین میکنیم (با اختصاص دادن کممحدودکنندهترین مقدار).
برای مثال،
متغیر C را در نظر بگیرید. اگر مقدار سهشنبه را به آن نسبت دهیم، متغیرهای B، E و F همگی محدود میشوند. اما اگر <strong>چهارشنبه</strong> را انتخاب کنیم، تنها <strong>B و E محدود میشوند. بنابراین احتمالاً بهتر است مقدار چهارشنبه انتخاب شود.
در جمعبندی، مسائل بهینهسازی را میتوان به روشهای مختلفی فرمولبندی کرد. امروز ما سه نوع روش را بررسی کردیم:
جستجوی محلی (Local Search)، برنامهریزی خطی (Linear Programming)، و ارضای محدودیتها (Constraint Satisfaction).
هوش مصنوعی CS50 s3
خلاصه Lecture 3 – مسائل ارضای محدودیتها و جستجو
- مسائل ارضای محدودیتها (Constraint Satisfaction Problems – CSPs)
- CSPها مسائلی هستند که متغیرها، دامنهها و محدودیتها دارند.
- هدف: اختصاص دادن مقادیر به متغیرها به طوری که تمام محدودیتها رعایت شوند.
- مثال: تعیین برنامهٔ درسی برای دانشجویان، که هر دانشجو باید سه درس انتخاب کند بدون برخورد زمانی.
CSP بهعنوان مسئلهٔ جستجو:
- حالت اولیه: هیچ متغیری مقداردهی نشده است.
- کنشها: اختصاص مقدار به یک متغیر.
- مدل انتقال: تغییر وضعیت با هر مقداردهی جدید.
- آزمون هدف: بررسی اینکه همهٔ متغیرها مقدار گرفتهاند و تمام محدودیتها رعایت شدهاند.
- تابع هزینه مسیر: برای CSPها معمولاً همهٔ مسیرها هزینهٔ یکسان دارند، اهمیت با راهحل نهایی است نه مسیر.
سازگاری قوسی (Arc Consistency – AC)
- الگوریتم AC-3: بررسی تمام قوسها بین متغیرها برای تضمین اینکه هر مقدار یک متغیر با حداقل یک مقدار متغیر مرتبط سازگار است.
- اگر پس از اعمال AC دامنهٔ متغیری خالی شود → مسئله غیرقابلحل است.
- مزیت: سادهسازی مسئله قبل از شروع جستجوی جدی، اما CSP را همیشه حل نمیکند.
- AC با Backtracking ترکیب میشود تا الگوریتم MAC (Maintaining Arc Consistency) ایجاد شود که کارآمدتر است.
جستجوی پسگرد (Backtracking Search)
-
یک الگوریتم بازگشتی برای CSPها:
- اگر تخصیص کامل باشد → بازگرداندن نتیجه.
- انتخاب یک متغیر تخصیصنیافته.
- امتحان مقادیر ممکن دامنهٔ متغیر.
- اگر مقداردهی موفق باشد → ادامه بازگشت (recursion).
- اگر تمام مقادیر شکست بخورند → پسگرد (Backtrack) به مرحلهٔ قبلی.
-
ترکیب با AC → هر مقداردهی جدید را بررسی و سازگاری قوسی اعمال میکنیم تا تعداد پسگردها کاهش یابد.</h5>
<h4>tyle=”color: #008000;”&gt;<strong>استنتاج<strong> (Inference)
- تابع Inference: پس از هر تخصیص جدید، الگوریتم AC-3 اجرا میشود.
- نتیجه: مقداردهیهای جدیدی که از روی محدودیتها و تخصیصهای قبلی استنتاج میشوند.
هیوریستیکها برای بهبود کارایی
- MRV (Minimum Remaining Values): انتخاب متغیری که کمترین مقادیر باقیمانده در دامنه دارد → کاهش پسگردهای آینده.
- Degree Heuristic: انتخاب متغیری که بیشترین تعداد قوس را با سایر متغیرها دارد → با یک مقداردهی، بیشترین محدودیت روی دیگر متغیرها اعمال شود.
- Least Constraining Value: انتخاب مقداری که کمترین محدودیت را روی سایر متغیرها ایجاد کند → کاهش احتمال شکست و پسگرد.
نکته: ترکیب این هیوریستیکها باعث افزایش کارایی الگوریتم میشود.
جمعبندی
هوش مصنوعی CS50 s3
-
مسائل بهینهسازی و CSPها میتوانند به روشهای مختلفی حل شوند:
- جستجوی محلی (Local Search)
- برنامهریزی خطی (Linear Programming)
- ارضای محدودیتها (Constraint Satisfaction)
-
CSPها با استفاده از AC-3، Backtracking و هیوریستیکها میتوانند کارآمدتر حل شوند، ولی همیشه تضمینی برای حل مسئله وجود ندارد.
قابل به ذکر است نرم افزار Danix یک سیستم بر پایه هوش مصنوعی می باشد و از متدهای روز دنیا جهت آنالیز اطلاعات سازمان استفاده می کند شما می توانید اطلاعات بیشتر را در همین سایت مشاهده نمایید.
